兔兔 的 总结 —— 图
图
图 <目录>
- 图
- 一. 什么是图 (graph)
- 1. 定义
- 2. 概念
- 3. 图的种类
- (1). 无向图
- 1>. 定义
- 2>. 无向图的术语
- (2>. + 无向图的术语图)
- (2). 有向图
- 1>. 定义
- 2>. 有向图的术语
- (2>. + 有向图的术语图)
- (1. 2. + 有向图和无向图的图片)
- (3). 带权图
- 1>. 定义
- 二. 图的表示 (存储结构)
- 1. 邻接矩阵
- (1). 定义
- 1>. 无权值的情况
- 2>. 有权值的情况
- 3>. 优缺点
- 2. 邻接表
- (1). 定义
- 三. 图的遍历
- 1. 概念
- 2. 方法
- (1). d f s dfs dfs
- 1>. 概念
- 2>. 例子
- 3>. 模板
- (2). b f s bfs bfs
- 1>. 概念
- 2>. 例子
- 3>. 模板
- (3). 拓扑排序
一. 什么是图 (graph)
1. 定义
某类具体事物和这些事物之间的联系。(说的有点抽象,不懂的读者就看概念吧)
2. 概念
是由一种由 顶点 ( V e r t e x ) (Vertex) (Vertex) 非空有限集合 和 顶点之间边 ( E d g e ) (Edge) (Edge) 的集合 组成的数据结构,表示为 G ( V , E ) G(V,E) G(V,E)。(顶点 —— 具体事物,边 —— 具体事物之间的联系)
3. 图的种类
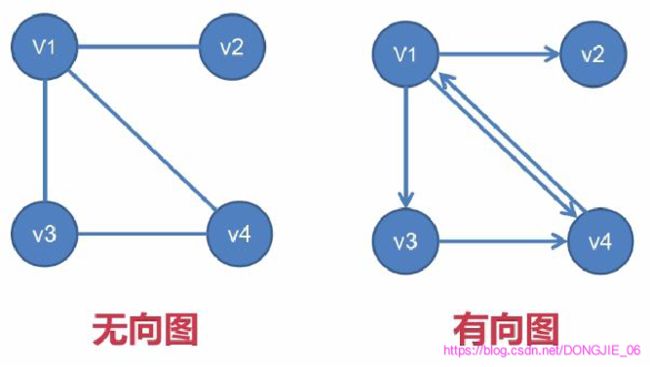
(1). 无向图
1>. 定义
边没有指定方向的图。
2>. 无向图的术语
- 两个顶点之间如果有边连接,那么就视为两个顶点 相 邻 相邻 相邻 。
- 路 径 路径 路径 :相邻顶点的序列。
- 圈 圈 圈 :起点和终点重合的路径。
- 连 通 图 连通图 连通图 :任意两点之间都有路径连接的图。
- 度 度 度 :顶点连接的边数叫做这个顶点的度。
- 树 树 树 :没有圈的连通图。
- 森 林 森林 森林:没有圈的非连通图。
(2>. + 无向图的术语图)

- 1 − 2 − 3 − 4 1 - 2 - 3 - 4 1−2−3−4 是 路 径 路径 路径
- 2 − 3 − 4 − 2 2 - 3 - 4 - 2 2−3−4−2 是 圈 圈 圈
- 节点的 度 度 度
节点 1 1 1 的 度 度 度 : 2 2 2个 ( 2 , 5 ) (2,5) (2,5)
节点 2 2 2 的 度 度 度 : 4 4 4个 ( 1 , 3 , 4 , 5 ) (1,3,4,5) (1,3,4,5)
(2). 有向图
1>. 定义
边具有指定方向的图。 (有向图中的边又称为弧,起点称为弧头,终点称为
弧尾)
2>. 有向图的术语
- 在有向图中,边是单向的:每条边所连接的两个顶点是一个有序对,他们的邻接性是单向的。
- 有 向 路 径 有向路径 有向路径 :相邻顶点的序列。
- 有 向 环 有向环 有向环 :一条至少含有一条边且起点和终点相同的有向路径。
- 有 向 无 环 图 有向无环图 有向无环图 ( D A G ) (DAG) (DAG) :没有环的有向图
- 度 度 度:一个顶点的入度与出度之和称为该顶点的度。
- 1) 入 度 入度 入度:以顶点为弧头的边的数目称为该顶点的入度。
- 2) 出 度 出度 出度:以顶点为弧尾的边的数目称为该顶点的出度。
(2>. + 有向图的术语图)

