Scala中创建RDD的方式
1. 并行程序中的集合创建RDD ;

2.使用textFile方法,通过本地文件或HDFS创建RDD

1.Transformation算子:
Transformations类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey等。Transformations算子是延迟执行,也叫懒加载执行。
1):filter 过滤数据,返回true的数据会被留下;

2):map 将一个RDD中的每个数据项,通过map中的函数映射变为一个新的元素。特点:输入一条,输出一条数据。

3):flatmap 先map后flat。与map类似,每个输入项可以映射为0到多个输出项。特点:输入一条,输出多条数据;

4):mapPartitions mapPartitions 遍历的是每个分区中的数据,一个个分区的遍历,相对于map 一条条处理数据,性能比较高。

5):mapPartitionsWithIndex 想对于mapPartitions可以拿到RDD中的每个分区号,以及分区中的数据;

6):mapValues 作用于kv格式RDD,只能对v操作

7):flatMapValues 作用在K,V格式的RDD上,展开每一个key的value,返回多个k,v

8):groupBy 根据指定的规则分组

9):groupByKey 根据key 去将相同的key 对应的value合并在一起
10):sortBy 排序,参数中指定按照什么规则去排序,第二个参数 true/false 指定升序或者降序

11):sortByKey 默认按照key去排序,作用在K,V格式的RDD上

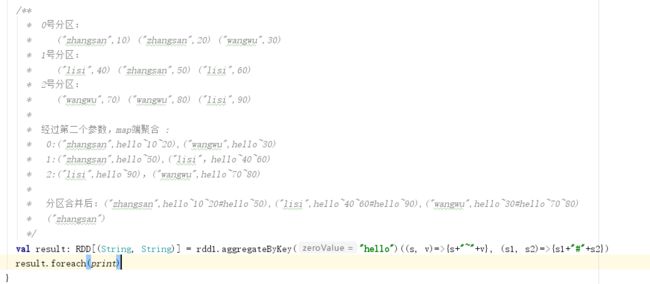
12):aggregateByKey 首先是给定RDD的每个分区一个初始值,RDD中每个分区内按照相同的key,结合初始值去合并,最后RDD之间相同的key 聚合。
13):reduceByKey 将相同的Key根据按照所给逻辑进行处理。

14):combinByKey 首先给RDD中每个分区中的每个key一个初始值,其次在RDD每个分区内部 相同的key聚合一次,再次在RDD不同的分区之间将相同的key结果聚合一次;

15):sample 参数sample(有无放回抽样,抽样的比例,种子),有种子和无种子的区别:有种子是只要针对数据源一样,都是指定相同的参数,那么每次抽样到的数据都是一样的;没有种子是针对同一个数据源,每次抽样都是随机抽样

16):intersection 取两个RDD的交集,两个RDD的类型要一致,结果RDD的分区数与父rdd多的一致;

17):substract 取RDD的差集subtract两个RDD的类型要一致,结果RDD的分区数与subtract算子前面的RDD的分区个数一致;

18):union 合并RDD ,两个RDD必须是同种类型,不必要是K,V格式的RDD 分区数等于两者之和;

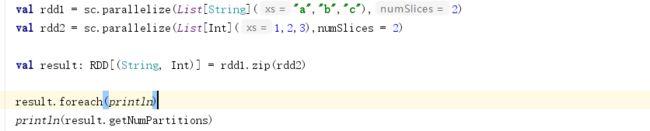
19):zip 将两个RDD 对应分区内的数据合成一个K,V格式的RDD,分区数要相同,每个分区中的元素必须相同,分区数不变
20):zipWithIndex 将RDD和数据下标压缩成一个K,V格式的RDD

21):join (K,V)格式的RDD和(K,V)格式的RDD按照key相同join 得到(K,(V,W))格式的数据,join会产生shuffle

22):rightOuterJoin (K,V)格式的RDD和(K,W)格式的RDD 使用rightOuterJoin结合是以右边的RDD出现的key为主,得到(K,(Option(V),W))

23):leftOuterJoin (K,V)格式的RDD和(K,W)格式的RDD 使用leftOuterJoin结合是以左边的RDD出现的key为主,得到(K,(V,Option(W)))

24):distinct 去重,有shuffle产生,内部实际是 map+reduceByKey+map实现

2.Action算子
Action类算子也是一类算子(函数)叫做行动算子Transformations类算子是延迟执行,Action类算子是触发执行。一个application应用程序中有几个Action类算子执行,就有几个job运行。
count 返回数据集中的元素数。会在结果计算完成后回收到Driver端。
take(n) 返回一个包含数据集前n个元素的集合。
first first=take(1),返回数据集中的第一个元素。
foreach 循环遍历数据集中的每个元素,运行相应的逻辑。
collect 将计算结果回收到Driver端。
3.控制算子
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。cache和persist都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系。
1) cache
默认将RDD的数据持久化到内存中。cache是懒执行。从代码中可以看出cache和MEMORY级别的persist()一样
2) persist:
可以指定持久化的级别。最常用的是MEMORY_ONLY和MEMORY_AND_DISK。”_2”表示有副本数。

3) cache和persist的注意事项:
1. cache和persist都是懒执行,必须有一个action类算子触发执行。
2. cache和persist算子的返回值可以赋值给一个变量,在其他job中直接使用这个变量就是使用持久化的数据了。持久化的单位是partition。
3. cache和persist算子后不能立即紧跟action算子。
4. cache和persist算子持久化的数据当applilcation执行完成之后会被清除。
4) checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系。checkpoint目录数据当application执行完之后不会被清除。
5) checkpoint 的执行原理:
1. 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
2. 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
3. Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
6) 优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步。