【5分钟力扣】26.删除排序数组中的重复值(python3实现)
文章目录
- 一、前言
- 二、题目
- 三、 反向遍历删除法
- 3.1 解题思路
- 3.2 代码实例
- 四、快慢指针法
- 4.1 解题思路
- 4.2 代码实例
一、前言
把现在的工作做好,才能幻想将来的事情,专注于眼前的事情,对于尚未发生的事情而陷入无休止的忧虑之中,对事情毫无帮助,反而为自己凭添了烦恼。
每天五分钟,看懂一道简单、中等难度的算法题,尽可能将复杂的题讲清楚。
疯狂学习python中,2020-07-19更新

二、题目
给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
示例 1:
给定数组 nums = [1,1,2],
函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。
你不需要考虑数组中超出新长度后面的元素。
示例 2:
给定 nums = [0,0,1,1,1,2,2,3,3,4],
函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。
你不需要考虑数组中超出新长度后面的元素。
提示:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 int len = removeDuplicates(nums); // 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
三、 反向遍历删除法
3.1 解题思路
简单思路:
1、遍历nums,将将相邻的前后两位进行比较,相等删除重复值,不相等继续遍历,直到遍历完成。
出现问题:
1、遍历法思路没问题,但是题目要求在原地删除修改,这也意味着遍历时候如果进行删除会报错,原因是在删除list中的元素后,list的实际长度变小了,但是循环次数没有减少,依然按照原来list的长度进行遍历,所以会造成索引溢出。
解决思路:
1、反向遍历删除法,因为从数组尾部删除元素,不会影响到其他元素。
3.2 代码实例
from typing import List
nums = [0,0,1,1,1,2,2,3,3,4]
# 倒序法
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
if len(nums) <= 0:
return 0
for i in range(len(nums)-1, 0, -1):
if nums[i] == nums[i-1]:
nums.pop(i)
return len(nums)
if __name__ == '__main__':
result = Solution()
result.removeDuplicates(nums)
四、快慢指针法
4.1 解题思路
分析题意:
由题意可知,列表是有序的,而且需要返回移除后新元素的长度。那么我们得到如下几个关键信息:
1、重复元素必然相邻
2、只需要返回有序且不重复列表长度。
3、你不需要考虑数组中超出新长度后面的元素。
简单思路:
1、结合原地算法的要求,我们可以将重复的元素移动到数组右侧,然后返回不重复且有序的元素即数组左侧长度。切片的时间复杂度为O(n),所有我们可以通过快慢指针来进行对比赋值,通过指针移动步数就可以知道不重复且有序数组的长度。
参考图片:
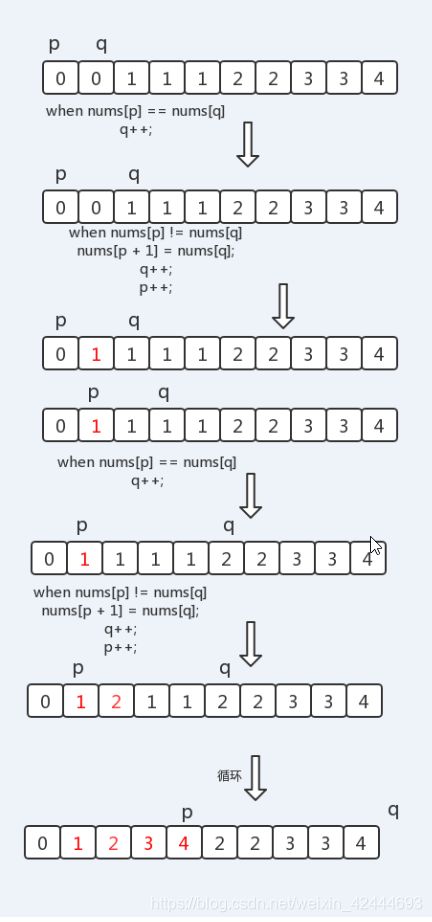
参考来源:https://mp.weixin.qq.com/s/JcsBahMXtwX2I7QkO6OTJA
4.2 代码实例
class Solution:
def removeDuplicates(self, nums: List[int]) -> int:
slow = 0 # 慢指针
for i in range(1, len(nums)):
if nums[i] != nums[slow]:
slow += 1
nums[slow] = nums[i]
print(slow+1)
return slow+1
if __name__ == '__main__':
result = Solution()
result.removeDuplicates(nums)