【第二部分 图像处理】第3章 Opencv图像处理进阶【2 图像变换D-仿射变换】
2.5仿射变换
2.5.1 初识仿射变换
仿射变换(Affine Transformation或 Affine Map),又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间的过程。它保持了二维图形的“平直性”(即:直线经过变换之后依然是直线)和“平行性”(即:二维图形之间的相对位置关系保持不变,平行线依然是平行线,且直线上点的位置顺序不变)。
一个任意的仿射变换都能表示为乘以一个矩阵(线性变换)接着再加上一个向量(平移)的形式。那么, 我们能够用仿射变换来表示如下三种常见的变换形式:
·旋转,rotation (线性变换)
·平移,translation(向量加)
·缩放,scale(线性变换)
如果进行更深层次的理解,仿射变换代表的是两幅图之间的一种映射关系。而我们通常使用2 x 3的矩阵来表示仿射变换。
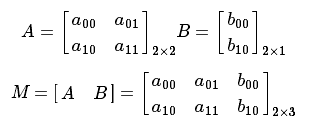
考虑到我们要使用矩阵 A 和 B 对二维向量 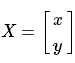 做变换, 所以也能表示为下列形式:
做变换, 所以也能表示为下列形式:
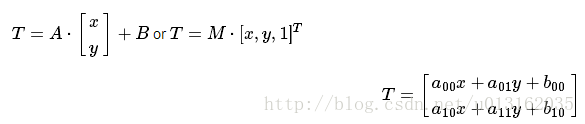
2.5.2仿射变换的求法
我们知道,仿射变换表示的就是两幅图片之间的一种联系 . 关于这种联系的信息大致可从以下两种场景获得:
<1>已知 X和T,而且我们知道他们是有联系的. 接下来我们的工作就是求出矩阵 M
<2>已知 M和X,要想求得 T. 我们只要应用算式 ![]() 即可. 对于这种联系的信息可以用矩阵 M 清晰的表达+即给出明确的2×3矩阵) 或者也可以用两幅图片点之间几何关系来表达。
即可. 对于这种联系的信息可以用矩阵 M 清晰的表达+即给出明确的2×3矩阵) 或者也可以用两幅图片点之间几何关系来表达。
我们形象地说明一下,因为矩阵 M 联系着两幅图片, 我们就以其表示两图中各三点直接的联系为例。
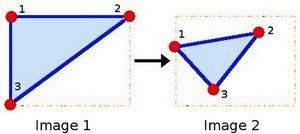
其中,点1, 2 和 3 (在图一中形成一个三角形) 与图二中三个点是一一映射的关系, 且他们仍然形成三角形, 但形状已经和之前不一样了。我们能通过这样两组三点求出仿射变换 (可以选择自己喜欢的点), 接着就可以把仿射变换应用到图像中去。
2.5.3仿射变换相关的函数使用
OpenCV仿射变换相关的函数一般涉及到warpAffine和getRotationMatrix2D这两个:
使用OpenCV函数warpAffine 来实现一些简单的重映射.
使用OpenCV函数getRotationMatrix2D 来获得旋转矩阵。
下面分别对其进行讲解。
<1> warpAffine函数详解
warpAffine函数的作用是依据如下式子,对图像做仿射变换。
函数原型如下:
C++: void warpAffine(InputArray src,
OutputArray dst,
InputArray M,
Size dsize,
int flags=INTER_LINEAR,
int borderMode=BORDER_CONSTANT,
const Scalar& borderValue=Scalar()) 【参数】
第一个参数,InputArray类型的src,输入图像,即源图像,填Mat类的对象即可。
第二个参数,OutputArray类型的dst,函数调用后的运算结果存在这里,需和源图片有一样的尺寸和类型。
第三个参数,InputArray类型的M,2×3的变换矩阵。
第四个参数,Size类型的dsize,表示输出图像的尺寸。
第五个参数,int类型的flags,插值方法的标识符。此参数有默认值INTER_LINEAR(线性插值),可选的插值方式如下:
·INTER_NEAREST - 最近邻插值
·INTER_LINEAR - 线性插值(默认值)
·INTER_AREA - 区域插值
·INTER_CUBIC –三次样条插值
·INTER_LANCZOS4 -Lanczos插值
· CV_WARP_FILL_OUTLIERS - 填充所有输出图像的象素。如果部分象素落在输入图像的边界外,那么它们的值设定为 fillval.
