上一次讲了Python抓取淘宝美人库,未经过任何优化,代码稳定性也没的保证,这次借助爬虫框架Pyspider实现一个较为正规的小爬虫。目的是掌握爬虫框架pyspider的用法。

Pyspider是国内一个大神编写的强大爬虫框架,详情见pyspider中文网,相比于其他爬虫框架(比如Scrapy),pyspider上手相当简单,整个过程也很快可以实现,熟练的话1小时可以做好几个网站的爬虫。
该框架将下载模块进行了封装,用户只需要关注网页内容解析即可。好,现在开始工作!
还是老规矩,按步骤来:
1、pyspider安装。
按照框架作者所言,整个框架是在linux系统下完成的,在windows系统下并没有做过测试,但考虑到python的平台兼容性,也可能完美运行,不过最好还是在linux系统下进行使用。注:python2.x、python3.x都可以使用
linux下安装很简单:执行pip install pyspider即可
2、新建项目。
看过pyspider介绍的应该知道,pyspider是webUI形式的框架,所有代码都可以在webUI里完成。创建工程项目,首先需要启动pyspider,在系统终端执行pyspider all即可,需要注意的是pyspider支持网页的动态解析,但需要phantomjs支持(本项目暂未用到),关于phantomjs就不多讲了,只要知道这是一个没有界面的浏览器就行了,用于动态网页解析。所以先要安装phantomjs再启动pyspider。启动之后就可以在localhost:5000看到pyspider的webUI了,长这样:

我的截图里面是已经创建了几个项目,第一次用的话里面应该是空的。
点击Create创建一个New Project,Project Name随便起,其他暂不用管,接着就进入编辑区:
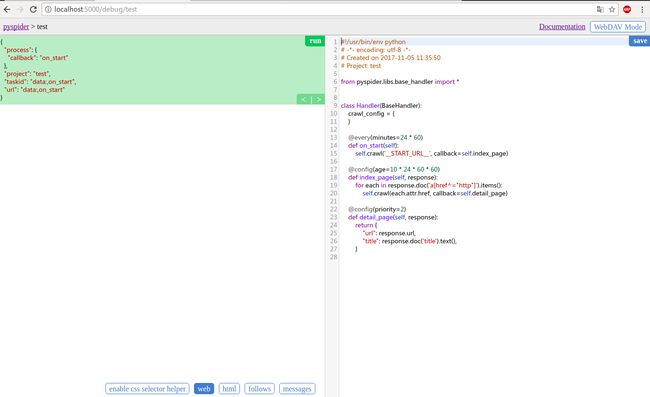
左边相当于输出区,右边相当于代码编辑器(所有代码都可以在代码编辑区编写),左侧底部区控制左侧页面切换:enable css selector helpe是css selector帮助器,web切换到web输出界面,html切换到html输出界面,follows切换到爬取url输出界面,messages切换到代码的print界面。save按钮用来保存编辑的代码,Run用来运行代码。就本图片中代码,Run之后会出现

可以看到左侧输出区follows切换卡有内容输出,点进去

看到有index_page__START_URL__输出,点击右侧前进按钮就可以看到控制台输出(因为url报错,不用慌)

