Python---对html文件内容进行搜索取出特定URL地址字符串,保存成列表,并使用每个url下载图片,并保存到硬盘上,使用bs4,beautifulsoup模块
使用Python—对html文件内容进行搜索取出特定URL地址字符串,保存成列表,并使用每个url下载图片,并保存到硬盘上,bs4,beautifulsoup模块
建议:对html页面的返回内容信息,使用beautifulsoup模块非常高效。如果对txt,js的文件使用正则表达式高效
参考:https://cuiqingcai.com/1319.html
1、目标地址:https://xianzhi.aliyun.com/forum/topic/1805/
如下图中的内容
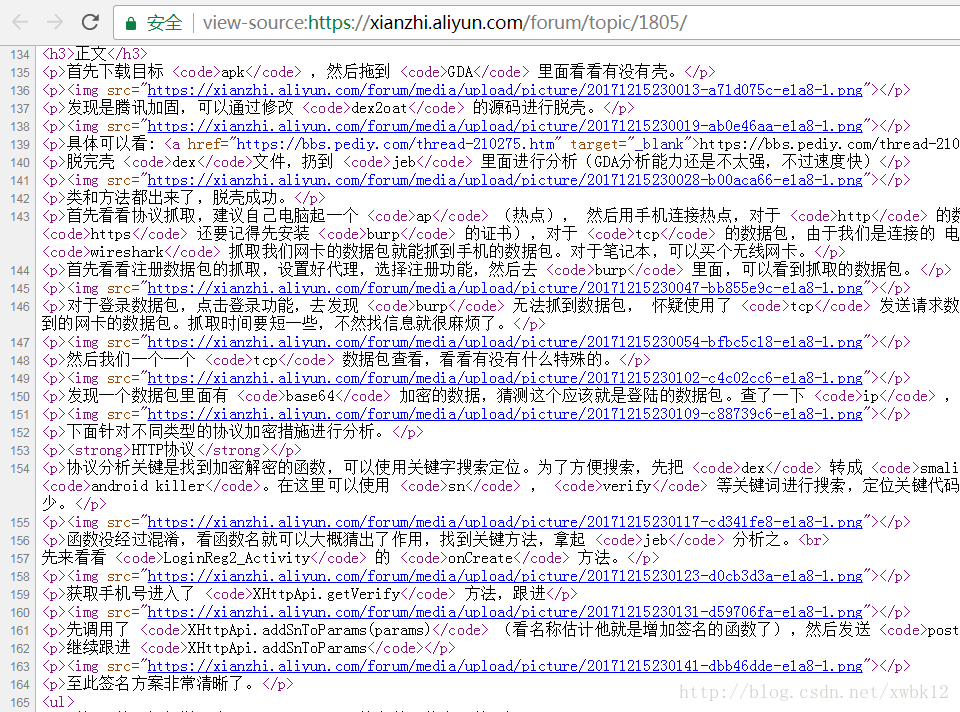
对目标回包内容取出这样类似的内容:
https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230019-ab0e46aa-e1a8-1.png2、python脚本,取目标地址的回包内容所有信息,并保存下来
import urllib
import urllib2
import ssl
def getpicyanzhengma():#实时请求服务器最新的验证码,并保存pic.png图片格式,与服务器互动
urlget = "https://xianzhi.aliyun.com/forum/topic/1805/"
#ctl = {"ctl":"code"}
#ctldata = urllib.urlencode(ctl)
#reqget = urllib2.Request(urlget+'?'+ctldata)#构造get请求与参数
reqget = urllib2.Request(urlget)#构造get请求与参数
#添加get请求的头信息
reqget.add_header("Host","xianzhi.aliyun.com")
reqget.add_header("Cache-Control","max-age=0")
reqget.add_header("Upgrade-Insecure-Requests","1")
reqget.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36")
reqget.add_header("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
reqget.add_header("Accept-Language","zh-CN,zh;q=0.8")
#reqget.add_header("Accept-Encoding","gzip, deflate, sdch, br")
reqget.add_header("Cookie","cnz=X6ejEtcUBVMCAfJ77XgdkdPH; cna=YKejEpKOFU0CAXjte/LuiuWB; UM_distinctid=16000343ca4183-0e8093cc5e7b3-64191279-15f900-16000343ca575a; _uab_collina=151183659981086744617448; _ga=GA1.2.668866163.1511831906; aliyun_country=CN; aliyun_site=CN; isg=ApmZtNphJydPxfuAkp4Fb9c1qIWzjqX8QOIT1rtOAUA_wrlUA3adqAfSsrFO; _umdata=ED82BDCEC1AA6EB94F984760A4C6465E6DD138CC3777AF0CB131A783FCB0E006227E021A199C6A8DCD43AD3E795C914C3303D9E6CB380052D470743247B79D15; acw_tc=AQAAAJMuFXttQgkA8nvteBqARscCdcug; csrftoken=CkpJbhBYBvg6oTBvrwTrsrYcsF1SJXC4mdv0A0k1BmX6mDFT0K2izVlfJkaZI4zx; CNZZDATA1260716569=1195371503-1511830276-https%253A%252F%252Fwww.baidu.com%252F%7C1515457887")
reqget.add_header("Connection","keep-alive")
#使用本机进行代理抓包,查看详细的数据包
#proxy_handler = urllib2.ProxyHandler({'http': '192.168.40.36:4455'})
#opener = urllib2.build_opener(proxy_handler)
#urllib2.install_opener(opener)
context = ssl._create_unverified_context()#启用ssl。如果是http的话此行去除
resget = urllib2.urlopen(reqget,context=context)#在urllib2启用ssl字段,打开请求的数据。如果是http的话此context=context字段删除
resgetdata = resget.read()
print resgetdata
#对get请求的数据回包的图片验证码数据,保存为pic.png的图片
f = open("e:/pic/downloadxianzhi.html","wb")
f.write(resgetdata)
f.close()
getpicyanzhengma()3.1、对downloadxianzhi.html文件中的“https://……png”所有内容变成列表取出