·CV_WARP_INVERSE_MAP –表示M为输出图像到输入图像的反变换,即 。因此可以直接用来做象素插值。否则, warpAffine函数从M矩阵得到反变换。
第六个参数,int类型的borderMode,边界像素模式,默认值为BORDER_CONSTANT。
第七个参数,const Scalar&类型的borderValue,在恒定的边界情况下取的值,默认值为Scalar(),即0。
另外提一点,我们的WarpAffine函数与一个叫做cvGetQuadrangleSubPix( )的函数类似,但是不完全相同。 WarpAffine要求输入和输出图像具有同样的数据类型,有更大的资源开销(因此对小图像不太合适)而且输出图像的部分可以保留不变。而 cvGetQuadrangleSubPix 可以精确地从8位图像中提取四边形到浮点数缓存区中,具有比较小的系统开销,而且总是全部改变输出图像的内容。
<2> getRotationMatrix2D
计算二维旋转变换矩阵。变换会将旋转中心映射到它自身。
C++: Mat getRotationMatrix2D( Point2f center,
double angle,
double scale) 【参数】
第一个参数,Point2f类型的center,表示源图像的旋转中心。
第二个参数,double类型的angle,旋转角度。角度为正值表示向逆时针旋转(坐标原点是左上角)。
第三个参数,double类型的scale,缩放系数。
此函数计算以下矩阵:

其中:
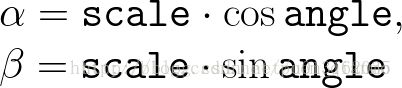
2.5.4仿射变换相关核心函数源代码
这个部分贴出OpenCV中本节相关函数的源码实现细节,笔者暂时不在源码的细节上挖深作详细注释。
2.5.4.1 OpenCV2.X中源代码
<1> OpenCV2.X中warpAffine函数源代码
首先,是warpAffine函数的实现源码。
void cv::warpAffine( InputArray _src,OutputArray _dst,
InputArray _M0, Sizedsize,
int flags, int borderType,const Scalar& borderValue )
{
Mat src = _src.getMat(), M0 = _M0.getMat();
_dst.create( dsize.area() == 0 ? src.size() : dsize, src.type() );
Mat dst = _dst.getMat();
CV_Assert( src.cols > 0 && src.rows > 0 );
if( dst.data == src.data )
src = src.clone();
double M[6];
Mat matM(2, 3, CV_64F, M);
int interpolation = flags & INTER_MAX;
if( interpolation == INTER_AREA )
interpolation = INTER_LINEAR;
CV_Assert( (M0.type() == CV_32F || M0.type() == CV_64F) &&M0.rows == 2 && M0.cols == 3 );
M0.convertTo(matM, matM.type());
#ifdef HAVE_TEGRA_OPTIMIZATION
if( tegra::warpAffine(src, dst, M, flags, borderType, borderValue) )
return;
#endif
if( !(flags & WARP_INVERSE_MAP) )
{
double D = M[0]*M[4] - M[1]*M[3];
D = D != 0 ? 1./D : 0;
double A11 = M[4]*D, A22=M[0]*D;
M[0] = A11; M[1] *= -D;
M[3] *= -D; M[4] = A22;
double b1 = -M[0]*M[2] - M[1]*M[5];
double b2 = -M[3]*M[2] - M[4]*M[5];
M[2] = b1; M[5] = b2;
}
int x;
AutoBuffer _abdelta(dst.cols*2);
int* adelta = &_abdelta[0], *bdelta = adelta + dst.cols;
const int AB_BITS = MAX(10, (int)INTER_BITS);
const int AB_SCALE = 1 << AB_BITS;
/*
#if defined (HAVE_IPP) &&(IPP_VERSION_MAJOR >= 7)
int depth = src.depth();
int channels = src.channels();
if( ( depth == CV_8U || depth == CV_16U ||depth == CV_32F ) &&
( channels == 1 || channels == 3 || channels == 4 ) &&
( borderType == cv::BORDER_TRANSPARENT || ( borderType ==cv::BORDER_CONSTANT ) ) )
{
int type = src.type();
ippiWarpAffineBackFunc ippFunc =
type == CV_8UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C1R :
type == CV_8UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C3R :
type == CV_8UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C4R :
type == CV_16UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C1R :
type == CV_16UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C3R :
type == CV_16UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C4R :
type == CV_32FC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C1R :
type == CV_32FC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C3R :
type == CV_32FC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C4R :
0;
int mode =
flags == INTER_LINEAR ? IPPI_INTER_LINEAR :
flags == INTER_NEAREST ? IPPI_INTER_NN :
flags == INTER_CUBIC ? IPPI_INTER_CUBIC :
0;
