- Python 常用内建模块-HTMLParser
赔罪
Python系统学习python开发语言
目录HTMLParser小结练习HTMLParser如果我们要编写一个搜索引擎,第一步是用爬虫把目标网站的页面抓下来,第二步就是解析该HTML页面,看看里面的内容到底是新闻、图片还是视频。假设第一步已经完成了,第二步应该如何解析HTML呢?HTML本质上是XML的子集,但是HTML的语法没有XML那么严格,所以不能用标准的DOM或SAX来解析HTML。好在Python提供了HTMLParser来非
- 探秘知乎数据抓取神器 —— zhihu-spider
丁慧湘Gwynne
探秘知乎数据抓取神器——zhihu-spider项目地址:https://gitcode.com/gh_mirrors/zh/zhihu-spider在知识的海洋中畅游,每一份数据都可能成为智慧的火花。今天,我们来一起探索一个专为知乎设计的数据爬虫工具——zhihu-spider,它是由计算机科学研究生MorganZhang精心打造的开源宝藏。项目介绍zhihu-spider,正如其名,是一个针对
- Python 爬虫实战:从知乎盐选专栏,爬取优质内容付费数据
西攻城狮北
python爬虫开发语言实战案例知乎
目录一、前言二、准备篇2.1确定目标2.2工具与库2.3法律与道德声明三、实战篇3.1分析知乎盐选专栏页面3.2模拟登录3.3获取文章列表3.4爬取更多文章数据3.5数据存储四、分析篇4.1数据清洗4.2热门文章分析4.3收藏数分析4.4评论数分析五、总结与展望六、注意事项一、前言知乎盐选专栏作为知乎平台上的优质内容付费板块,汇聚了众多创作者的高质量文章。了解这些文章的付费数据,如点赞数、收藏数、
- python爬虫Redis数据库
Æther_9
Python爬虫零基础入门数据库python爬虫
Redis数据库Redis简介Redis是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。Redis与其他key-value缓存产品有以下三个特点:Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。redis:半持
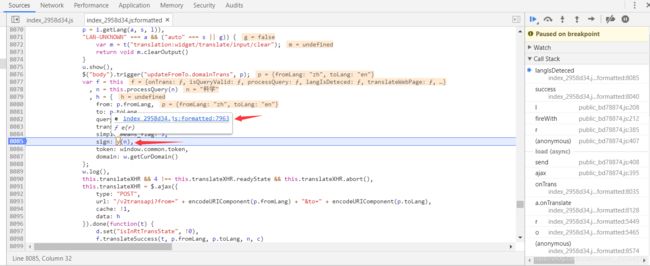
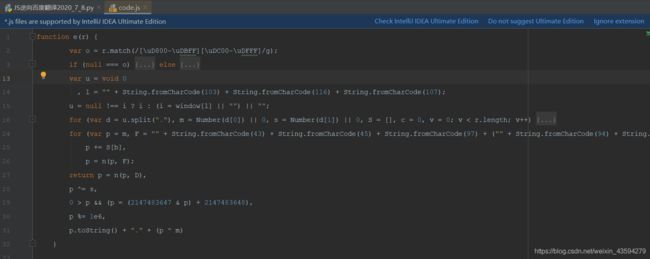
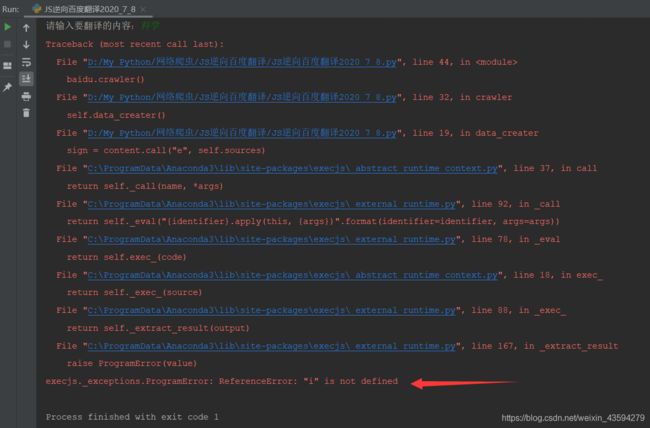
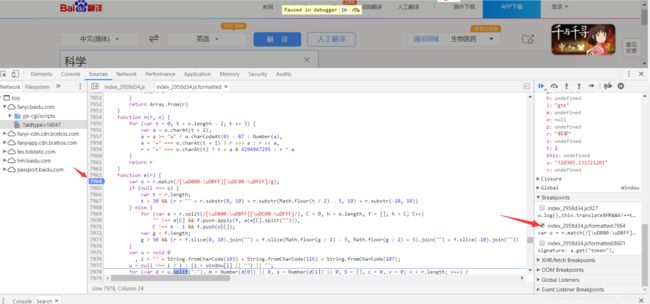
- JavaScript反爬技术解析与应对
不做超级小白
web逆向知识碎片web前端javascript开发语言ecmascript
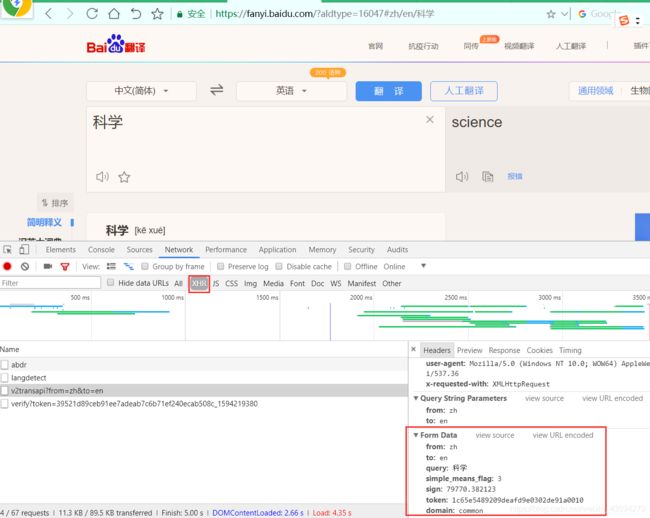
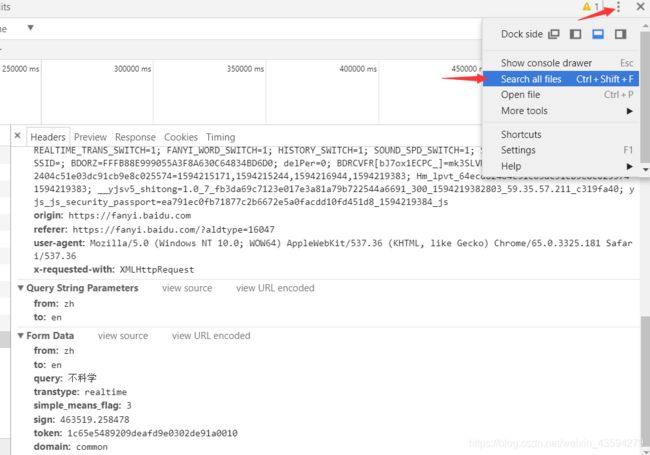
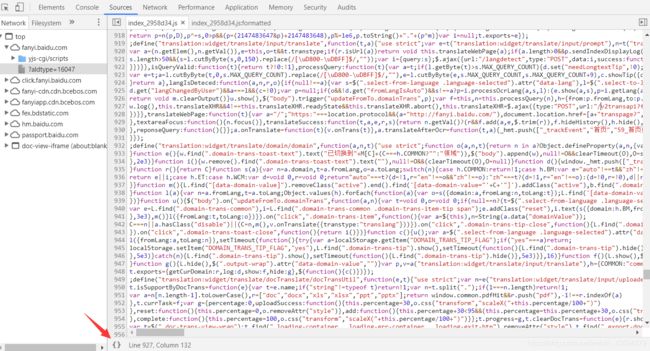
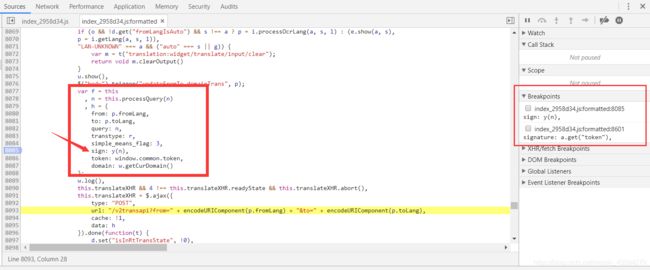
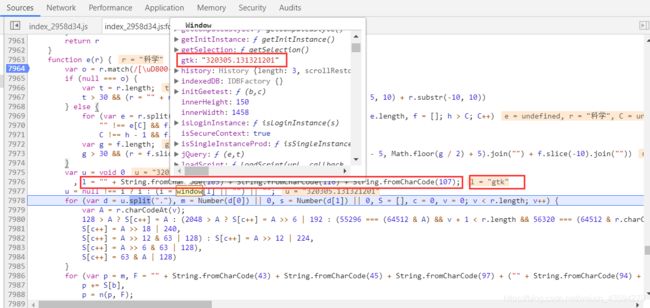
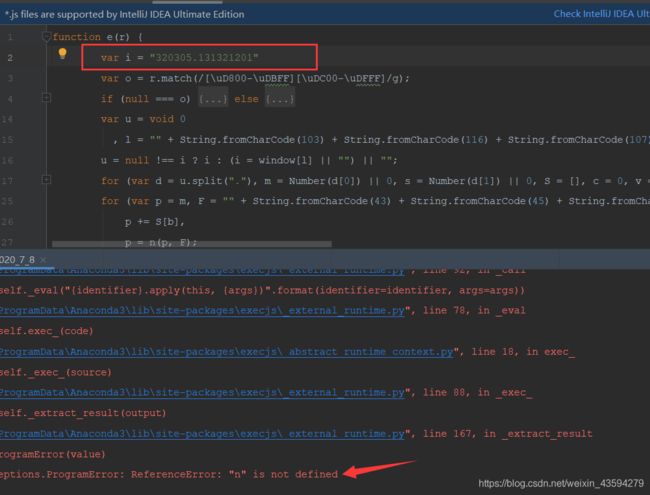
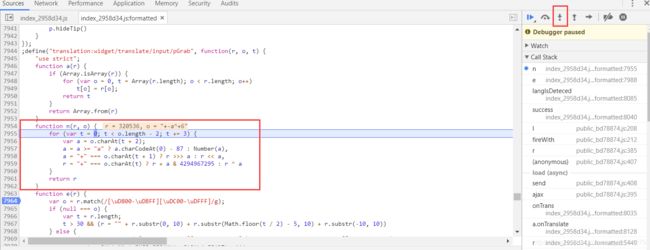
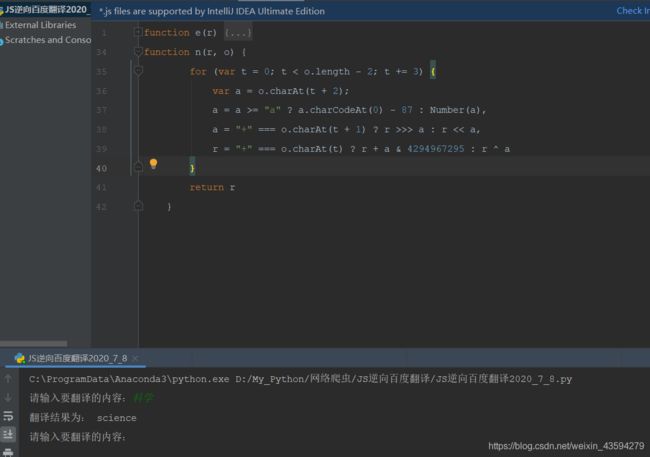
JavaScript反爬技术解析与应对前言在当今Web爬虫与数据抓取的生态环境中,网站运营方日益关注数据安全与隐私保护,因此逐步采用多种反爬技术来限制非授权访问。本文从JavaScript角度出发,深入剖析主流反爬策略的技术原理,并探讨相应的绕过方案,以期为研究者和开发者提供系统性的理解与实践指导。1.JavaScript反爬技术概述1.1右键禁用与开发者工具防护部分网站采用JavaScript拦
- Scrapy 入门教程
zru_9602
爬虫scrapy
