HashCode详解
1、概念
通常想查找一个集合中是否包含某个对象,就是逐一取出每个元素与要查找的元素进行比较,当发现某个元素与要查找的对象进行equals方法比较的结果相等时,则停止继续查找并返回肯定的信息,否则返回否定的信息。如果一个集合中有很多元素譬如成千上万的元素,并且没有包含要查找的对象时,则意味着你的程序需要从该集合中取出成千上万个元素进行逐一比较才能得到结论,于是,有人就发明了一种哈希算法来提高从集合中查找元素的效率。这种方式将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组,每组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储的那个区域。
hashCode方法可以这样理解:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
2、将元素放入集合的流程图
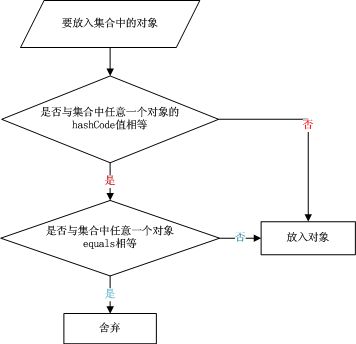
3、hashcode() 方法,在object类中定义如下
public native int hashCode(); 说明它是一个本地方法,它的实现是根据本地机器相关的。当然我们可以在自己写的类中覆盖hashcode()方法,比如String、Integer、Double等这些类都是覆盖了hashcode()方法的。例如在String类中定义的hashcode()方法如下:
public int hashCode() {
int h = hash;
if (h == 0) {
int off = offset;
char val[] = value;
int len = count;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
} 4、代码示例
(1)
public static void main(String[] args) {
String s1 = new String("zhangsan");
String s2 = new String("zhangsan");
System.out.println(s1 == s2);// false
System.out.println(s1.equals(s2));// true
System.out.println(s1.hashCode());// s1.hashcode()等于s2.hashcode()
System.out.println(s2.hashCode());
Set hashset = new HashSet();
hashset.add(s1);
hashset.add(s2);
System.out.println(hashset.size());//1
}(2)
public class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
public static void main(String[] args) {
Point p1 = new Point(3, 3);
Point p2 = new Point(5, 5);
Point p3 = new Point(3, 3);
Collection collection = new ArrayList();
collection.add(p1);
collection.add(p2);
collection.add(p3);
collection.add(p1);
System.out.println(collection.size());//4,结果输出4,以为List中可以有重复元素,而且是有序的。
}
}(3)在上例的基础上稍作修改把ArrayList改为HashSet
public class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
public static void main(String[] args) {
Point p1 = new Point(3, 3);
Point p2 = new Point(5, 5);
Point p3 = new Point(3, 3);
Collection collection = new HashSet();
collection.add(p1);
collection.add(p2);
collection.add(p3);
collection.add(p1);
System.out.println(collection.size());//3,因为HashSet中不会保存重复的对象,每添加一个元素,先判断,再添加,如果已经存在,那么就不在添加,无序的!
}
}(4)如果我们需要p1和p3相等呢?就必须重新hashcode()和equal()方法
public class Point {
private int x;
private int y;
public Point(int x, int y) {
super();
this.x = x;
this.y = y;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
final Point other = (Point) obj;
if (x != other.x)
return false;
if (y != other.y)
return false;
return true;
}
public static void main(String[] args) {
Point p1 = new Point(3, 3);
Point p2 = new Point(5, 5);
Point p3 = new Point(3, 3);
Collection collection = new HashSet();
collection.add(p1);
collection.add(p2);
collection.add(p3);
collection.add(p1);
System.out.println(collection.size());//输出2,此时p1和p3是相等的
}
}5、==,equals(),hashCode()比较
(1)’==’是用来比较两个变量(基本类型和对象类型)的值是否相等的, 如果两个变量是基本类型的,那很容易,直接比较值就可以了。如果两个变量是对象类型的,那么它还是比较值,只是它比较的是这两个对象在栈中的引用(即地址)。 对象是放在堆中的,栈中存放的是对象的引用(地址)。由此可见’==’是对栈中的值进行比较的。如果要比较堆中对象的内容是否相同,那么就要重写equals方法了。
(2)Object类中的equals方法就是用’==’来比较的,所以如果没有重写equals方法,equals和==是等价的。 通常我们会重写equals方法,让equals比较两个对象的内容,而不是比较对象的引用(地址)因为往往我们觉得比较对象的内容是否相同比比较对象的引用(地址)更有意义。
(3)Object类中的hashCode是返回对象在内存中地址转换成的一个int值(可以就当做地址看)。所以如果没有重写hashCode方法,任何对象的hashCode都是不相等的。通常在集合类的时候需要重写hashCode方法和equals方法,因为如果需要给集合类(比如:HashSet)添加对象,那么在添加之前需要查看给集合里是否已经有了该对象,比较好的方式就是用hashCode。
(4)注意的是String、Integer、Boolean、Double等这些类都重写了equals和hashCode方法,这两个方法是根据对象的内容来比较和计算hashCode的。(详细可以查看jdk下的String.java源代码),所以只要对象的基本类型值相同,那么hashcode就一定相同。