if( mode && ippFunc )
{
double coeffs[2][3];
for( int i = 0; i < 2; i++ )
{
for( int j = 0; j < 3; j++ )
{
coeffs[i][j] =matM.at(i, j);
}
}
bool ok;
Range range(0, dst.rows);
IPPwarpAffineInvoker invoker(src, dst, coeffs, mode, borderType,borderValue, ippFunc, &ok);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
if( ok )
return;
}
}
#endif
*/
for( x = 0; x < dst.cols; x++ )
{
adelta[x] = saturate_cast(M[0]*x*AB_SCALE);
bdelta[x] = saturate_cast(M[3]*x*AB_SCALE);
}
Range range(0, dst.rows);
warpAffineInvokerinvoker(src, dst, interpolation, borderType,
borderValue,adelta, bdelta, M);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
} <2> OpenCV2.X中getRotationMatrix2D函数源代码
cv::Mat cv::getRotationMatrix2D( Point2f center,double angle, double scale )
{
angle *= CV_PI/180;
double alpha = cos(angle)*scale;
double beta = sin(angle)*scale;
Mat M(2, 3, CV_64F);
double* m = (double*)M.data;
m[0] = alpha;
m[1] = beta;
m[2] = (1-alpha)*center.x - beta*center.y;
m[3] = -beta;
m[4] = alpha;
m[5] = beta*center.x + (1-alpha)*center.y;
return M;
} 2.5.4.2 OpenCV3.0中源代码
<1> OpenCV2.X中warpAffine函数源代码
首先,是warpAffine函数的实现源码。
/*【warpAffine ( )源代码】************************************************************
* @Version:OpenCV 3.0.0(Opnencv2和Opnencv3差别不大,Linux和PC的对应版本源码完全一样,均在对应的安装目录下)
* @源码路径:…\opencv\sources\modules\imgproc\src\ imgwarp.cpp
* @起始行数:5562行
********************************************************************************/
void cv::warpAffine( InputArray _src, OutputArray _dst,
InputArray _M0, Size dsize,
int flags, int borderType, const Scalar& borderValue )
{
CV_OCL_RUN(_src.dims() <= 2 && _dst.isUMat(),
ocl_warpTransform(_src, _dst, _M0, dsize, flags, borderType,
borderValue, OCL_OP_AFFINE))
Mat src = _src.getMat(), M0 = _M0.getMat();
_dst.create( dsize.area() == 0 ? src.size() : dsize, src.type() );
Mat dst = _dst.getMat();
CV_Assert( src.cols > 0 && src.rows > 0 );
if( dst.data == src.data )
src = src.clone();
double M[6];
Mat matM(2, 3, CV_64F, M);
int interpolation = flags & INTER_MAX;
if( interpolation == INTER_AREA )
interpolation = INTER_LINEAR;
CV_Assert( (M0.type() == CV_32F || M0.type() == CV_64F) && M0.rows == 2 && M0.cols == 3 );
M0.convertTo(matM, matM.type());
#ifdef HAVE_TEGRA_OPTIMIZATION
if( tegra::useTegra() && tegra::warpAffine(src, dst, M, flags, borderType, borderValue) )
return;
#endif
if( !(flags & WARP_INVERSE_MAP) )
{
double D = M[0]*M[4] - M[1]*M[3];
D = D != 0 ? 1./D : 0;
double A11 = M[4]*D, A22=M[0]*D;
M[0] = A11; M[1] *= -D;
M[3] *= -D; M[4] = A22;
double b1 = -M[0]*M[2] - M[1]*M[5];
double b2 = -M[3]*M[2] - M[4]*M[5];
M[2] = b1; M[5] = b2;
}
int x;
AutoBuffer _abdelta(dst.cols*2);
int* adelta = &_abdelta[0], *bdelta = adelta + dst.cols;
const int AB_BITS = MAX(10, (int)INTER_BITS);
const int AB_SCALE = 1 << AB_BITS;
#if defined (HAVE_IPP) && IPP_VERSION_MAJOR * 100 + IPP_VERSION_MINOR >= 801 && 0
CV_IPP_CHECK()
{
int type = src.type(), depth = CV_MAT_DEPTH(type), cn = CV_MAT_CN(type);
if( ( depth == CV_8U || depth == CV_16U || depth == CV_32F ) &&
( cn == 1 || cn == 3 || cn == 4 ) &&
( interpolation == INTER_NEAREST || interpolation == INTER_LINEAR || interpolation == INTER_CUBIC) &&
( borderType == cv::BORDER_TRANSPARENT || borderType == cv::BORDER_CONSTANT) )
