Google Machine Learning Course NoteBook--Data Preparation and Feature Engineering in ML
Steps to Constructing Your Dataset
To construct your dataset (and before doing data transformation), you should:
- Collect the raw data.
- Identify feature and label sources.
- Select a sampling strategy.
- Split the data.
You might eventually use this many features, but it’s still better to start with fewer. Fewer features usually means fewer unnecessary complications.
Collecting Data
The Size and Quality of a Data Set:
- Simple models on large data sets generally beat fancy models on small data sets.
- What counts as “a lot” of data? It depends on the project
- Consider taking an empirical approach and picking the option that produces the best outcome. With that mindset, a quality data set is one that lets you succeed with the business problem you care about. In other words, the data is good if it accomplishes its intended task.
Certain aspects of quality tend to correspond to better-performing models:
Reliability:
- How common are label errors? For example, if your data is labeled by humans, sometimes humans make mistakes.
- Are your features noisy? For example, GPS measurements fluctuate. Some noise is okay. You’ll never purge your data set of all noise. You can collect more examples too.
- Is the data properly filtered for your problem? For example, should your data set include search queries from bots? If you’re building a spam-detection system, then likely the answer is yes, but if you’re trying to improve search results for humans, then no.
What makes data unreliable?
- Omitted values. For instance, a person forgot to enter a value for a house’s age.
- Duplicate examples. For example, a server mistakenly uploaded the same logs twice.
- Bad labels. For instance, a person mislabeled a picture of an oak tree as a maple.
- Bad feature values. For example, someone typed an extra digit, or a thermometer was left out in the sun.
Feature representation
- How is data shown to the model?
- Should you normalize numeric values?
- How should you handle outliers?
Minimizing skew
Always consider what data is available to your model at prediction time. During training, use only the features that you’ll have available in serving, and make sure your training set is representative of your serving traffic.
The Golden Rule: Do unto training as you would do unto prediction. That is, the more closely your training task matches your prediction task, the better your ML system will perform.
Joining Data Logs
Types of Logs:
- Transactional logs:record a specific event. For example, a transactional log might record an IP address making a query and the date and time at which the query was made.
- Attribute data:contains snapshots of information
- Aggregate statistics:create an attribute from multiple transactional logs.
Joining Log Sources:
When collecting data for your machine learning model, you must join together different sources to create your data set.
- Leverage the user’s ID and timestamp in transactional logs to look up user attributes at time of event.
- Use the transaction timestamp to select search history at time of query.
It is critical to use event timestamps when looking up attribute data. If you grab the latest user attributes, your training data will contain the values at the time of data collection, which causes training/serving skew. If you forget to do this for search history, you could leak the true outcome into your training data!
Identifying Labels and Sources
Direct vs. Derived Labels
Machine learning is easier when your labels are well-defined. The best label is a direct label of what you want to predict.
If you have click logs, realize that you’ll never see an impression without a click. You would need logs where the events are impressions, so you cover all cases in which a user sees a top search result.
Choose event data carefully to avoid cyclical or seasonal effects or to take those effects into account.
Sampling and Splitting Data
How do you select that subset? As an example, consider Google Search. At what granularity would you sample its massive amounts of data? Would you use random queries? Random sessions? Random users?
Ultimately, the answer depends on the problem: what do we want to predict, and what features do we want?
- To use the feature previous query, you need to sample at the session level, because sessions contain a sequence of queries.
- To use the feature user behavior from previous days, you need to sample at the user level.
Filtering for PII (Personally Identifiable Information)
If your data includes PII (personally identifiable information), you may need to filter it from your data. A policy may require you to remove infrequent features, for example.
This filtering is helpful because very infrequent features are hard to learn. But it’s important to realize that your dataset will be biased toward the head queries. At serving time, you can expect to do worse on serving examples from the tail, since these were the examples that got filtered out of your training data. Although this skew can’t be avoided, be aware of it during your analysis.
Imbalanced Data
Classes that make up a large proportion of the data set are called majority classes. Those that make up a smaller proportion are minority classes.