root@kali:~/python/dinpay# cat findimg.py
#!/usr/bin/python
# --*-- coding:utf-8 --*--
from bs4 import BeautifulSoup
html = open("e:/pic/downloadxianzhi.html","rb")
soup = BeautifulSoup(html)
textlist = soup.find_all("img")#img必须为html的tag标签
#print type(textlist)
print textlist
html.close()
root@kali:~/python/dinpay# 3.2、脚本运行情况,生成列表
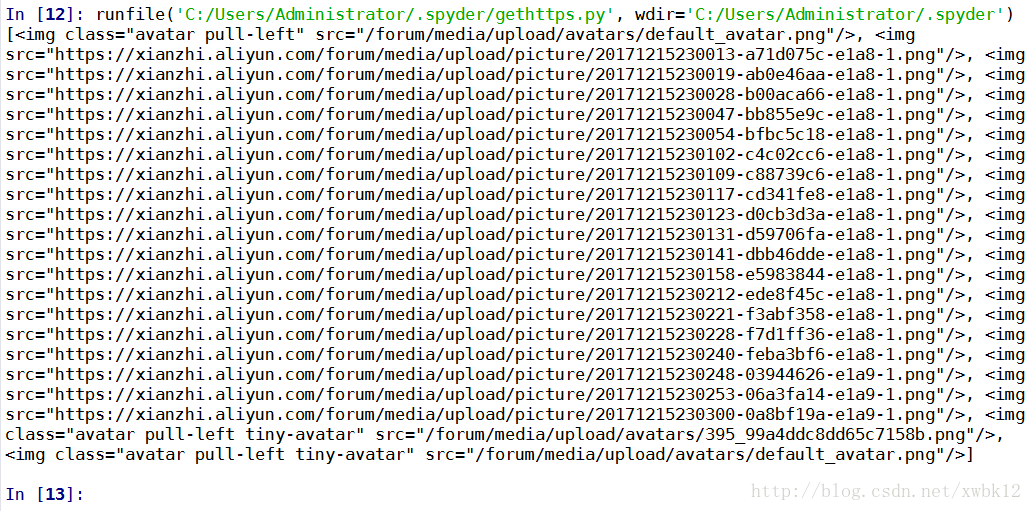
<class 'bs4.element.ResultSet'>
[<img class="avatar pull-left" src="/forum/media/upload/avatars/default_avatar.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230013-a71d075c-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230019-ab0e46aa-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230028-b00aca66-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230047-bb855e9c-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230054-bfbc5c18-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230102-c4c02cc6-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230109-c88739c6-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230117-cd341fe8-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230123-d0cb3d3a-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230131-d59706fa-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230141-dbb46dde-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230158-e5983844-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230212-ede8f45c-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230221-f3abf358-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230228-f7d1ff36-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230240-feba3bf6-e1a8-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230248-03944626-e1a9-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230253-06a3fa14-e1a9-1.png"/>, <img src="https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230300-0a8bf19a-e1a9-1.png"/>, <img class="avatar pull-left tiny-avatar" src="/forum/media/upload/avatars/395_99a4ddc8dd65c7158b.png"/>, <img class="avatar pull-left tiny-avatar" src="/forum/media/upload/avatars/default_avatar.png"/>]4.1、脚本
from bs4 import BeautifulSoup
html = open("e:/pic/downloadxianzhi.html","rb")
soup = BeautifulSoup(html)
textlist = soup.find_all("img")#img必须为html的tag标签
#print type(textlist)
print str(textlist[1])[10:-3]#把bs4类型的数据强制转换成字符串
html.close()4.2、运行情况
https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230013-a71d075c-e1a8-1.png5.1、脚本优化
from bs4 import BeautifulSoup
httplist = []#存放URL的地址列表