- 1 − > 3 − > 5 − > 6 1 -> 3 -> 5 -> 6 1−>3−>5−>6 : 有 向 路 径 有向路径 有向路径
- 1 − > 3 − > 4 − > 1 1 -> 3 -> 4 -> 1 1−>3−>4−>1 : 有 向 环 有向环 有向环
- ( 3 、 4 、 5 、 6 ) (3、4、5、6) (3、4、5、6) : 无 环 有 向 图 无环有向图 无环有向图
- 节点 1 1 1 的 度 度 度 : 3 3 3 个 ( 2 , 3 , 4 ) (2,3,4) (2,3,4)
节点 1 1 1 的 入 度 入度 入度 : 1 1 1个 ( 4 ) (4) (4)
节点 1 1 1 的 出 度 出度 出度 : 2 2 2个 ( 2 , 3 ) (2,3) (2,3)
(1. 2. + 有向图和无向图的图片)
(3). 带权图
1>. 定义
边上带有权值的图。 (不同问题中,权值意义不同,可以是距离、时间、价格、代价等不同属性)
二. 图的表示 (存储结构)
对于图的表示,常用的有两种:
- 邻接矩阵
- 邻接表
1. 邻接矩阵
(1). 定义
用二维数组储存点与点之间的关系。
1>. 无权值的情况
由于没有权值,我们可以用 bool数组 G [ i ] [ j ] G[i][j] G[i][j] 表示 顶 点 i 顶点i 顶点i 是否能到达 顶 点 j 顶点j 顶点j。
- 如果 顶 点 i 顶点i 顶点i 和 顶 点 j 顶点j 顶点j 之间有边相连, G [ i ] [ j ] = 1 G[i][j] = 1 G[i][j]=1
- 如果 顶 点 i 顶点i 顶点i 和 顶 点 j 顶点j 顶点j 之间无边相连, G [ i ] [ j ] = 0 G[i][j] = 0 G[i][j]=0
(对于无向图:如果 顶 点 i 顶点i 顶点i 能到达 顶 点 j 顶点j 顶点j,那么 顶 点 j 顶点j 顶点j 也能到达 顶 点 i 顶点i 顶点i G [ i ] [ j ] = G [ j ] [ i ] = 1 G[i][j] = G[j][i] = 1 G[i][j]=G[j][i]=1)
2>. 有权值的情况
有权值的情况和无权值的情况类似:
- 只是 G [ i ] [ j ] G[i][j] G[i][j] 不再是 b o o l 类 型 bool类型 bool类型 的,而是 i n t int int 或者 d o u b l e double double ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ······ ⋅⋅⋅⋅⋅⋅。
- 因为在带权图中初始化为 0 0 0,如果边不存在,则无法 与 权值为 0 0 0 的情况分开,所以初始化的时候需要赋初值,一般是最大或最小。
3>. 优缺点
- 邻接矩阵的优点:可以在常数时间内判断两点之间是否有边存在。
- 邻接矩阵的缺点:表示稀疏图时,浪费大量内存空间。表示稠密图还是很划算。
这时候就可以使用邻接表了
2. 邻接表
(1). 定义
通过把 " 从某个顶点出发有哪些顶点 " 这样的信息保存在链表中来表示图。
其实就是用 v e c t o r < i n t > G [ ] vector
三. 图的遍历
1. 概念
从图中的某个顶点出发,按某种方法对图中的所有顶点进行访问 (每个顶点只访问一次)。
为了保证图中的顶点在遍历过程中仅访问一次,要为每一个顶点设置一个访问标志。
2. 方法
- d f s dfs dfs
- b f s bfs bfs
(1). d f s dfs dfs
1>. 概念
深 度 优 先 搜 索 ( D e p t h − F i r s t S e a r c h ) 深度优先搜索 (Depth-First Search) 深度优先搜索(Depth−FirstSearch) 遍历类似于树的** 先根遍历**,是树的先根遍历的推广。
- 假设初始状态是图中所有顶点未曾被访问,则深度优先搜索可从图中某个顶点 v v v 出发,访问此顶点,然后依次从 v v v 的未被访问的邻接点出发深度优先遍历图,直至图中所有和 v v v 有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
2>. 例子

此时得到顶点 1 1 1 访问序列为: v 1 − > v 2 − > v 4 − > v 8 − > v 5 ( v 2 已 经 访 问 过 了 ) − > v 3 − > v 6 − > v 7 v1 -> v2 -> v4 -> v8 -> v5 (v2已经访问过了) -> v3 -> v6 -> v7 v1−>v2−>v4−>v8−>v5(v2已经访问过了)−>v3−>v6−>v7
3>. 模板
兔兔还是给大家打了一个模板哦~:
#include (2). b f s bfs bfs
1>. 概念
广 度 优 先 搜 索 ( B r e a d t h − F i r s t S e a r c h ) 广度优先搜索(Breadth-First Search) 广度优先搜索(Breadth−FirstSearch) 遍历类似于树的按 层次遍历 的过程。
- 假设从图中某顶点 v v v 出发,在访问 v v v 之后依次访问 v v v 的各个未被访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使“先被访问的顶点的邻接点”先于“后被访问的顶点的邻接点”被访问,直至图中所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。换句话说,广度优先搜索遍历图的过程是以 v v v 为起始点,由近至远,依次访问和 v v v 有路径相通且路径长度为 1 1 1, 2 2 2 … … …的顶点。
2>. 例子
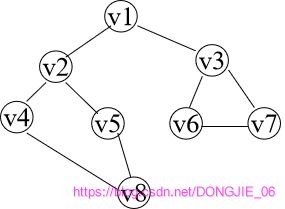
此时有顶点 1 1 1 开始遍历的过程: v 1 − > v 2 − > v 3 − > v 4 − > v 5 − > v 6 − > v 7 − > v 8 v1 -> v2 -> v3 -> v4 -> v5 -> v6 -> v7 -> v8 v1−>v2−>v3−>v4−>v5−>v6−>v7−>v8
3>. 模板
#include (3). 拓扑排序
- 对一个 有 向 无 环 图 ( D i r e c t e d A c y c l i c G r a p h 简 称 D A G ) 有向无环图(Directed Acyclic Graph简称DAG) 有向无环图(DirectedAcyclicGraph简称DAG) G G G 进行拓扑排序,是将 G G G 中所有顶点排成一个线性序列,使得图中任意一对顶点 u u u 和 v v v,若边 < u , v > ∈ E ( G )
- 简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为 拓 扑 排 序 拓扑排序 拓扑排序。
兔兔的总结就到这里结束啦~
如果有什么需要兔兔改进的地方,请读者 给兔兔私信 或者 在评论区留言 哦~