第二章:Business Problems and Data Science Solutions(业务问题以及数据科学方案)
P24-P27
Supervised Versus Unsupervised Methods
监督学习和非监督学习方法
Consider two similar questions we might ask about a customer population. The first is: “Do our customers naturally fall into different groups?” Here no specific purpose or target has been specified for the grouping. When there is no such target, the data mining problem is referred to as unsupervised. Contrast this with a slightly different question: “Can we find groups of customers who have particularly high likelihoods of canceling their service soon after their contracts expire?” Here there is a specific target defined: will a customer leave when her contract expires? In this case, segmentation is being done for a specific reason: to take action based on likelihood of churn. This is called a supervised data mining problem.
考虑下述两种与客户群体相关的数据问题。第一个问题是:“我们的客户会自然分成不同的群体吗?”“这里没有为分组指定特定的目的或目标。当没有这样的目标时,数据挖掘问题被称为无监督分类问题。与此相反的是另一个稍微不同的问题:“我们可以找到那些在合同期满后很快取消服务的客户群吗?“,这里有一个明确的分组目标:当合同到期时,客户会取消合同吗?在这种情况下,因特定的原因而进行的细分:根据流失的可能性而进行的分析。这称为有监督分类问题。
这些问题之间的区别很微妙,但很重要。如果可以提供一个特定的分类目标,这个问题可以表述为一个监督问题。监督任务需要不同于无监督任务的技术,但是结果通常更有用。监督技术提供了特殊的分组目标——预测目标分组。聚类是一种无监督的任务,它基于相似性产生分组,但不能保证这些相似性是有意义的,或者对于任何特定用途都是有用的。
The difference between these questions is subtle but important. If a specific target can be provided, the problem can be phrased as a supervised one. Supervised tasks require different techniques than unsupervised tasks do, and the results often are much more useful. A supervised technique is given a specific purpose for the grouping—predicting the target. Clustering, an unsupervised task, produces groupings based on similarities, but there is no guarantee that these similarities are meaningful or will be useful for any particular purpose.
从技术上讲,监督数据挖掘必须满足另一个条件:目标上必须有明确的数据(也就是需要相应的训练集)。目标信息在原则上存在是不够的,它也必须存在于数据中(训练集需要有明确的标记)。例如,了解给定的客户是否会停留至少六个月可能是有用的,但如果在历史数据中,保存的历史信息出现丢失或不完整(如果数据只保留两个月),则无法提供目标值(无法明确的知道哪些历史客户是停留过六个月)(训练集不完整)。对于数据科学研究来说获取目标数据通常是很重要的一个步骤。个体的目标变量的值通常称为个体的标签,而这些标签通常是需要在进行数据分析前对数据进行处理,标记。
Classification, regression, and causal modeling generally are solved with supervised methods. Similarity matching, link prediction, and data reduction could be either. Clustering, co-occurrence grouping, and profiling generally are unsupervised. The fundamental principles of data mining that we will present underlie all these types of technique.
分类、回归和因果建模一般用监督方法来解决。相似性匹配、链接预测和数据约简的问题一般也是用监督方法进行处理。聚类、共生分组和概要分析通常是无监督的。我们将提出的数据挖掘的基本原则是所有这些技术的基础。
Two main subclasses of supervised data mining, classification and regression, are distinguished by the type of target. Regression involves a numeric target while classification involves a categorical (often binary) target. Consider these similar questions we might address with supervised data mining: “Will this customer purchase service S1 if given incentive I?” This is a classification problem because it has a binary target (the customer either purchases or does not). “Which service package (S1, S2, or none) will a customer likely purchase if given incentive I?” This is also a classification problem, with a three-valued target. “How much will this customer use the service?” This is a regression problem because it has a numeric target. The target variable is the amount of usage (actual or predicted) per customer.
有监督数据挖掘的两个主要子类,分类和回归,其主要是由目标类型区分的。回归涉及一个数字连续性目标,而分类涉及一个分类(通常是二进制)目标。考虑我们可能在监督类数据挖掘中处理的问题:
“如果给予激励,这个客户是否会购买服务S1?”
这是一个分类问题,因为它有二进制目标(客户购买或不购买)。
“如果给予激励,客户可能会购买哪种服务包(S1,S2,否)?”
这也是一个三重目标的分类问题。
“这个客户将使用多少服务?”