Scrapy入门教程Scrapy是一个用于爬取网站数据的Python框架,功能强大且易于扩展。本文将介绍Scrapy的基本概念、安装方法、使用示例,并展示如何编写一个基本的爬虫。1.什么是Scrapy?Scrapy是一个开源的、用于爬取网站数据的框架,主要特点包括:高效、异步的爬取机制强大的XPath和CSS选择器解析能力内置中间件,支持代理、去重等功能易于扩展,适用于各种爬虫需求2.安装Scra
- 网络安全爬虫全解析
Hacker_LaoYi
爬虫web安全网络
1.网络爬虫的认识网络爬虫是自动从互联网定向或不定向地采集信息地一种程序工具。网络爬虫分为很多类别,常见的有批量型网络爬虫、增量型网络爬虫(通用爬虫)、垂直网络爬虫(聚焦爬虫)。2.网络爬虫的工作原理通用爬虫:首先给定初始URL,爬虫会自动获取这个URL上的所有URL并将已经在爬取的地址存放在已爬取列表中。将新的URL放在队列并依次读取新的URL,依次判读是否满足所设置的停止获取的条件。聚焦爬虫:
- 用Python爬虫获取AliExpress商品信息:item_search API接口实战指南
JelenaAPI小小爬虫
PythonAPIpython爬虫开发语言
引言在全球化电商的浪潮中,数据的力量不容小觑。对于电商分析师、市场研究者以及在线商家而言,能够快速获取商品信息是至关重要的。AliExpress作为全球知名的跨境电商平台,提供了丰富的商品数据。本文将介绍如何使用Python爬虫结合item_searchAPI接口,按关键字搜索并获取AliExpress上的商品信息。一、为什么选择Python爬虫Python因其简洁的语法和强大的库支持,成为编写爬
- 轻松帮你搞清楚Python爬虫数据可视化的流程
liuhaoran___
python
Python爬虫数据可视化的流程主要是通过网络爬取所需的数据,并利用相关的库将数据分析结果以图形化的方式展示出来,帮助用户更直观地理解数据背后的信息。Python爬虫+数据可视化步骤1.获取目标网站的数据使用`requests`或者`selenium`库从网页上抓取信息。对于动态加载内容的页面可以考虑结合JavaScript渲染引擎。2.解析HTML内容提取有用信息常见工具如BeautifulSo
- Python 爬虫实战:社交媒体品牌反馈数据抓取与舆情分析
西攻城狮北
python爬虫媒体
一、引言在当今数字化时代,社交媒体已成为公众表达意见、分享信息的重要渠道。品牌的声誉和市场表现往往受到消费者在社交平台上的反馈和评价的影响,因此品牌舆情分析变得至关重要。本文将介绍如何使用爬虫技术爬取社交媒体上的品牌反馈数据,并通过数据分析技术,分析品牌的舆情动态。二、环境准备在开始之前,确保你的开发环境已经安装了以下必要的Python库:requests:用于发送HTTP请求。beautiful
- 使用 Selenium 控制现有 Edge 窗口以规避爬虫检测
秋叶原の黑猫
数据库
在网络爬虫开发中,网站的防爬机制常常会检测自动化工具(如Selenium)启动的浏览器实例。为了绕过这种检测,一种有效的方法是利用Selenium连接到手动打开的现有浏览器窗口,而不是每次都启动一个新的实例。本文将详细介绍如何使用Selenium控制现有的MicrosoftEdge浏览器窗口,并结合代码示例展示实现过程。1.背景介绍:为什么需要控制现有窗口?传统的Selenium脚本会通过WebD
- GitHub项目推荐--基于LLM的开源爬虫项目
惟贤箬溪
穷玩Aigithub爬虫
以下是一些基于大语言模型(LLM,LargeLanguageModel)的开源爬虫项目,它们结合了自然语言处理(NLP)技术与爬虫的功能,能在一定程度上提升爬取的智能化和精度。这些项目可以用于自动化抓取、内容提取、数据分析等任务。1.GPT-3WebScraper简介:这是一个基于OpenAIGPT-3模型的网页抓取工具,利用GPT-3的自然语言理解能力来生成有用的爬虫策略、处理网页内容并提取有价
- 使用Java爬虫按关键字搜索1688商品
小爬虫程序猿
java爬虫开发语言
