爬取noi官网所有题目分析
最近自学,写了几个小脚本,一个脚本是爬取某东全网的所有数据,但是由于这个比较费时间 = =数据量也有点儿大。没具体爬一波,就爬了几个分类。
今天这个小项目,是爬取noi的官网的所有题目,其实题目量比较小了,一个多小时也就写完了,才几百个,和jd官网的几千万差距是有点儿大的。
现分析一下怎么爬取的,在粘贴一波代码。
第一步:观察网页
先观察一波noi的官网的网页的题目分类。

大概就是这样子了,在主页上只展示了标题如1.1,1.2,1.3...的标题,标题下面显示了部分题目。很显然这些题目的爬取还不够。太少。我们的目的是获取每一个title的链接,为了跳到下一个网页上。
第二步:分析第一个网页
打开goole浏览器的开发者模式,分析一波题目链接
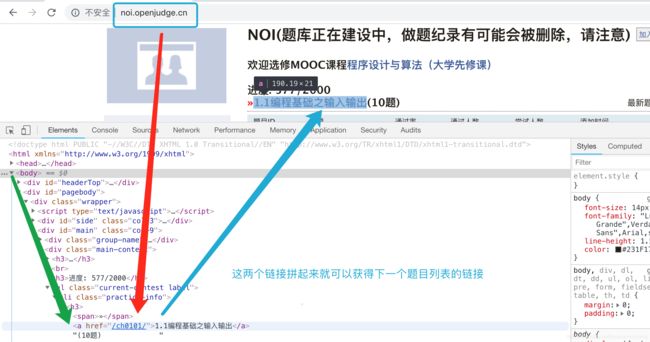
我们的任务就是爬取第一个官方主页的所有title链接,用于我们获取下一页的所有题目页。

输入链接,很明显,我们的猜想是正确的。
第三步:分析第二个页面的题目链接
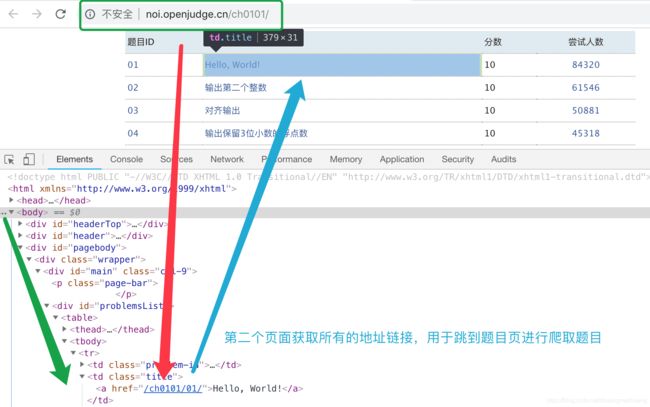
第二个页面获取所有的地址链接用于我们跳到第三个页面。
第四步:分析题目页的网页

题目分析完了,下一步就是粘一波代码了。
第五步:爬取noi所有题目
代码部分:
import requests
from bs4 import BeautifulSoup
def get_page_one():
headers = {
'Cookie': 'PHPSESSID=9k52q5kv00l4m29nvbf55m08j7',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/70.0.3538.77 Safari/537.36',
'Host': 'noi.openjudge.cn',
'Connection': 'keep-alive'
}
url = 'http://noi.openjudge.cn'
response = requests.get(url, headers=headers)
# print(response.text)
try:
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except Exception as e:
print(e)
return None
def get_page_two(href):
headers = {
'Cookie': 'PHPSESSID=9k52q5kv00l4m29nvbf55m08j7',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/70.0.3538.77 Safari/537.36',
'Host': 'noi.openjudge.cn',
'Connection': 'keep-alive'
}
url = 'http://noi.openjudge.cn' + href
response = requests.get(url, headers=headers)
# print(response.text)
try:
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except Exception as e:
print(e)
return None
def get_page_three(href):
headers = {
'Cookie': 'PHPSESSID=9k52q5kv00l4m29nvbf55m08j7',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/70.0.3538.77 Safari/537.36',
'Host': 'noi.openjudge.cn',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
url = 'http://noi.openjudge.cn' + href
response = requests.get(url, headers=headers)
try:
if response.status_code == 200:
response.encoding = response.apparent_encoding
return response.text
return None
except Exception as e:
print(e)
return None
def parse_html_href_one(html):
soup = BeautifulSoup(html, 'lxml')
storge = list()
for ul in soup.select('.practice-info h3 a'):
storge.append(ul['href'])
return storge
def parse_html_href_two(html_two):
count = 0
storge_two = list()
storge_three = list()
for i in html_two:
htmls = get_page_two(i)
soup = BeautifulSoup(htmls, 'lxml')
for ul in soup.select('.title a'):
storge_two.append(ul['href'])
storge_three.append(ul.get_text())
count += 1
print('一共有题目{}'.format(count))
return storge_two, storge_three
def parse_html_href_three(html_three, html_four):
count = 0
for i in html_three:
count += 1
htmls = get_page_three(i)
soup = BeautifulSoup(htmls, 'lxml')
for ul in soup.select('.problem-content'):
write_to_file(ul.get_text(), str(html_four[count - 1]))
print(ul.get_text())
print('-----------------------')
def write_to_file(content, number):
try:
with open('{}.txt'.format(number), 'w') as file:
file.write(content)
except Exception as e:
print(e)
def start():
href = parse_html_href_one(get_page_one())
href_two, href_three = parse_html_href_two(href)
parse_html_href_three(href_two, href_three)
if __name__ == '__main__':
start()
以上就是我爬取noi的代码的脚本。
各位如有需求自行下载。这是我学习爬取时候的一个小练习,各位如想转发,请在转发时提及在下的名称就好。如有另外思路,互相交流,在下还有爬取某东全网所有品牌所有数据的脚本。后续可能会写博客分享一波。