在这里Run相当于单步调试,如果代码编写好之后我们就可以回到localhost:5000可以看到项目列表多了刚才创建的项目test。
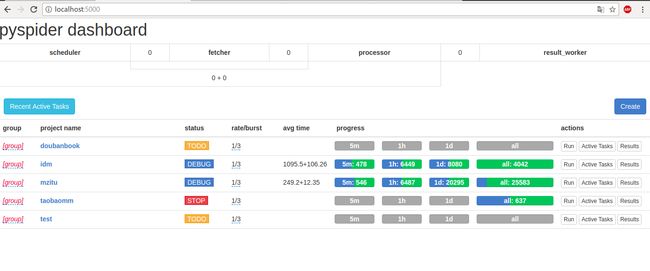
点击test对应的status, 将之修改为DEBUG(或者RUNNING),再点击后面的Run,爬虫就开始全速工作了。
以上就是pyspider的简单操作内容。
3、目标网站分析。
本次我们以妹子图为目标。
我们这次的目标是爬下该网站的所有图,简单估算了一下,网站迄今为止共推出了1800+套图集,每套图集大概有50+张图片,所以有多少图片?
网站所有图入口:在这里
F12(chrome浏览器的F12打开页面审查,爬虫儿必备技能)看一下
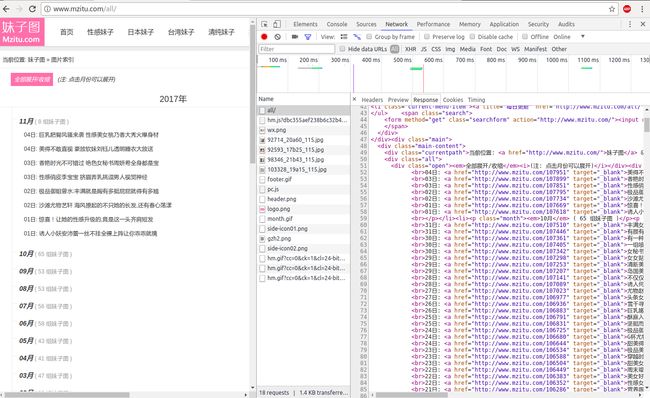
点进一个链接看一下


页面源码直接暴露了图片链接!
4、代码实现。
还是进入localhost:5000点击刚才创建的项目名进入代码编辑页,初始代码如下:
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
# 框架配置内容
crawl_config = {
}
# 框架入口函数
@every(minutes=24 * 60)
def on_start(self):
self.crawl('__START_URL__', callback=self.index_page)
# 函数调用
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
# 函数调用
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
在pyspider中程序起始于on_start函数,crawl()函数调用框架的网页下载器并把下载的内容传给调用的函数(callback参数指定的函数)。那么我们首先应该给框架指定一个根url,所以在初始代码中加入:
def __init__(self):
self.root_url = 'http://www.mzitu.com/all/'
并修改on_start函数为:
def on_start(self):
self.crawl(self.root_url, callback=self.index_page)
save之后Run一下:

点进去:

因为初始代码在调用函数index_page里做了过滤,所以输出区看到一堆url链接,我们发现其中就包含了我们需要的链接(每套图集对应的链接,例如http://www.mzitu.com/108003),但也包含了一些无用链接(如http://www.mzitu.com/xinggan/),怎么办呢?当然是修改默认的过滤规则咯,我们对套图链接稍加分析就可以看出它们的特点:"http://www.mzitu.com/数字",利用此特点就可以轻松地将它们从中筛选出来,因为筛选规则简单,在这里我们就选择正则表达式来筛选:
修改index_page函数为(注意头部导入正则库import re):
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match('http://www.mzitu.com/\d.*$', each.attr.href):
self.crawl(each.attr.href, callback=self.detail_page)
再次save、Run,不出意外就可以得到正确的套图url了。
以上我们已经拿到了所有套图的链接,简不简单!
接下来要做的是进入每个套图链接并获取图片,网页下载的部分框架已经帮我们实现了,在index_page函数的self.crawl(each.attr.href, callback=self.detail_page)调用里,这句调用告诉框架:你去下载each.attr.href(刚才分析的套图链接)网页内容,并调用detail_page函数。
接下来修改detail_page函数,这个函数拿到的response就是套图链接网页的内容,我们从左侧输出区随便点进一个套图看一看(切换到web视图):

