【Jsoup】进阶使用
嗯,没错,今天来看一下 jsoup 的进阶使用姿势,我想大概是这样的 ↓

还是以抓取文章为主题,首先需要整理下 Jsoup 里面常用到的类。
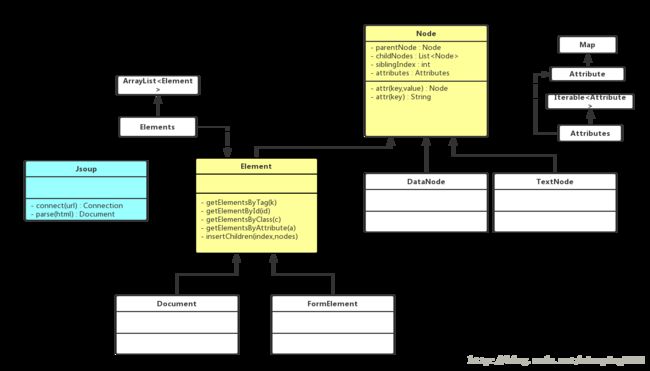
第一次画UML图,将就着看一下吧。在使用 Jsoup 的过程中最常使用到的对象(类) 有 Jsoup、Element、Elements (可以看到的是继承自ArrayList< Element> 的)、Document 对象是继承自Element 的、Node 等
从 url 获取 Document 的两种常用方式:
- Jsoup.connect(url).get()
- Jsoup.parse(new URL(url).openStream(), “utf-8”,url);
对于第一种方式获取到乱码的文档的时候可以采取第二种方式来指定字符集,第一种方式是 Jsoup 通过一定的规则来指定字符集。
Element 是实现了 Node 抽象类的,然后Document 是继承自Element 的。
Element 里面有N多的 getElementByXXX 的方法,这一系列的方法是用来获取文档中的特定元素(大致可以通过标签、id、class等获取到你想抓到的元素)
还有appenXXX 的方法,这些方法是用于往文档里追加元素的。
特别的,需要留意一个 insertChildren 方法,用于往标签里面塞元素的方法。
最后提供一个可以抓一些主流新闻媒体网站的小程序。
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.net.URL;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupUtil {
//过滤 url 可以后面继续补充
static String[] urlsAllow = {"news.qq.com","xw.qq.com","toutiao.com","m.toutiao.com","news.163.com",
"3g.163.com","58gem.com","chinajeweler.com"};
/**
* 根据Url 抓取文章信息
* @param url
* @return
*/
public static Object getArticleByUrl(String url){
String target = trimUrl(url);
boolean flag = false;
int index = -1;
ok:for (int i = 0; i < urlsAllow.length; i++) {
if(target.equals(urlsAllow[i])){
flag = true;
index = i;
break ok;
}
}
if(flag){
String res = "";
switch (index) {
case 0:
res =getTencentPC(url);
break;
case 1:
res =getTencentM(url);
break;
case 2:
case 3:
res = getToutiao(url);
break;
case 4:
res = getWangyiPC(url);
break;
case 5:
case 6:
res = getWangyiM(url);
break;
case 7:
res = getChinaJeweler(url);
break;
default:
break;
}
return res;
}
return false;
}
/**
* 整理url 如:http://news.qq.com/a/20170524/001189.htm -> news.qq.com
* @param url
* @return
*/
private static String trimUrl(String url) {
String[] ws = url.split("/");
if(ws.length <= 2) return url;
if("http:".equals(ws[0]) || "https:".equals(ws[0])){
return ws[2].replace("www.", "");
}
return ws[0].replace("www.", "");
}
public static void main(String[] args) {
// System.out.println(getArticleByUrl("http://news.qq.com/a/20170524/001189.htm")); //√
// System.out.println(getArticleByUrl("http://xw.qq.com/news/20170523066423/NEW2017052306642300")); //√
// System.out.println(getArticleByUrl("http://www.toutiao.com/a6423316033671758081/")); //√
// System.out.println(getArticleByUrl("https://m.toutiao.com/i6423317308084584961/")); //√
// System.out.println(getArticleByUrl("http://3g.163.com/all/article/CL6QENQG0001899N.html#offset=1")); //√
// System.out.println(getArticleByUrl("http://news.163.com/17/0524/12/CL6VEVFF000187VE.html"));//√
// System.out.println(getArticleByUrl("http://www.58gem.com/news/201705/17/detail203560.html")); //√
// System.out.println(getArticleByUrl("http://www.chinajeweler.com/zbss/zbds/renwu/34092.html")); //√
}
/**
* 腾讯新闻移动端处理方式
* @param url 过滤规则: xw.qq.com/news/
* @throws Throwable
*/
public static String getTencentM(String url){
Document doc = null;
try {
doc = Jsoup.parse(new URL(url).openStream(), "UTF-8", url);
} catch (IOException e) {
e.printStackTrace();
}
//需要追加的 script 段 ,如果源网页中没有 jquery 引入 则需要手动引入 这一段 script 仅仅对于腾讯新闻网这个站点有用
String script = "" +
""+
"";
//在得到的 document 对象的尾部追加这段script
doc.append(script);
//输出处理后的 html ,这里可以做文件输出处理,输出html 供外部访问
return doc.toString();
}
/**
* 获取腾讯Pc站
* @param url 过滤规则:news.qq.com/
* @throws Throwable
*/
public static String getTencentPC(String url){
Document doc = null;
try {
doc = Jsoup.parse(new URL(url).openStream(), "gb2312",url);
} catch (IOException e) {
e.printStackTrace();
}
Elements elements = new Elements();
Element elementsHD = doc.getElementsByClass("hd").first();
Element elementsBD = doc.getElementsByClass("bd").first();
elements.add(elementsHD);
elements.add(elementsBD);
String script = "" +
"" +
""+
"";
//在得到的 document 对象的尾部追加这段script
elements.append(script);
String html = "" +
""+
""+
""+
"