R2-CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images论文解读

一、研究动机
得益于卷积神经网络的迅速发展,目标检测作为计算视觉领域的基础任务也得到飞速发展,尤其是在日常场景(平视视角)中的数据集上表现喜人。但对于大尺度遥感图像的极小物体目标检测,其检测效果改进空间依旧很大。分析当前面临的挑战主要有以下几方面:
(1)输入图片尺寸过大(18 000×18 192和27 620×29 200),现有目标检测方法效率 低。
(2)复杂背景对检测任务带来干扰(沙漠、植被、城区等不同地表结构)。
(3)高空取景导致探测目标所占像素比极低(例如8-32像素),而这些极小目标成为 了检测效果低下的主要原因。基于以上三大挑战,本文提出了一种统一的带有自主增强性(self-reinforced)的神经网络R2-CNN:一种基于遥感图像的卷积神经网络,由作为骨干网络的Tinny-Net、分类器和探测器组成,使整个网络在计算效率和内存消耗方面都有所提升,除了对假正例具有鲁棒性,还具有检测微小目标的能力。大致流程如下图所示:
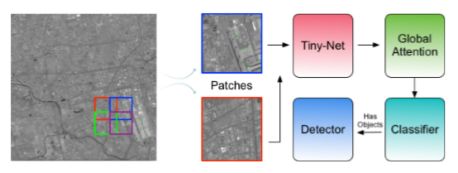
每张图片会先分块输入Tinny-Net进行特征提取,再经过注意力机制模块进行加权处理,然后经过一个二分类器来判断该块图片是否含有目标,得到有目标的图片块进行进一步的目标探测。
二、研究方法
整个R2-CNN的网络结构如下图所示:
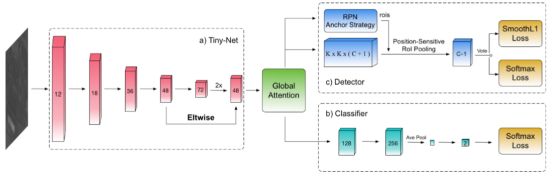
其中(a) Tiny-Net,这是一种轻量级的残差结构,能够从输入中高效地提取特征。(b)分类器,可以加快统一网络的速度,避免大量背景引起的干扰。©探测器,可准确定位目标物体。在端到端训练框架下,分类器和检测器相互增强。此外,全局注意力模块建立在Tiny-Net之上,用来抑制假正例的产生。
提出Tiny-Net基础网络在现有的VGG和ResNets等基础网络常常会带来以下几个问题:(1)这些基础网络都比较重量级,实时效率比较低下。(2)这些基础网络提取的特征针对图像分类任务,使得抽取的特征不太适用于目标检测。(3)训练参数过多导致训练很难从零开始达到收敛,尤其是在样本有限的情况下。(4)利用在常规视角中训练出来的模型作为与训练模型与我们的遥感图像视角下的图片讯在一个领域差异(domain gap),也就是预训练模型使用的数据集和遥感图像数据集分布存在很大差异。
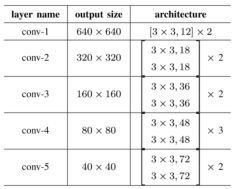
针对上述问题,该文提出了Tinny-Net作为整个模型的及网络来完成特征提取,具体结构可参见上表格。其中3x3是ResNet中的残差块(除了conv-1以外),为了确保对极小物体的探测性能没有在conv-1中进行下采样,因此使得参数量减少,这使得从零训练成为可能从而克服预训练模型和遥感图像数据集之间的分布差异。
采用Classifier过滤假正例
分类器模块的主要任务是判断分块后的图片块进行是否包含目标物体,在遥感数据集中有99%的图片块是不包含极小目标的,没有必要进行探测,因此通过该分类器可以筛掉大部分没有目标的图片块来提升极小目标的检测效果。除此之外,分类器在整个网络结构中还有一个重要的作用:遥感图像的复杂背景(比如沙漠和植被中随意的分布纹理,和城区中的高楼林立)使得假正例过多为后续的检测任务带来干扰和挑战,而分类器恰好会过滤一部分该复杂背景下无目标物体的图片块,从而为后续目标检测阶段排除干扰。该模块的结构就如图2-1中的(b)所示,只采用了两个“CONV-BN-RELU”的结构块,后面接了全局平均池化(Global average pooling)和一个1x1的卷积,最后用Softmax损失函数来指导分类器训练。