这个web视图不太友好,不过也没关系,能看就行!可以看到进入套图链接后已经可以看到图片了,那么我们应该怎么在对应的网页源码中定位该图片url呢?很简单,就用框架提供的css selector帮助器,保持web选项卡不变,点击enable css selector helper即来到帮助模式,可以发现鼠标停留的页面元素被选中,单击该页面元素就可以在源码中定位到该页面元素的位置,so,我们点击图片:
注意看,页面上方出现了该元素的标签定位,好了,定位也完成了,开始修改detial_page函数:
def detail_page(self, response):
for each in response.doc('').items():
print(each.attr.src)
return {
"url": response.url,
"title": response.doc('title').text(),
}
此时,代码中筛选规则是空的response.doc('').items(),接下来就是见证奇迹的时候,将编辑光标停留在response.doc('停在这里').items(),然后鼠标单击刚才css selector生成的标签后面的->按钮,Duang!筛选规则已经插入代码中了,看起来像这样:
def detail_page(self, response):
for each in response.doc('p img').items(): # 筛选规则已经插入
print(each.attr.src)
return {
"url": response.url,
"title": response.doc('title').text(),
}
save、Run

看到没,灰色输出区已经输出了图片的url,接下来是不是要收到碗里来了呢?还差一步!细心的你可能就发现了,这只是保存了每套图里的第一张图,后面的呢?每套图不是50+张么?那我们就找啊,发现了,在这里

套图页面通过图片下方的页码来切换图片,那简单,有两种方案:
1、我们直接拿到页码链接,然后遍历即可;
2、我们拿下一页按钮的链接,然后遍历。
这两种方案都是OK的,这里我们用方案2,实践发现如果我们还用css selector来定位下一页链接会出问题,因为在本页面中css selector选择的是下一页所在文本的位置,而链接所在的标签属于文本标签的父标签,同时页码和下一页是并列关系,单纯用css selector并不能从中定位到唯一的下一页的链接,那我们就F12查看源码,发现
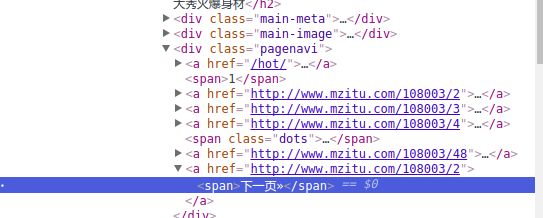
那么根据css 选择器规则不难得出筛选规则:.pagenavi > a:last-child,啥?不了解css选择器?回家等死吧!(CSS选择器传送门)。
完善detail_page函数:
def detail_page(self, response):
for each in response.doc('p img').items():
print(each.attr.src)
for each in response.doc('.pagenavi > a:last-child').items():
# 根据拿到的下一页url继续调用detail_page函数,获取下一页的图片和下一页中的下一页
self.crawl(each.attr.href, callback=self.detail_page)
return {
"url": response.url,
"title": response.doc('title').text(),
}
save、Run,至此,所有url都可以获取到了。接下来想干什么?随便你,存数据库、down到本地,没问题!以保存本地为例给出代码实现。图片url拿到了,怎么保存本地?当然是访问url,并保存获取的response了,保存本地的代码我就不实现了,这里放上从别处找来的源码,给封装成一个Deal类了(作者:静觅),以后可以随时用,很方便:
import os
class Deal:
def __init__(self):
self.path = DIR_PATH
if not self.path.endswith('/'):
self.path = self.path + '/'
if not os.path.exists(self.path):
os.makedirs(self.path)
# 这个是建文件夹的
def mkDir(self, path):
path = path.strip()
dir_path = self.path + path
exists = os.path.exists(dir_path)
if not exists:
os.makedirs(dir_path)
return dir_path
else:
return dir_path
# 这个是存图片的
def saveImg(self, content, path):
f = open(path, 'wb')
f.write(content)
f.close()
# 这个是存文本的
def saveBrief(self, content, dir_path, name):
file_name = dir_path + "/" + name + ".txt"
f = open(file_name, "w+")
f.write(content.encode('utf-8'))
# 这个是获取文件后缀的
def getExtension(self, url):
extension = url.split('.')[-1]
return extension
以上,所有内容!
完整源码
注:关于图片防盗链的不用我解释了,网上一搜就知道怎么回事

参考资料:
Python爬虫进阶四之PySpider的用法
小白爬虫第一弹之抓取妹子图
pyspider
CSS选择器参考手册
上一节:Python抓取淘宝美人库