What counts as imbalanced? The answer could range from mild to extreme, as the table below shows.
| Degree of Imbalance | Proportion of minority classes |
|---|---|
| Extreme | <1% |
| Moderate | 1%-20% of the data set |
| Mild | 20%-40% |

Why would this be problematic? With so few positives relative to negatives, the training model will spend most of its time on negative examples and not learn enough from positive ones. For example, if your batch size is 128, many batches will have no positive examples, so the gradients will be less informative.
If you have an imbalanced data set, first try training on the true distribution. If the model works well and generalizes, you’re done! If not, try downsampling and upweighting technique.
Downsampling (in this context) means training on a disproportionately low subset of the majority class examples.
Consider again our example of the fraud data set, with 1 positive to 200 negatives. We can downsample by a factor of 20, taking 1/10 negatives. Now about 10% of our data is positive, which will be much better for training our model.
Upweighting means adding an example weight to the downsampled class equal to the factor by which you downsampled.
Since we downsampled by a factor of 20, the example weight should be 20.
Why Downsample and Upweight?
It may seem odd to add example weights after downsampling. We were trying to make our model improve on the minority class – why would we upweight the majority? These are the resulting changes:
- Faster convergence: During training, we see the minority class more often, which will help the model converge faster.
- Disk space: By consolidating the majority class into fewer examples with larger weights, we spend less disk space storing them. This savings allows more disk space for the minority class, so we can collect a greater number and a wider range of examples from that class.
- Calibration: Upweighting ensures our model is still calibrated; the outputs can still be interpreted as probabilities.
Note that it matters whether you care if the model reports a calibrated probability or not. If it doesn’t need to be calibrated, you don’t need to worry about changing the base rate.
Data Split Example
After collecting your data and sampling where needed, the next step is to split your data into training sets, validation sets, and testing sets.
A frequent technique for online systems is to split the data by time, such that you would:
- Collect 30 days of data.
- Train on data from Days 1-29.
- Evaluate on data from Day 30.
To design a split that is representative of your data, consider what the data represents. The golden rule applies to data splits as well: the testing task should match the production task as closely as possible.
Examples when randomly split does work:
- Time series data:Random splitting divides each cluster across the test/train split, providing a “sneak preview” to the model that won’t be available in production.
- Groupings of data:The test set will always be too similar to the training set because clusters of similar data are in both sets. The model will appear to have better predictive power than it does.
- Data with burstiness (data arriving in intermittent bursts as opposed to a continuous stream):Clusters of similar data (the bursts) will show up in both training and testing. The model will make better predictions in testing than with new data.
Make your data generation pipeline reproducible.
Say you want to add a feature to see how it affects model quality. For a fair experiment, your datasets should be identical except for this new feature. If your data generation runs are not reproducible, you can’t make these datasets.
In that spirit, make sure any randomization in data generation can be made deterministic:
- Seed your random number generators (RNGs). Seeding ensures that the RNG outputs the same values in the same order each time you run it, recreating your dataset.
- Use invariant hash keys. Hashing is a common way to split or sample data. You can hash each example, and use the resulting integer to decide in which split to place the example. The inputs to your hash function shouldn’t change each time you run the data generation program. Don’t use the current time or a random number in your hash, for example, if you want to recreate your hashes on demand.
The preceding approaches apply both to sampling and splitting your data.
Transforming Data
Feature engineering is the process of determining which features might be useful in training a model, and then creating those features by transforming raw data found in log files and other sources.
Reasons for Data Transformation:
- Mandatory transformations for data compatibility:
- Converting non-numeric features into numeric. You can’t do matrix multiplication on a string, so we must convert the string to some numeric representation.
- Resizing inputs to a fixed size. Linear models and feed-forward neural networks have a fixed number of input nodes, so your input data must always have the same size. For example, image models need to reshape the images in their dataset to a fixed size.
- Optional quality transformations that may help the model perform better:
- Tokenization or lower-casing of text features.