html = open("e:/pic/downloadxianzhi.html","rb")
soup = BeautifulSoup(html)
textlist = soup.find_all("img")#img必须为html的tag标签
#print type(textlist)
#print textlist
print len(textlist)
for n in range(1,len(textlist)-2):
url = str(textlist[n])[10:-3]#把bs4类型的数据强制转换成字符串
httplist.append(url)#把每次遍历到的https的url地址加入列表中
print httplist
html.close()5.2、
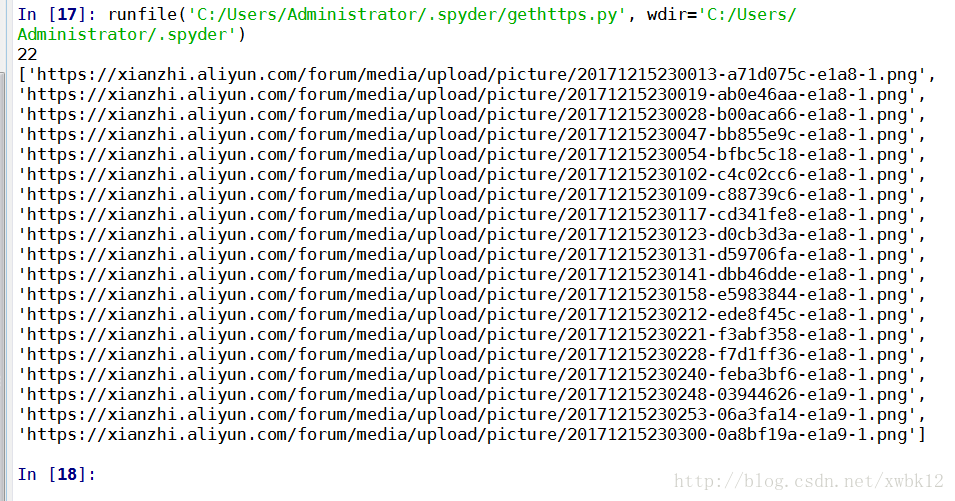
22
['https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230013-a71d075c-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230019-ab0e46aa-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230028-b00aca66-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230047-bb855e9c-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230054-bfbc5c18-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230102-c4c02cc6-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230109-c88739c6-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230117-cd341fe8-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230123-d0cb3d3a-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230131-d59706fa-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230141-dbb46dde-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230158-e5983844-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230212-ede8f45c-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230221-f3abf358-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230228-f7d1ff36-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230240-feba3bf6-e1a8-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230248-03944626-e1a9-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230253-06a3fa14-e1a9-1.png', 'https://xianzhi.aliyun.com/forum/media/upload/picture/20171215230300-0a8bf19a-e1a9-1.png']6、最终的完善的python代码信息
目的是对这个页面的URL地址的图片进行下载
import urllib
import urllib2
import ssl
from bs4 import BeautifulSoup
import os
import time
import string
def gethttpspagerepsone():#获取目标网页返回数据
urlget = "https://xianzhi.aliyun.com/forum/topic/1805/"
#ctl = {"ctl":"code"}
#ctldata = urllib.urlencode(ctl)
#reqget = urllib2.Request(urlget+'?'+ctldata)#构造get请求与参数
reqget = urllib2.Request(urlget)#构造get请求与参数
#添加get请求的头信息
reqget.add_header("Host","xianzhi.aliyun.com")
reqget.add_header("Cache-Control","max-age=0")
reqget.add_header("Upgrade-Insecure-Requests","1")
reqget.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36")
reqget.add_header("Accept","text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8")
reqget.add_header("Accept-Language","zh-CN,zh;q=0.8")