在电商领域,获取1688商品信息对于市场分析、选品上架、库存管理和价格策略制定等方面至关重要。1688作为国内领先的B2B电商平台,提供了丰富的商品数据。虽然1688开放平台提供了官方API来获取商品信息,但有时使用爬虫技术来抓取数据也是一种有效的手段。本文将介绍如何利用Java按关键字搜索1688商品,并提供详细的代码示例。一、准备工作1.Java开发环境确保你的Java开发环境已经安装了以下必
- python大赛对名_用100行Python爬虫代码抓取公开的足球数据玩(一)
司马各
python大赛对名
在《用Python模拟2018世界杯夺冠之路》一文中,我选择从公开的足球网站用爬虫抓取数据,从而建模并模拟比赛,但是略过了爬虫的实施细节。虽然爬虫并不难做,但希望可以让更多感兴趣的朋友自己动手抓数据下来玩,提供便利,今天就把我抓取球探网的方法和Python源码拿出来分享给大家,不超过100行代码。希望球友们能快速get爬虫的技能。#-*-coding:utf-8-*-from__future__i
- wooyun知识库爬虫(自动整理保存为pdf)
大囚长
编程人生黑客帝国spiderpython
#!C:\Python27\python.exe#coding=utf8importosimportpdfkitimporturllib2frombs4importBeautifulSoupfrommultiprocessingimportPoolimportsocketsocket.setdefaulttimeout(60)importsysreload(sys)sys.setdefaulten
- Python - 爬虫;爬虫-网页抓取数据-工具curl
MinggeQingchun
Python爬虫curlpython
一、爬虫关于爬虫的合法性通用爬虫限制:Robots协议【约定协议robots.txt】robots协议:协议指明通用爬虫可以爬取网页的权限robots协议是一种约定,一般是大型公司的程序或者搜索引擎等遵守几乎每一个网站都有一个名为robots.txt的文档,当然也有部分网站没有设定robots.txt。对于没有设定robots.txt的网站可以通过网络爬虫获取没有口令加密的数据,也就是该网站所有页
- Python爬虫:数据抓取工具及类库详解
2401_84692751
程序员python爬虫开发语言
wget也是一个利用URL语法在命令行环境下进行文件传输的工具,其基本用法为wget[URL地址][参数],如:wgethttps://www.baidu.com其常用参数如下:下面例子演示如何使用wget镜像一个网站到本地并启动:使用wget--mirror命令将整个网站的镜像下载到本地wget--mirror-p--convert-linkshttp://www.httpbin.org切换到下
- 数据分析实战:Shopee虾皮网销售数据分析
harvensage
数据分析数据分析数据挖掘
一、背景目标Shopee(虾皮网)是东南亚电商平台,覆盖新加坡、马来西亚、菲律宾、泰国、越南、巴西、墨西哥、哥伦比亚、智利等十余个市场,触达超10亿消费者!2023年Shopee总订单量达82亿,23年Q4总订单数同比增长46%!分析数据样本来自某爬虫系统爬取的Shopee网从2023年4月至2023年5月期间特定产品的销售数据。任务要求任务要求:从数据中获取在2023年5月上市的产品。使用问题1
- 批量获取虾皮shopee商品详情信息 爬虫
a6229203
爬虫数据库前端
每天100万详情联系736131417v:IpAnt_Proxy在当今的电子商务环境中,数据是至关重要的。对于电商平台的商家和开发者来说,获取商品详情信息是他们日常工作的关键部分。虾皮Shopee作为东南亚最大的电商平台,其商品信息对于商家和开发者来说具有极高的价值。本文将分享如何通过API批量获取虾皮Shopee的商品详情信息,并提供测试代码,让您轻松上手。一、了解虾皮ShopeeAPI虾皮Sh
- PHP 爬虫实战:爬取淘宝商品详情数据
EcomDataMiner
php爬虫开发语言
随着互联网技术的发展,数据爬取越来越成为了数据分析、机器学习等领域的重要前置技能。而在这其中,爬虫技术更是不可或缺。php作为一门广泛使用的后端编程语言,其在爬虫领域同样也有着广泛应用和优势。本文将以爬取斗鱼直播数据为例,介绍php爬虫的实战应用。准备工作在开始爬虫之前,我们需要做一些准备工作。首先,需要搭建一个本地服务器环境,推荐使用WAMP、XAMPP等集成化工具,方便部署PHP环境。其次,我
