前言:在Hadoop 1.x版本,HDFS集群的NameNode一直存在单点故障问题:集群只存在一个NameNode节点,它维护了HDFS所有的元数据信息,当该节点所在服务器宕机或者服务不可用,整个HDFS集群都将处于不可用状态,极大限制了HDFS在生产环境的应用场景。直到Hadoop 2.0版本才提出了高可用 (High Availability, HA) 解决方案,并且经过多个版本的迭代更新,已经广泛应用于生产环境。
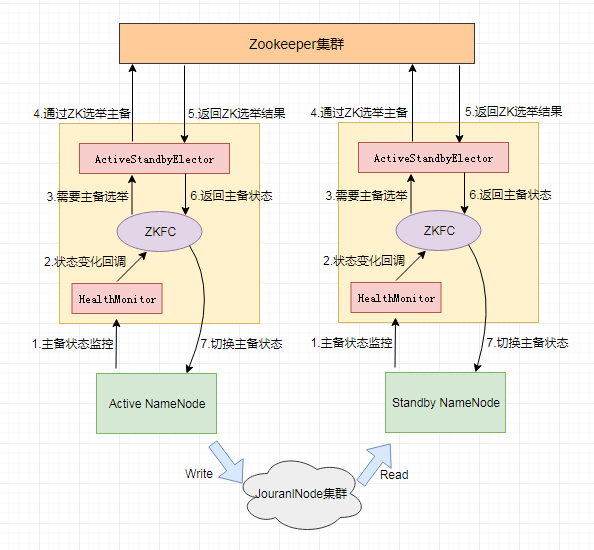
解决方案:在同一个HDFS集群,运行两个互为主备的NameNode节点。一台为主Namenode节点,处于Active状态,一台为备NameNode节点,处于Standby状态。其中只有Active NameNode对外提供读写服务,Standby NameNode会根据Active NameNode的状态变化,在必要时切换成Active状态。
【NameNode HA架构图】
ZKFC
ZKFC即ZKFailoverController,作为独立进程存在,负责控制NameNode的主备切换,ZKFC会监测NameNode的健康状况,当发现Active NameNode出现异常时会通过Zookeeper集群进行一次主备选举,完成Active和Standby状态的切换;
HealthMonitor
定时调用NameNode的HAServiceProtocol RPC接口(monitorHealth和getServiceStatus),监控NameNode的健康状态并向ZKFC反馈;
ActiveStandbyElector
接收ZKFC的选举请求,通过Zookeeper自动完成主备选举,选举完成后回调ZKFC的主备切换方法对NameNode进行Active和Standby状态的切换;
JouranlNode集群
共享存储系统,负责存储HDFS的元数据,Active NameNode(写入)和Standby NameNode(读取)通过共享存储系统实现元数据同步,在主备切换过程中,新的Active NameNode必须确保元数据同步完成才能对外提供服务;
【ZKFC工作原理】
ZKFailoverController在启动时同时会初始化HealthMonitor和ActiveStandbyElector服务,同时也会向HealthMonitor和ActiveStandbyElector注册相应的回调方法:
private int doRun(String[] args) throws Exception {
try {
initZK(); //初始化ActiveStandbyElector服务
} catch (KeeperException ke) {
LOG.error("Unable to start failover controller. Unable to connect "
+ "to ZooKeeper quorum at " + zkQuorum + ". Please check the "
+ "configured value for " + ZK_QUORUM_KEY + " and ensure that "
+ "ZooKeeper is running.", ke);
return ERR_CODE_NO_ZK;
}
......
try {
initRPC();
initHM(); //初始化HealthMonitor服务
startRPC();
mainLoop();
} catch (Exception e) {
LOG.error("The failover controller encounters runtime error: ", e);
throw e;
} finally {
rpcServer.stopAndJoin();
elector.quitElection(true);
healthMonitor.shutdown();
healthMonitor.join();
}
return 0;
}
一. 状态监控
HealthMonitor检测NameNode的两类状态,HealthMonitor.State和HealthMonitor.HAServiceStatus。在程序上启动一个线程循环调用NameNode的HAServiceProtocol RPC接口的方法来检测NameNode 的状态,并将状态的变化通过回调的方式来通知ZKFailoverController。
HealthMonitor.State包括:
INITIALIZING:The health monitor is still starting up;
SERVICE_NOT_RESPONDING:The service is not responding to health check RPCs;
SERVICE_HEALTHY:The service is connected and healthy;
SERVICE_UNHEALTHY:The service is running but unhealthy;
HEALTH_MONITOR_FAILED:The health monitor itself failed unrecoverably and can no longer provide accurate information;
HealthMonitor.HAServiceStatus包括:
INITIALIZING:NameNode正在启动中;
ACTIVE:当前NameNode角色为Active;
STANDBY:当前NameNode角色为Standby;
STOPPING:NameNode已经停止运行;
当HealthMonitor检测到NameNode的健康状态或角色状态发生变化时,ZKFC会根据状态的变化决定是否需要进行主备选举。
二. 主备选举
HealthMonitor.State状态变化导致的不同后续措施:
/**
* Check the current state of the service, and join the election
* if it should be in the election.
