PR10.10:#Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning
What’s problem?
Count-based exploration algorithms are known to perform near-optimally when used in conjunction with tabular reinforcement learning (RL) methods for solving small discrete Markov decision processes (MDPs).
What’s the STOA?
This paper proposes a generalization of classic count-based exploration to high-dimensional spaces through hashing; demonstrates its effectiveness on challenging deep RL benchmark problems and analyzes key components of well-designed hash functions.
What’s the proposed solution?
Count-Based Exploration via Static Hashing
Their approach discretizes the state space with a hash function ϕ : S→Z . An exploration bonus r+:S→R is added to the reward function.
where β∈R≥0 is the bonus coefficient.

Clearly the performance of this method will strongly depend on the choice of hash function ϕ .
补充:
(1) LSH的基本思想是:将原始数据空间中的两个相邻数据点通过相同的映射或投影变换(projection)后,这两个数据点在新的数据空间中仍然相邻的概率很大,而不相邻的数据点被映射到同一个桶的概率很小。也就是说,如果我们对原始数据进行一些hash映射后,我们希望原先相邻的两个数据能够被hash到相同的桶内,具有相同的桶号。对原始数据集合中所有的数据都进行hash映射后,我们就得到了一个hash table,这些原始数据集被分散到了hash table的桶内,每个桶会落入一些原始数据,属于同一个桶内的数据就有很大可能是相邻的,当然也存在不相邻的数据被hash到了同一个桶内。因此,如果我们能够找到这样一些hash functions,使得经过它们的哈希映射变换后,原始空间中相邻的数据落入相同的桶内的话,那么我们在该数据集合中进行近邻查找就变得容易了,我们只需要将查询数据进行哈希映射得到其桶号,然后取出该桶号对应桶内的所有数据,再进行线性匹配即可查找到与查询数据相邻的数据。换句话说,我们通过hash function映射变换操作,将原始数据集合分成了多个子集合,而每个子集合中的数据间是相邻的且该子集合中的元素个数较小,因此将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,显然计算量下降了很多。
(2) 那具有怎样特点的hash functions才能够使得原本相邻的两个数据点经过hash变换后会落入相同的桶内?这些hash function需要满足以下两个条件:
1)如果 d(x,y)≤d1 , 则h(x) = h(y)的概率至少为p1;
2)如果 d(x,y)≥d2 , 则h(x) = h(y)的概率至多为p2;
其中d(x,y)表示x和y之间的距离,d1 < d2, h(x)和h(y)分别表示对x和y进行hash变换。
满足以上两个条件的hash functions称为(d1,d2,p1,p2)-sensitive。而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table的过程称为Locality-sensitive Hashing。
也就是说,hash function起到了类似聚类的作用,将相近的state分到了同一个子集内,可见hash function的选取对效果有决定性的作用。
Simhash的基本原理:
以文本为例,先对文本进行特征提取,然后进行hash映射,再对哈希映射进行加权,然后将各个维度的特征求和,最后经过sgn函数得到最终结果。

Count-Based Exploration via Learned Hashing

By rounding the sigmoid output b(s) of this layer to the closest binary number, any state s can be binarized. Since gradients cannot be back-propagated through a rounding function, uniform noise U(−a,a) is added to the sigmoid output.
Feeding a state s to the AE input, extracting b(s) and rounding it to ⌊b(s)⌉ yields a learned binary code. As such, the loss function L(⋅) over a set of collected states {si}Ni=1 is defined as:
This objective function consists of a cross-entropy term and a term that pressures the binary code layer to take on binary values, scaled by λ∈R≥0 .

What’s the performance of the proposed solution?
这篇论文的实验做得非常充分!
Continuous Control
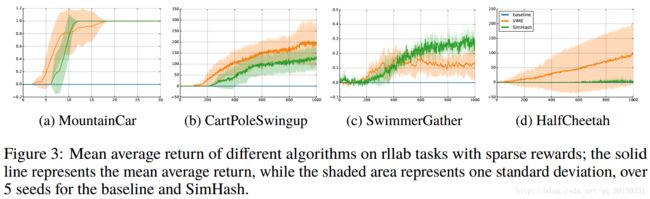
Using count-based exploration with hashing is capable of reaching the goal in all environments (which corresponds to a nonzero return), while baseline TRPO with Gaussian control noise fails completely. Although TRPO-SimHash picks up the sparse reward on HalfCheetah, it does not perform as well as VIME. In contrast, the performance of SimHash is comparable with VIME on MountainCar, while it outperforms VIME on SwimmerGather.
Arcade Learning Environment (ALE, Bellemare et al. (2013))
They propose using Basic Abstraction of the ScreenShots (BASS, also called Basic; see Bellemare et al. (2013)) as a static preprocessing function g .(See details in paper). And then they compared to AE hash function.

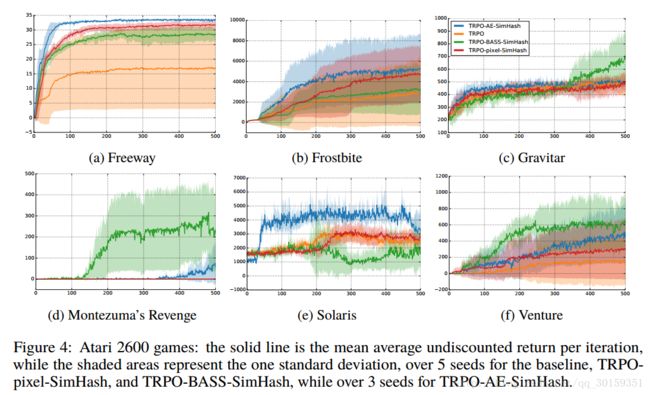
Granularity
Granularity plays a critical role in count-based exploration, where the hash function should cluster states without under-generalizing or over-generalizing. Table 2 summarizes granularity parameters for our hash functions. In Table 3 we summarize the performance of TRPO-pixel-SimHash under different granularities.

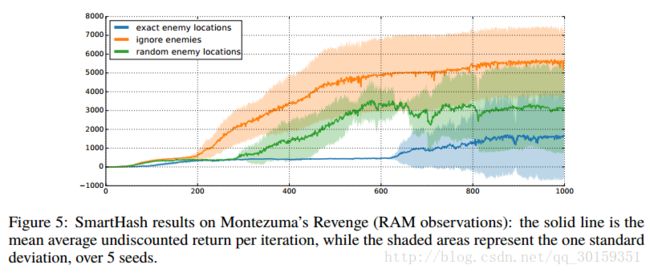
Montezuma’s Revenge
Montezuma’s Revenge is widely known for its extremely sparse rewards and difficult exploration.
(1)Their first attempt is to use game RAM states instead of image observations as inputs to the policy.
(2)Their second attempt is to manually design a hash function that incorporates domain knowledge, called SmartHash
(See details in paper.)
Conclusion
This paper demonstrates that a generalization of classical counting techniques through hashing is able to provide an appropriate signal for exploration, even in continuous and/or high-dimensional MDPs using function approximators, resulting in near state-of-the-art performance across benchmarks. It provides a simple yet powerful baseline for solving MDPs that require informed exploration.