- 如何使用PHP爬虫根据关键词获取Shopee商品列表?
数据小爬虫@
php爬虫android
在跨境电商领域,Shopee作为东南亚及中国台湾地区领先的电商平台,拥有海量的商品信息。无论是进行市场调研、数据分析,还是寻找热门商品,根据关键词获取Shopee商品列表都是一项极具价值的任务。然而,手动浏览和整理这些信息显然是低效且容易出错的。幸运的是,通过编写PHP爬虫程序,我们可以高效地完成这一任务。本文将详细介绍如何利用PHP爬虫根据关键词获取Shopee商品列表,并提供完整的代码示例。一
- 如何使用PHP爬虫获取Shopee(虾皮)商品详情?
数据小爬虫@
php爬虫开发语言
在跨境电商领域,Shopee(虾皮)作为东南亚及中国台湾地区领先的电商平台,拥有海量的商品信息。无论是进行市场调研、数据分析,还是寻找热门商品,获取Shopee商品详情都是一项极具价值的任务。然而,手动浏览和整理这些信息显然是低效且容易出错的。幸运的是,通过编写PHP爬虫程序,我们可以高效地完成这一任务。本文将详细介绍如何利用PHP爬虫获取Shopee商品详情,并提供完整的代码示例。一、为什么选择
- 从零至巅:逆向爬虫之道 0_0
蓝花楹下
逆向爬虫爬虫
逆向爬虫-涅槃吾本一介凡鸟,栖于尘世,碌碌无为,浑浑噩噩,如沧海一粟,渺小而无足轻重。然,虽为小雀,心亦怀鸿鹄之志,欲挥羽向天,如凤凰般,翱翔九天,俯瞰苍茫大地。奈何羽翼未丰,学识浅薄,常感力不从心,困于樊笼,不得展翅高飞。然,吾深知,学如逆水行舟,不进则退。故,今执笔为记,以明志,以自勉。愿以此笔记为舟,载吾渡学海,以勤为桨,以思为帆,逐浪前行,终至彼岸。虽前路漫漫,荆棘丛生,然吾心坚定,誓不负
- Python 网络爬虫:从入门到实践
一ge科研小菜菜
编程语言Pythonpython
个人主页:一ge科研小菜鸡-CSDN博客期待您的关注网络爬虫是一种自动化的程序,用于从互联网上抓取数据。Python以其强大的库和简单的语法,是开发网络爬虫的绝佳选择。本文将详细介绍Python网络爬虫的基本原理、开发工具、常用框架以及实践案例。一、网络爬虫的基本原理网络爬虫的工作流程通常包括以下步骤:发送请求:向目标网站发送HTTP请求,获取网页内容。解析内容:提取需要的数据,可以是HTML标签
- 分享Python7个爬虫小案例(附源码)
人工智能-猫猫
爬虫python开发语言
在这篇文章中,我们将分享7个Python爬虫的小案例,帮助大家更好地学习和了解Python爬虫的基础知识。以下是每个案例的简介和源代码:1.爬取豆瓣电影Top250这个案例使用BeautifulSoup库爬取豆瓣电影Top250的电影名称、评分和评价人数等信息,并将这些信息保存到CSV文件中。importrequestsfrombs4importBeautifulSoupimportcsv#请求U
- python爬虫系列实例-python爬虫实例,一小时上手爬取淘宝评论(附代码)
weixin_37988176
前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。1明确目的通过访问天猫的网站,先搜索对应的商品,然后爬取它的评论数据。可以作为设计前期的市场调研的数据,帮助很大。2爬取评论并储存(首先要进行登录,获取cookie)搜索你想收集的信息的评价,然后点开对应的产品图片。找到对应的评价的位置。找到对应的位置之后就可以进行数据的爬取了
- python基于Django的旅游景点数据分析及可视化的设计与实现 7blk7
qq2295116502
pythondjango数据分析
目录项目介绍技术栈具体实现截图Scrapy爬虫框架关键技术和使用的工具环境等的说明解决的思路开发流程爬虫核心代码展示系统设计论文书写大纲详细视频演示源码获取项目介绍大数据分析是现下比较热门的词汇,通过分析之后可以得到更多深入且有价值的信息。现实的科技手段中,越来越多的应用都会涉及到大数据随着大数据时代的到来,数据挖掘、分析与应用成为多个行业的关键,本课题首先介绍了网络爬虫的基本概念以及技术实现方法