*/
private void recheckElectability() {
// Maintain lock ordering of elector -> ZKFC
synchronized (elector) {
synchronized (this) {
boolean healthy = lastHealthState == State.SERVICE_HEALTHY;
long remainingDelay = delayJoiningUntilNanotime - System.nanoTime();
if (remainingDelay > 0) {
if (healthy) {
LOG.info("Would have joined master election, but this node is " +
"prohibited from doing so for " +
TimeUnit.NANOSECONDS.toMillis(remainingDelay) + " more ms");
}
scheduleRecheck(remainingDelay);
return;
}
switch (lastHealthState) {
case SERVICE_HEALTHY:
//调用ActiveStandbyElector的joinElection发起一次主备选举;
elector.joinElection(targetToData(localTarget));
if (quitElectionOnBadState) {
quitElectionOnBadState = false;
}
break;
case INITIALIZING:
LOG.info("Ensuring that " + localTarget + " does not " +
"participate in active master election");
//调用ActiveStandbyElector的quitElection(false)从ZK上删除已经建立的临时节点退出主备选举,不进行隔离;
elector.quitElection(false);
serviceState = HAServiceState.INITIALIZING;
break;
case SERVICE_UNHEALTHY:
case SERVICE_NOT_RESPONDING:
LOG.info("Quitting master election for " + localTarget +
" and marking that fencing is necessary");
//调用ActiveStandbyElector的quitElection(true)从ZK上删除已经建立的临时节点退出主备选举,并进行隔离;
elector.quitElection(true);
serviceState = HAServiceState.INITIALIZING;
break;
case HEALTH_MONITOR_FAILED:
fatalError("Health monitor failed!");
break;
default:
throw new IllegalArgumentException("Unhandled state:"
+ lastHealthState);
}
}
}
}
HAServiceStatus在状态检测之中仅起辅助的作用,当HAServiceStatus发生变化时,ZKFC会判断NameNode返回的HAServiceStatus与ZKFC所期望的是否相同,如果不相同,ZKFC会调用ActiveStandbyElector的quitElection方法删除当前已经在ZK上建立的临时节点退出主备选举。
void verifyChangedServiceState(HAServiceState changedState) {
synchronized (elector) {
synchronized (this) {
if (serviceState == HAServiceState.INITIALIZING) {
if (quitElectionOnBadState) {
LOG.debug("rechecking for electability from bad state");
recheckElectability();
}
return;
}
if (changedState == serviceState) {
serviceStateMismatchCount = 0;
return;
}
if (serviceStateMismatchCount == 0) {
// recheck one more time. As this might be due to parallel transition.
serviceStateMismatchCount++;
return;
}
// quit the election as the expected state and reported state
// mismatches.