- Normalized numeric features (most models perform better afterwards).
- Allowing linear models to introduce non-linearities into the feature space.
Visualize your data frequently. Consider Anscombe’s Quartet: your data can look one way in the basic statistics, and another when graphed. Before you get too far into analysis, look at your data graphically, either via scatter plots or histograms. View graphs not only at the beginning of the pipeline, but also throughout transformation. Visualizations will help you continually check your assumptions and see the effects of any major changes.
Transforming Numeric Data
You may need to apply two kinds of transformations to numeric data:
- Normalizing - transforming numeric data to the same scale as other numeric data.
- Bucketing - transforming numeric (usually continuous) data to categorical data.
Normalize Numeric Features
Normalization is necessary if you have very different values within the same feature (for example, city population). Without normalization, your training could blow up with NaNs if the gradient update is too large.
You might have two different features with widely different ranges (e.g., age and income), causing the gradient descent to “bounce” and slow down convergence. Optimizers like Adagrad and Adam protect against this problem by creating a separate effective learning rate per feature. But optimizers can’t save you from a wide range of values within a single feature; in those cases, you must normalize.
Warning: When normalizing, ensure that the same normalizations are applied at serving time to avoid skew.
The goal of normalization is to transform features to be on a similar scale. This improves the performance and training stability of the model.
Four common normalization techniques may be useful:
- scaling to a range
- clipping
- log scaling
- z-score
-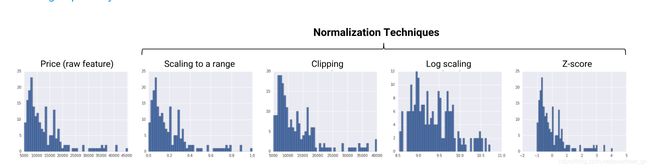
Scaling to a range
Scaling means converting floating-point feature values from their natural range (for example, 100 to 900) into a standard range—usually 0 and 1 (or sometimes -1 to +1). Use the following simple formula to scale to a range:
x’ = (x-xmin)/(xmax-xmin)
Scaling to a range is a good choice when both of the following conditions are met:
- You know the approximate upper and lower bounds on your data with few or no outliers.
- Your data is approximately uniformly distributed across that range.
Feature Clipping
If your data set contains extreme outliers, you might try feature clipping, which caps all feature values above (or below) a certain value to fixed value. For example, you could clip all temperature values above 40 to be exactly 40.
You may apply feature clipping before or after other normalizations.
One simple clipping strategy is to clip by z-score to ±Nσ (for example, limit to ±3σ). Note that σ is the standard deviation.
Log Scaling
Log scaling computes the log of your values to compress a wide range to a narrow range.
x’ = log(x)
Log scaling is helpful when a handful of your values have many points, while most other values have few points. This data distribution is known as the power law distribution. Movie ratings are a good example. Most movies have very few ratings (the data in the tail), while a few have lots of ratings (the data in the head). Log scaling changes the distribution, helping to improve linear model performance.
Z-Score
Z-score is a variation of scaling that represents the number of standard deviations away from the mean. You would use z-score to ensure your feature distributions have mean = 0 and std = 1. It’s useful when there are a few outliers, but not so extreme that you need clipping.
The formula for calculating the z-score of a point, x, is as follows:
x’ = (x-mean)/dev
Summary
| Normalization Technique | When to Use |
|---|---|
| Linear Scaling | When the feature is more-or-less uniformly distributed across a fixed range |
| Clipping | When the feature contains some extreme outliers. |
| Log Scaling | When the feature conforms to the power law. |
| Z-score | When the feature distribution does not contain extreme outliers |
Bucketing
Quantile Bucketing
Creating buckets so that each have the same number of points.
Bucketing Summary
If you choose to bucketize your numerical features, be clear about how you are setting the boundaries and which type of bucketing you’re applying:
- Buckets with equally spaced boundaries: the boundaries are fixed and encompass the same range (for example, 0-4 degrees, 5-9 degrees, and 10-14 degrees, or $5,000-$9,999, $10,000-$14,999, and $15,000-$19,999). Some buckets could contain many points, while others could have few or none.