- 用python执行js代码:PyExecJS库详解
数据知道
2025年爬虫和逆向教程pythonjavascript爬虫数据采集nodejs
更多内容请见:爬虫和逆向教程-专栏介绍和目录文章目录1.介绍和安装1.1PyExecJS介绍1.2安装JavaScript运行时1.3安装PyExecJS2.PyExecJS的基本使用2.1执行简单的JavaScript代码2.2使用外部JavaScript文件2.3先编译、后调用2.4传递参数和获取返回值3.PyExecJS的高级功能3.1指定JavaScript运行时3.2处理异步JavaSc
- 利用Python爬虫获取淘宝商品评论:实战案例分析
数据小爬虫@
APIpython爬虫开发语言
在数字化时代,数据的价值日益凸显,尤其是对于电商平台而言,商品评论作为用户反馈的重要载体,蕴含着丰富的信息。本文将详细介绍如何利用Python爬虫技术获取淘宝商品评论,包括代码示例和关键步骤解析。淘宝商品评论的重要性淘宝商品评论不仅对消费者购买决策有着重要影响,而且对于商家来说,也是了解市场需求、改进产品和服务的重要途径。因此,获取并分析淘宝商品评论数据,对于电商运营和市场分析具有重要意义。Pyt
- Python异步编程 - asyncio库
孤寒者
Python全栈系列教程python异步编程asyncioyield协程
目录:每篇前言:异步IOPython中的异步编程实现方式:协程Python传统协程示例:实现生产者-消费者模型消费者:生产者:运行流程:整体流程:传统协程——>现代协程:asyncio库async/await每篇前言:作者介绍:【孤寒者】—CSDN全栈领域优质创作者、HDZ核心组成员、华为云享专家Python全栈领域博主、CSDN原力计划作者本文已收录于爬虫必备前端技术栈专栏:《爬虫必备前端技术栈
- PHP如何实现二维数组排序?
IT独行者
二维数组PHP排序
二维数组在PHP开发中经常遇到,但是他的排序就不如一维数组那样用内置函数来的方便了,(一维数组排序可以参考本站另一篇文章【PHP中数组排序函数详解汇总】)。二维数组的排序需要我们自己写函数处理了,这里UncleToo给大家分享一个PHP二维数组排序的函数:
代码:
functionarray_sort($arr,$keys,$type='asc'){
$keysvalue= $new_arr
- 【Hadoop十七】HDFS HA配置
bit1129
hadoop
基于Zookeeper的HDFS HA配置主要涉及两个文件,core-site和hdfs-site.xml。
测试环境有三台
hadoop.master
hadoop.slave1
hadoop.slave2
hadoop.master包含的组件NameNode, JournalNode, Zookeeper,DFSZKFailoverController
- 由wsdl生成的java vo类不适合做普通java vo
darrenzhu
VOwsdlwebservicerpc
开发java webservice项目时,如果我们通过SOAP协议来输入输出,我们会利用工具从wsdl文件生成webservice的client端类,但是这里面生成的java data model类却不适合做为项目中的普通java vo类来使用,当然有一中情况例外,如果这个自动生成的类里面的properties都是基本数据类型,就没问题,但是如果有集合类,就不行。原因如下:
1)使用了集合如Li
- JAVA海量数据处理之二(BitMap)
周凡杨
java算法bitmapbitset数据
路漫漫其修远兮,吾将上下而求索。想要更快,就要深入挖掘 JAVA 基础的数据结构,从来分析出所编写的 JAVA 代码为什么把内存耗尽,思考有什么办法可以节省内存呢? 啊哈!算法。这里采用了 BitMap 思想。
首先来看一个实验:
指定 VM 参数大小: -Xms256m -Xmx540m
- java类型与数据库类型
g21121
java