{
ippiWarpAffineBackFunc ippFunc = 0;
if ((flags & WARP_INVERSE_MAP) != 0)
{
ippFunc =
type == CV_8UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C1R :
type == CV_8UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C3R :
type == CV_8UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_8u_C4R :
type == CV_16UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C1R :
type == CV_16UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C3R :
type == CV_16UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_16u_C4R :
type == CV_32FC1 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C1R :
type == CV_32FC3 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C3R :
type == CV_32FC4 ? (ippiWarpAffineBackFunc)ippiWarpAffineBack_32f_C4R :
0;
}
else
{
ippFunc =
type == CV_8UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffine_8u_C1R :
type == CV_8UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffine_8u_C3R :
type == CV_8UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffine_8u_C4R :
type == CV_16UC1 ? (ippiWarpAffineBackFunc)ippiWarpAffine_16u_C1R :
type == CV_16UC3 ? (ippiWarpAffineBackFunc)ippiWarpAffine_16u_C3R :
type == CV_16UC4 ? (ippiWarpAffineBackFunc)ippiWarpAffine_16u_C4R :
type == CV_32FC1 ? (ippiWarpAffineBackFunc)ippiWarpAffine_32f_C1R :
type == CV_32FC3 ? (ippiWarpAffineBackFunc)ippiWarpAffine_32f_C3R :
type == CV_32FC4 ? (ippiWarpAffineBackFunc)ippiWarpAffine_32f_C4R :
0;
}
int mode =
interpolation == INTER_LINEAR ? IPPI_INTER_LINEAR :
interpolation == INTER_NEAREST ? IPPI_INTER_NN :
interpolation == INTER_CUBIC ? IPPI_INTER_CUBIC :
0;
CV_Assert(mode && ippFunc);
double coeffs[2][3];
for( int i = 0; i < 2; i++ )
for( int j = 0; j < 3; j++ )
coeffs[i][j] = matM.at(i, j);
bool ok;
Range range(0, dst.rows);
IPPWarpAffineInvoker invoker(src, dst, coeffs, mode, borderType, borderValue, ippFunc, &ok);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
if( ok )
{
CV_IMPL_ADD(CV_IMPL_IPP|CV_IMPL_MT);
return;
}
setIppErrorStatus();
}
}
#endif
for( x = 0; x < dst.cols; x++ )
{
adelta[x] = saturate_cast(M[0]*x*AB_SCALE);
bdelta[x] = saturate_cast(M[3]*x*AB_SCALE);
}
Range range(0, dst.rows);
WarpAffineInvoker invoker(src, dst, interpolation, borderType,
borderValue, adelta, bdelta, M);
parallel_for_(range, invoker, dst.total()/(double)(1<<16));
} <2> OpenCV2.X中getRotationMatrix2D函数源代码
/*【getRotationMatrix2D ( )源代码】****************************************************
* @Version:OpenCV 3.0.0(Opnencv2和Opnencv3差别不大,Linux和PC的对应版本源码完全一样,均在对应的安装目录下)
* @源码路径:…\opencv\sources\modules\imgproc\src\ imgwarp.cpp
* @起始行数:6186行
********************************************************************************/
cv::Mat cv::getRotationMatrix2D( Point2f center, double angle, double scale )
{
angle *= CV_PI/180;
double alpha = cos(angle)*scale;
double beta = sin(angle)*scale;
Mat M(2, 3, CV_64F);
double* m = M.ptr();
m[0] = alpha;
m[1] = beta;
m[2] = (1-alpha)*center.x - beta*center.y;
m[3] = -beta;
m[4] = alpha;
m[5] = beta*center.x + (1-alpha)*center.y;
return M;
}2.5.5仿射变换实例
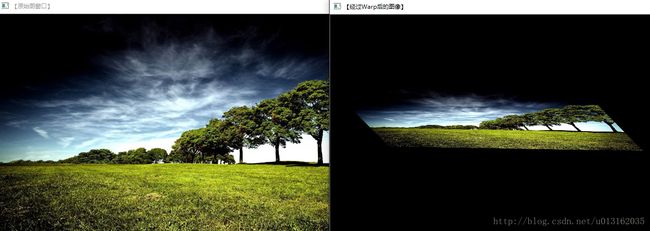
看完上面的讲解和函数实现,下面是一个以warpAffine和getRotationMatrix2D函数为核心的对图像进行仿射变换的示例程序。
代码参看附件【demo1】

参考:
中文链接
英文链接
本章参考附件
点击进入