#reqget.add_header("Accept-Encoding","gzip, deflate, sdch, br")
reqget.add_header("Cookie","cnz=X6ejEtcUBVMCAfJ77XgdkdPH; cna=YKejEpKOFU0CAXjte/LuiuWB; UM_distinctid=16000343ca4183-0e8093cc5e7b3-64191279-15f900-16000343ca575a; _uab_collina=151183659981086744617448; _ga=GA1.2.668866163.1511831906; aliyun_country=CN; aliyun_site=CN; isg=ApmZtNphJydPxfuAkp4Fb9c1qIWzjqX8QOIT1rtOAUA_wrlUA3adqAfSsrFO; _umdata=ED82BDCEC1AA6EB94F984760A4C6465E6DD138CC3777AF0CB131A783FCB0E006227E021A199C6A8DCD43AD3E795C914C3303D9E6CB380052D470743247B79D15; acw_tc=AQAAAJMuFXttQgkA8nvteBqARscCdcug; csrftoken=CkpJbhBYBvg6oTBvrwTrsrYcsF1SJXC4mdv0A0k1BmX6mDFT0K2izVlfJkaZI4zx; CNZZDATA1260716569=1195371503-1511830276-https%253A%252F%252Fwww.baidu.com%252F%7C1515457887")
reqget.add_header("Connection","keep-alive")
#使用本机进行代理抓包,查看详细的数据包
#proxy_handler = urllib2.ProxyHandler({'http': '192.168.40.36:4455'})
#opener = urllib2.build_opener(proxy_handler)
#urllib2.install_opener(opener)
context = ssl._create_unverified_context()#启用ssl。如果是http的话此行去除
resget = urllib2.urlopen(reqget,context=context)#在urllib2启用ssl字段,打开请求的数据。如果是http的话此
resgetdata = resget.read()
print resgetdata
#对get请求的数据回包的图片验证码数据,保存为pic.png的图片
f = open("e:/pic/downloadxianzhi.html","wb")
f.write(resgetdata)
f.close()
def getpageurl():#对目标网页的返回数据筛选,筛选出URL的列表信息
html = open("e:/pic/downloadxianzhi.html","rb")#打开网页返回的数据
soup = BeautifulSoup(html)#定义soup
textlist = soup.find_all("img")#img必须为html的tag标签,查找特定数据
#print type(textlist)
#print textlist
#print len(textlist)
for n in range(1,len(textlist)-2):
url = str(textlist[n])[10:-3]#把bs4类型的数据强制转换成字符串
httplist.append(url)#把每次遍历到的https的url地址加入列表中
html.close()
def downloadpic():#对筛选出的url列表每个数据,进行指定请求下载相关图片
pwd = os.path.exists("e:/pic")
if pwd:#判断文件夹是否存在,如果不存在则创建
print "File Exist!!!"
else:
os.mkdir("e:/pic")
#下载指定的图片文件,并保存
for i in range(0,len(httplist)):
pic_url = httplist[i]#请求每个图片生成页面的地址
context = ssl._create_unverified_context()#启用ssl。如果是http的话此行去除
pic_data_url = urllib2.urlopen(pic_url,context=context)#在urllib2启用ssl字段,打开请求的数据。如果是http的话此行去除字段context=context
pic_data = pic_data_url.read()#读取页面返回的图片
localtime = time.strftime("%Y%m%d%H%M%S",time.localtime())
filename = "e:/pic/"+localtime+".png"#文件名格式
f = open(filename,"wb")
f.write(pic_data)
f.close()
print "file"+" "+str(i)+":"+str(localtime)+".png"
time.sleep(1)#暂停一秒
print "save ok!"
if __name__ == "__main__":
gethttpspagerepsone()
httplist = []#存放请求到的URL地址列表
getpageurl()
print httplist
downloadpic() 6.2,完善版运行情况:代码执行速度很慢