很多时候我们用hibernate的时候往往并不是十分关心数据库类型和java类型的对应关心,因为大多数hbm文件是自动生成的,但有些时候诸如:数据库设计、没有生成工具、使用原始JDBC、使用mybatis(ibatIS)等等情况,就会手动的去对应数据库与java的数据类型关心,当然比较简单的数据类型即使配置错了也会很快发现问题,但有些数据类型却并不是十分常见,这就给程序员带来了很多麻烦。
&nb
- Linux命令
510888780
linux命令
系统信息
arch 显示机器的处理器架构(1)
uname -m 显示机器的处理器架构(2)
uname -r 显示正在使用的内核版本
dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI)
hdparm -i /dev/hda 罗列一个磁盘的架构特性
hdparm -tT /dev/sda 在磁盘上执行测试性读取操作
cat /proc/cpuinfo 显示C
- java常用JVM参数
墙头上一根草
javajvm参数
-Xms:初始堆大小,默认为物理内存的1/64(<1GB);默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制
-Xmx:最大堆大小,默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
-Xmn:新生代的内存空间大小,注意:此处的大小是(eden+ 2
- 我的spring学习笔记9-Spring使用工厂方法实例化Bean的注意点
aijuans
Spring 3
方法一:
<bean id="musicBox" class="onlyfun.caterpillar.factory.MusicBoxFactory"
factory-method="createMusicBoxStatic"></bean>
方法二:
- mysql查询性能优化之二
annan211
UNIONmysql查询优化索引优化
1 union的限制
有时mysql无法将限制条件从外层下推到内层,这使得原本能够限制部分返回结果的条件无法应用到内层
查询的优化上。
如果希望union的各个子句能够根据limit只取部分结果集,或者希望能够先排好序在
合并结果集的话,就需要在union的各个子句中分别使用这些子句。
例如 想将两个子查询结果联合起来,然后再取前20条记录,那么mys
- 数据的备份与恢复
百合不是茶
oraclesql数据恢复数据备份
数据的备份与恢复的方式有: 表,方案 ,数据库;
数据的备份:
导出到的常见命令;
参数 说明
USERID 确定执行导出实用程序的用户名和口令
BUFFER 确定导出数据时所使用的缓冲区大小,其大小用字节表示
FILE 指定导出的二进制文
- 线程组
bijian1013
java多线程threadjava多线程线程组
有些程序包含了相当数量的线程。这时,如果按照线程的功能将他们分成不同的类别将很有用。
线程组可以用来同时对一组线程进行操作。
创建线程组:ThreadGroup g = new ThreadGroup(groupName);
&nbs
- top命令找到占用CPU最高的java线程
bijian1013
javalinuxtop
上次分析系统中占用CPU高的问题,得到一些使用Java自身调试工具的经验,与大家分享。 (1)使用top命令找出占用cpu最高的JAVA进程PID:28174 (2)如下命令找出占用cpu最高的线程
top -Hp 28174 -d 1 -n 1
32694 root 20 0 3249m 2.0g 11m S 2 6.4 3:31.12 java
- 【持久化框架MyBatis3四】MyBatis3一对一关联查询
bit1129
Mybatis3
当两个实体具有1对1的对应关系时,可以使用One-To-One的进行映射关联查询
One-To-One示例数据
以学生表Student和地址信息表为例,每个学生都有都有1个唯一的地址(现实中,这种对应关系是不合适的,因为人和地址是多对一的关系),这里只是演示目的
学生表
CREATE TABLE STUDENTS
(
- C/C++图片或文件的读写
bitcarter
写图片
先看代码:
/*strTmpResult是文件或图片字符串
* filePath文件需要写入的地址或路径
*/
int writeFile(std::string &strTmpResult,std::string &filePath)
{
int i,len = strTmpResult.length();
unsigned cha
- nginx自定义指定加载配置
ronin47
进入 /usr/local/nginx/conf/include 目录,创建 nginx.node.conf 文件,在里面输入如下代码:
upstream nodejs {
server 127.0.0.1:3000;
#server 127.0.0.1:3001;
keepalive 64;
}
server {
liste
- java-71-数值的整数次方.实现函数double Power(double base, int exponent),求base的exponent次方
bylijinnan
double
public class Power {
/**
*Q71-数值的整数次方
*实现函数double Power(double base, int exponent),求base的exponent次方。不需要考虑溢出。
*/
private static boolean InvalidInput=false;
public static void main(
- Android四大组件的理解
Cb123456
android四大组件的理解
分享一下,今天在Android开发文档-开发者指南中看到的:
App components are the essential building blocks of an Android
- [宇宙与计算]涡旋场计算与拓扑分析
comsci
计算
怎么阐述我这个理论呢? 。。。。。。。。。
首先: 宇宙是一个非线性的拓扑结构与涡旋轨道时空的统一体。。。。
我们要在宇宙中寻找到一个适合人类居住的行星,时间非常重要,早一个刻度和晚一个刻度,这颗行星的
- 同一个Tomcat不同Web应用之间共享会话Session
cwqcwqmax9
session
实现两个WEB之间通过session 共享数据
查看tomcat 关于 HTTP Connector 中有个emptySessionPath 其解释如下:
If set to true, all paths for session cookies will be set to /. This can be useful for portlet specification impleme
- springmvc Spring3 MVC,ajax,乱码
dashuaifu
springjquerymvcAjax
springmvc Spring3 MVC @ResponseBody返回,jquery ajax调用中文乱码问题解决
Spring3.0 MVC @ResponseBody 的作用是把返回值直接写到HTTP response body里。具体实现AnnotationMethodHandlerAdapter类handleResponseBody方法,具体实
- 搭建WAMP环境
dcj3sjt126com
wamp
这里先解释一下WAMP是什么意思。W:windows,A:Apache,M:MYSQL,P:PHP。也就是说本文说明的是在windows系统下搭建以apache做服务器、MYSQL为数据库的PHP开发环境。
工欲善其事,必须先利其器。因为笔者的系统是WinXP,所以下文指的系统均为此系统。笔者所使用的Apache版本为apache_2.2.11-
- yii2 使用raw http request
dcj3sjt126com
http
Parses a raw HTTP request using yii\helpers\Json::decode()
To enable parsing for JSON requests you can configure yii\web\Request::$parsers using this class:
'request' =&g
