计算机组成原理--main memory 到 cache 映射机制
基本介绍
为了平衡高速的CPU与较慢的主存之间的差异,我们引入到了cache作为中间媒介,cache的主要作用说来可以理解成将主存中很有可能被CPU使用的小部分数据调入cache中,由于cache是很快的,则可以对系统的系统有较大提升。相关详细情况可以参见计算机组成原理–cache概念及其作用。
这篇博客的主要任务是探讨Main memory到cache的多种映射机制,并讨论其优势与劣势,知道后期的使用。
目前已经投入使用的映射机制主要有以下三种:
- 直接映射(Direct Mapping)
- 全局关联映射(Fully Associative Mapping)
- 组关联映射(Set Associate Mapping)
以下将对三种分别进行介绍。
直接映射(Direct Mapping)
直接映射的直观表示图为:
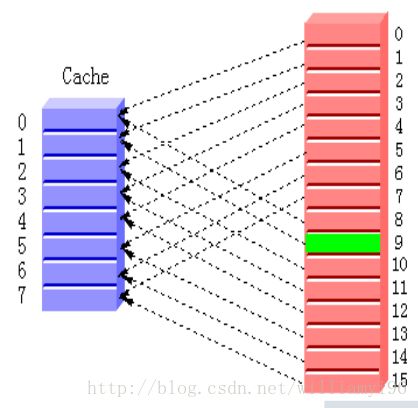
关于其设计实现是基于模数计算得到的。我们知道,cache的每一行与主存的一个块是相互对应的。
我们有如下公式:
i = j mod m其中j是主存块的编号,m是cache的行数,而i是主存中块映射到cache中的行编号。
接下来我们看一看直接映射的地址结构,如图所示:

其将24位的地址分为字地址,行数和标签。其中字数是由主存中块所包含的大小决定的(如此处word为2,假设每个地址空间有一个字节的数据,则一个块有四个字节)。
行数是根据实际条件进行确定的,将在之后的练习中具体说明。
而Tag的位数,则是有减法计算得到的。
我们可以很直观地看到,使用直接映射的方式实现起来相对而言较为方便,但是其劣势也是很大的一个问题,也就是thrashing(抖动)。 如图所示:
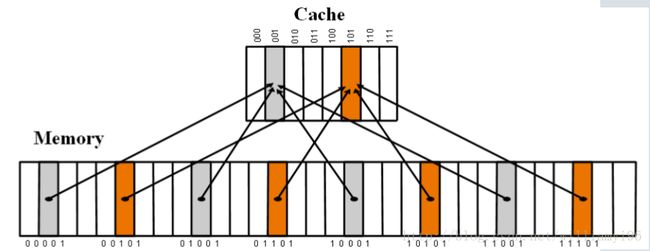
由于00001与01001的word位相同,因此其将被映射到cache的同一行,调用完成00001后,不命中,CPU去主存中取01001的块,然后10001也不命中,再去主存中取。则会大大浪费时间,因为不命中的时间消耗等于cache访问的消耗加上主存访问的消耗。
这也就是我们所说的抖动的现象。
全局关联映射(Fully Associate Mapping)
上面讲到的直接映射机制有着容易发生抖动致使CPU效率降低的现象,那么产生这种问题的根本原因是什么呢?不难发现,是我们将映射规则定义得太死板了,也就是存在主存和高速缓存之间的一一映射关系。
为了解决抖动的这一问题,我们引入了全局关联映射(Fully Associate Mapping)。其核心思想就是对于每一个块都可以放入任何一个cache中的行。
直观表示为:
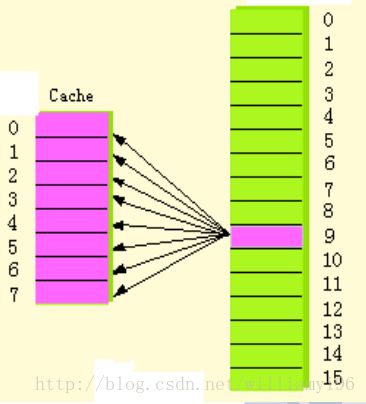 。
。
当cache还有空行时,对应的块直接填入其中的任意一个。当cache被填满时,则使用后面博客中会提到的替换算法来进行选择性填入。
全局关联映射的地址结构为:

我们可以看到tag位有22bit之多,因此实现起来的并行比较电路较为复杂,计算量较大,影响性能,同时这种复杂性就自然造成了成本的提升。
组关联映射(Set Associate Mapping)
直接映射的实现结构简单但是映射机制不够灵活,全局关联映射的映射机制灵活但是实现结构相对复杂。
那么我们能不能对两者进行折中呢?自然可以。这也便引出了组关联映射(Set Associate Mapping)的概念。
其是将多个块归类为一个组,同时将cache中的多行也化归为一组。主存中的组与cache中的组是对应的,也是采用的直接映射中模数的方式,只不过其模的m为cache中组的数量。
此外,主存中的数据导入到cache中仍然是采用块的方式,而且其导入的块可以放在对应组的任何一行,其思想来源便是全局关联映射。
组关联映射的直观表示为:
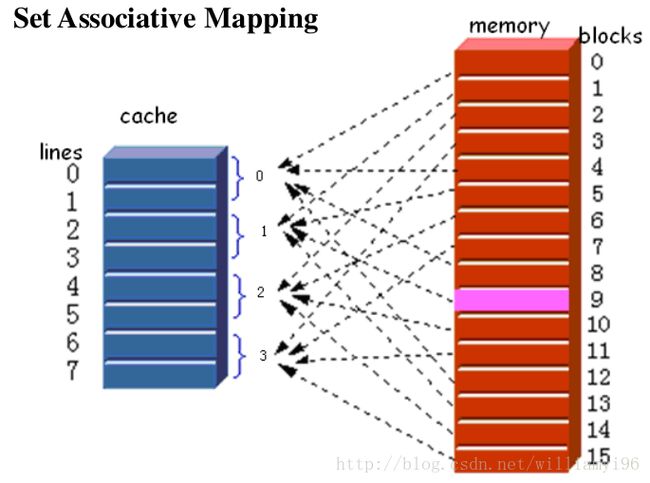
对应的,组关联映射的地址结构为:

其得到的方式与直接映射以及全局关联映射基本相同,此处便不再进行赘述。
实践证明,组的线数在2–8是在trade-off之下性能的最好状态。
总结
本文章讨论了主存到cache映射的三种机制。从直接映射,到全局关联映射,再到两者的折中,组关联映射。从宏观上对其进行了分析,对其思想进行了清晰的阐述。
特别感谢西安交通大学李晨老师为我们教授的计算机组成原理这门课,生动幽默,深入浅出。文中所有使用的图片均来自于李晨老师的课件,所有权归属于李晨老师。