LOG.error("Local service " + localTarget
+ " has changed the serviceState to " + changedState
+ ". Expected was " + serviceState
+ ". Quitting election marking fencing necessary.");
delayJoiningUntilNanotime = System.nanoTime()
+ TimeUnit.MILLISECONDS.toNanos(1000);
elector.quitElection(true);
quitElectionOnBadState = true;
serviceStateMismatchCount = 0;
serviceState = HAServiceState.INITIALIZING;
}
}
}
三. 主备选举
ZKFC通过ActiveStandbyElector的joinElection方法发起NameNode的主备选举,这个过程通过Zookeeper的写一致性和临时节点机制实现:
a. 当发起一次主备选举时,Zookeeper会尝试创建临时节点/hadoop-ha/${dfs.nameservices}/ActiveStandbyElectorLock,Zookeeper的写一致性保证最终只会有一个ActiveStandbyElector创建成功,创建成功的 ActiveStandbyElector对应的NameNode就会成为主NameNode,ActiveStandbyElector回调ZKFC的方法将对应的NameNode切换为Active状态。而创建失败的ActiveStandbyElector对应的NameNode成为备NameNode,ActiveStandbyElector回调ZKFC的方法将对应的NameNode切换为Standby状态;
private void joinElectionInternal() {
Preconditions.checkState(appData != null,
"trying to join election without any app data");
if (zkClient == null) {
if (!reEstablishSession()) {
fatalError("Failed to reEstablish connection with ZooKeeper");
return;
}
}
createRetryCount = 0;
wantToBeInElection = true;
createLockNodeAsync(); //创建临时节点
}
b.不管是否选举成功,所有ActiveStandbyElector都会向Zookeeper注册一个Watcher来监听这个节点的状态变化事件;
private void monitorLockNodeAsync() {
if (monitorLockNodePending && monitorLockNodeClient == zkClient) {
LOG.info("Ignore duplicate monitor lock-node request.");
return;
}
monitorLockNodePending = true;
monitorLockNodeClient = zkClient;
zkClient.exists(zkLockFilePath, watcher, this, zkClient); //向zookeeper注册Watcher监听器
}
c.如果Active NameNode对应的HealthMonitor检测到NameNode状态异常时,ZKFC会删除在Zookeeper上创建的临时节点ActiveStandbyElectorLock,这样处于Standby NameNode的ActiveStandbyElector注册的Watcher就会收到这个节点的 NodeDeleted事件。收到这个事件后,会马上再次创建ActiveStandbyElectorLock,如果创建成功,则Standby NameNode被选举为Active NameNode。
【防止脑裂】
在分布式系统中脑裂又称为双主现象,由于Zookeeper的“假死”,长时间的垃圾回收或其它原因都可能导致双Active NameNode现象,此时两个NameNode都可以对外提供服务,无法保证数据一致性。对于生产环境,这种情况的出现是毁灭性的,必须通过自带的隔离(Fencing)机制预防这种现象的出现。
ActiveStandbyElector为了实现fencing隔离机制,在成功创建hadoop-ha/dfs.nameservices/ActiveStandbyElectorLock临时节点后,会创建另外一个/hadoop−ha/{dfs.nameservices}/ActiveBreadCrumb持久节点,这个持久节点保存了Active NameNode的地址信息。当Active NameNode在正常的状态下断开Zookeeper Session (注意由于/hadoop-ha/dfs.nameservices/ActiveStandbyElectorLock是临时节点,也会随之删除),会一起删除持久节点/hadoop−ha/{dfs.nameservices}/ActiveBreadCrumb。但是如果ActiveStandbyElector在异常的状态下关闭Zookeeper Session,那么由于/hadoop-ha/${dfs.nameservices}/ActiveBreadCrumb是持久节点,会一直保留下来。当另一个NameNode(standy => active)选主成功之后,会注意到上一个Active NameNode遗留下来的ActiveBreadCrumb节点,从而会回调ZKFailoverController的方法对旧的Active NameNode进行fencing。
① 首先ZKFC会尝试调用旧Active NameNode的HAServiceProtocol RPC接口的transitionToStandby方法,看能否将状态切换为Standby;
② 如果调用transitionToStandby方法切换状态失败,那么就需要执行Hadoop自带的隔离措施,Hadoop目前主要提供两种隔离措施:
sshfence:SSH to the Active NameNode and kill the process;
shellfence:run an arbitrary shell command to fence the Active NameNode;
只有在成功地执行完成fencing之后,选主成功的ActiveStandbyElector才会回调ZKFC的becomeActive方法将对应的NameNode切换为Active,开始对外提供服务。
private boolean becomeActive() {
assert wantToBeInElection;
if (state == State.ACTIVE) {
// already active
return true;
}
try {
Stat oldBreadcrumbStat = fenceOldActive(); //隔离old active NameNode
writeBreadCrumbNode(oldBreadcrumbStat); //更新ActiveBreadCrumb保存的active NameNode地址信息
if (LOG.isDebugEnabled()) {
LOG.debug("Becoming active for " + this);
}
appClient.becomeActive(); //选主成功的ActiveStandbyElector切换NameNode状态
state = State.ACTIVE;
return true;
} catch (Exception e) {
LOG.warn("Exception handling the winning of election", e);
// Caller will handle quitting and rejoining the election.
return false;
}
}
博客主页:https://www.jianshu.com/u/e97bb429f278