- Quartz-1.8.6 理论部分
eksliang
quartz
转载请出自出处:http://eksliang.iteye.com/blog/2207691 一.概述
基于Quartz-1.8.6进行学习,因为Quartz2.0以后的API发生的非常大的变化,统一采用了build模式进行构建;
什么是quartz?
答:简单的说他是一个开源的java作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制。并且还能和Sp
- 什么是POJO?
gupeng_ie
javaPOJO框架Hibernate
POJO--Plain Old Java Objects(简单的java对象)
POJO是一个简单的、正规Java对象,它不包含业务逻辑处理或持久化逻辑等,也不是JavaBean、EntityBean等,不具有任何特殊角色和不继承或不实现任何其它Java框架的类或接口。
POJO对象有时也被称为Data对象,大量应用于表现现实中的对象。如果项目中使用了Hiber
- jQuery网站顶部定时折叠广告
ini
JavaScripthtmljqueryWebcss
效果体验:http://hovertree.com/texiao/jquery/4.htmHTML文件代码:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>网页顶部定时收起广告jQuery特效 - HoverTree<
- Spring boot内嵌的tomcat启动失败
kane_xie
spring boot
根据这篇guide创建了一个简单的spring boot应用,能运行且成功的访问。但移植到现有项目(基于hbase)中的时候,却报出以下错误:
SEVERE: A child container failed during start
java.util.concurrent.ExecutionException: org.apache.catalina.Lif
- leetcode: sort list
michelle_0916
Algorithmlinked listsort
Sort a linked list in O(n log n) time using constant space complexity.
====analysis=======
mergeSort for singly-linked list
====code======= /**
* Definition for sin
- nginx的安装与配置,中途遇到问题的解决
qifeifei
nginx
我使用的是ubuntu13.04系统,在安装nginx的时候遇到如下几个问题,然后找思路解决的,nginx 的下载与安装
wget http://nginx.org/download/nginx-1.0.11.tar.gz
tar zxvf nginx-1.0.11.tar.gz
./configure
make
make install
安装的时候出现
- 用枚举来处理java自定义异常
tcrct
javaenumexception
在系统开发过程中,总少不免要自己处理一些异常信息,然后将异常信息变成友好的提示返回到客户端的这样一个过程,之前都是new一个自定义的异常,当然这个所谓的自定义异常也是继承RuntimeException的,但这样往往会造成异常信息说明不一致的情况,所以就想到了用枚举来解决的办法。
1,先创建一个接口,里面有两个方法,一个是getCode, 一个是getMessage
public
- erlang supervisor分析
wudixiaotie
erlang
当我们给supervisor指定需要创建的子进程的时候,会指定M,F,A,如果是simple_one_for_one的策略的话,启动子进程的方式是supervisor:start_child(SupName, OtherArgs),这种方式可以根据调用者的需求传不同的参数给需要启动的子进程的方法。和最初的参数合并成一个数组,A ++ OtherArgs。那么这个时候就有个问题了,既然参数不一致,那