- Buckets with quantile boundaries: each bucket has the same number of points. The boundaries are not fixed and could encompass a narrow or wide span of values.
Bucketing with equally spaced boundaries is an easy method that works for a lot of data distributions. For skewed data, however, try bucketing with quantile bucketing.
Transforming Categorical Data
Some of your features may be discrete values that aren’t in an ordered relationship. Examples include breeds of dogs, words, or postal codes. These features are known as categorical and each value is called a category. You can represent categorical values as strings or even numbers, but you won’t be able to compare these numbers or subtract them from each other.
If the number of categories of a data field is small, such as the day of the week or a limited palette of colors, you can make a unique feature for each category. This sort of mapping is called a vocabulary.
Vocabulary
In a vocabulary, each value represents a unique feature.The model looks up the index from the string, assigning 1.0 to the corresponding slot in the feature vector and 0.0 to all the other slots in the feature vector.

Note about sparse representation
f your categories are the days of the week, you might, for example, end up representing Friday with the feature vector [0, 0, 0, 0, 1, 0, 0]. However, most implementations of ML systems will represent this vector in memory with a sparse representation. A common representation is a list of non-empty values and their corresponding indices—for example, 1.0 for the value and [4] for the index. This allows you to spend less memory storing a huge amount of 0s and allows more efficient matrix multiplication. In terms of the underlying math, the [4] is equivalent to [0, 0, 0, 0, 1, 0, 0].
Out of Vocab (OOV)
Just as numerical data contains outliers, categorical data does, as well.By using OOV, the system won’t waste time training on each of those rare colors.
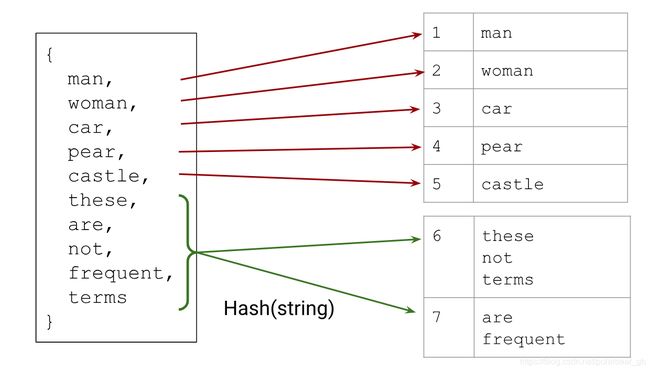
Hashing
Another option is to hash every string (category) into your available index space. Hashing often causes collisions, but you rely on the model learning some shared representation of the categories in the same index that works well for the given problem.
 For important terms, hashing can be worse than selecting a vocabulary, because of collisions. On the other hand, hashing doesn’t require you to assemble a vocabulary, which is advantageous if the feature distribution changes heavily over time.
For important terms, hashing can be worse than selecting a vocabulary, because of collisions. On the other hand, hashing doesn’t require you to assemble a vocabulary, which is advantageous if the feature distribution changes heavily over time.
Hybrid of Hashing and Vocabulary
You can take a hybrid approach and combine hashing with a vocabulary. Use a vocabulary for the most important categories in your data, but replace the OOV bucket with multiple OOV buckets, and use hashing to assign categories to buckets.
The categories in the hash buckets must share an index, and the model likely won’t make good predictions, but we have allocated some amount of memory to attempt to learn the categories outside of our vocabulary.
Note about Embeddings
Embedding is a categorical feature represented as a continuous-valued feature. Deep models frequently convert the indices from an index to an embedding.

The other transformations we’ve discussed could be stored on disk, but embeddings are different. Since embeddings are trained, they’re not a typical data transformation—they are part of the model. They’re trained with other model weights, and functionally are equivalent to a layer of weights.
What about pretrained embeddings? Pretrained embeddings are still typically modifiable during training, so they’re still conceptually part of the model.