Global Attention扩大感受野
Global Attention模块使用一个特征金字塔,其中特征图会被池化成三种不同的尺寸(例如1x1,2x2和4x4),然后采用双线性插值恢复到与原始尺寸同大小,最终将所有特征进行融合。经过这种操作特的征图会拥有更丰富的上下文信息和更广阔的感受野(甚至遍布整张图片)。这种操作增强了探测器(detector)的性能。
Detector物体探测
极小目标检测的挑战主要有两个方面:(1)最小的锚点(anchor)步长依旧很大(例如16像素),导致小物体的错过。(2)下采样池化过程会导致极小物体的特征丢失。(3)物体的尺寸变化是连续的,而锚点与设定的尺寸是离散的。当某目标的尺寸接近于设定锚点大小时,该物体附近会产生较多锚点,从而更容易被探测出来。然而极小目标尺寸大小往往与锚点尺寸相差较大,因而附近产生的锚点也较少,从而降低了探测性能。为了解决上述问题,我们采用了两种方式:(1)使用k-means将锚点划分成k个簇,将这k个聚类中心作为锚点的预设值。(2)通过扩大特征图尺寸达到减小锚点步长的目的,先下采样抽取特征,再回复到原尺寸,在原尺寸特征图上采用与下采样特征图相同的补偿就相当于缩小了步长。结构如下图所示。
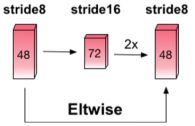
(3)使用位置敏感性RoI pooling(position sensitive RoI pooling)替换RoI poling,实现了平移不变性,该方式已经在R-FCN中出现。
损失函数
![]()
整个loss函数由三部分相加而得,分别是二分类loss(有无目标物)、多分类loss(RoI属于哪个类别)和位置偏移量loss(RoI和最近的ground truth的偏移量),前两者的loss是softmax loss,最后一个是smooth-L1 loss。
三、实验结果
实验数据由1169张 GF-1 图片和318张GF-2图片组成,他们分别是18000×18192和27620×29200分辨率. 在此基础上,实验将它们裁剪成了38472张 640×640图片块。分别做了detecter和classifier联合、detecter和classifier不联合和只使用detector三组对比试验,其实验结果如下两表所示,从而得出了把detector和classifier联合将起到互相促进的作用,从而提升精度和召回率。
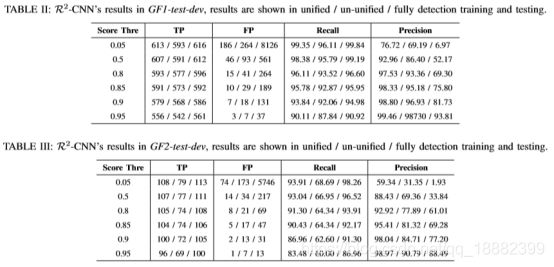
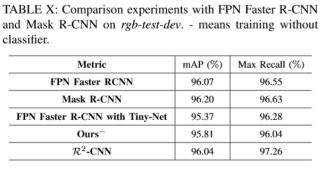
除此之外还和Faster RCNN以及Mask R-CNN进行了对比实验,虽然mAP值不分上下,但recall数值只有在以Tinny-Net作为基础网络、detector和classifier联合的情况下(也就是本文提出的方法)才会达到最高。

四、方法总结
R2-CNN为了缓解当今主流基础网络厚重且不适应目标检测任务的问题,提出了Tinny-Net作为基础网络。Tinny-Net轻量且针对缩小后续锚点步长做了特征图扩充操作(最后两层),使得产生的建议框更加接近小目标的真实值,为后续矩形框的回归降低了难度从而提升定位精度。同时,因为在图片进入网络之前会切分成小块,大尺度的小物体图像切割之后产生大量不包含小物体的图片块,为了节省探测时间以及提升探测精度采用二分类器将这些无目标图片块过滤掉。当然,针对目标的渺小性这个最关键的问题,R2-CNN从扩大感受野的角度出发,在基础网络提取完特征之后在池化过程中采取多尺度策略总而达到多尺度融合来扩大感受野的效果。