这是一个回归问题,因为它有一个数字目标。 目标变量是每个客户的使用量(实际或预测)。
There are subtleties among these questions that should be brought out. For business applications we often want a numerical prediction over a categorical target. In the churn example, a basic yes/no prediction of whether a customer is likely to continue to subscribe to the service may not be sufficient; we want to model the probability that the customer will continue. This is still considered classification modeling rather than regression because the underlying target is categorical. Where necessary for clarity, this is called “class probability estimation.”
在这些问题中存在一些需要注意的细节, 对于商业应用,我们经常希望对分类目标进行数值预测。 比如在客户流失示例中,利用基本的 是/否 来预测客户是否有可能继续订阅服务可能还不足够; 我们想模拟客户将继续使用的概率。 这仍然被认为是分类建模而不是回归问题,因为基础目标是分类的。为了更加精准的定义这个问题,通常这被称为“类概率估计”问题。
A vital part in the early stages of the data mining process is (i) to decide whether the line of attack will be supervised or unsupervised, and (ii) if supervised, to produce a precise definition of a target variable. This variable must be a specific quantity that will be the focus of the data mining (and for which we can obtain values for some example data). We will return to this in Chapter 3.
在数据挖掘过程的早期阶段,比较重要的部分是:
(i)明确被研究问题是监督还是无监督问题,
(ii)如果是监督性问题,需要确定目标变量的精确定义。 这个变量必须是一个特定的数量,这是监督性数据分析的重点(我们可以为此获取某些示例数据的值),之后我们将会第三章来详细讨论这方面的问题。
Data Mining and Its Results
数据挖掘及其结果
There is another important distinction pertaining to mining data: the difference between (1) mining the data to find patterns and build models, and (2) using the results of data mining. Students often confuse these two processes when studying data science, and managers sometimes confuse them when discussing business analytics. The use of data mining results should influence and inform the data mining process itself, but the two should be kept distinct
在数据挖掘中存在着另外一种比较重要的差别:以寻找相关数据模式和构建数据模型而进行的数据挖掘,和为了得到并使用数据挖掘结果而进行的数据挖掘。学习数据处理相关的科学知识时,学生经常会混淆这两个过程,而在讨论业务分析时,管理者有时会混淆这些过程。 数据挖掘结果的使用应该影响和反作用于数据挖掘过程本身,但两者应该保持不同。
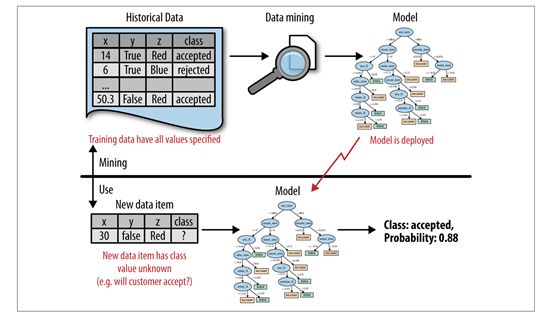
In our churn example, consider the deployment scenario in which the results will be used. We want to use the model to predict which of our customers will leave. Specifically, assume that data mining has created a class probability estimation model M. Given each existing customer, described using a set of characteristics, M takes these characteristics as input and produces a score or probability estimate of attrition. This is the use of the results of data mining. The data mining produces the model M from some other, often historical, data.
考虑一下上述使用数据挖掘结果的方案并应用在之前所提到的客户流失的案例中。比如我们想使用该模型来预测我们的哪些客户会流失。具体地说,假设数据挖掘已经创建了一个类概率估计模型M。给定每个现有客户,使用一组特征描述,M将这些特征作为输入,并产生一个分数或概率来预测客户的流失。这就是使用数据挖掘结果的例子。其中模型M通过数据挖掘并使用相关的历史数据而产生的。
Figure 2-1 illustrates these two phases. Data mining produces the probability estimation model, as shown in the top half of the figure. In the use phase (bottom half), the model is applied to a new, unseen case and it generates a probability estimate for it.
图2-1说明了这两个阶段。 如图的上半部分所示数据挖掘产生概率估计模型。 在使用阶段(下半部分),该模型被应用于一个新的,不可见的样本,并且它为其生成概率估计。
The Data Mining Process
数据挖掘过程
Data mining is a craft. It involves the application of a substantial amount of science and technology, but the proper application still involves art as well. But as with many mature crafts, there is a well-understood process that places a structure on the problem, allowing reasonable consistency, repeatability, and objectiveness. A useful codification of the data mining process is given by the Cross Industry Standard Process for Data Mining (CRISP-DM; Shearer, 2000), illustrated in Figure 2-2
数据挖掘是一种工艺。 它涉及大量的科学和技术的应用,但是如何合理的使用它仍然是一门艺术。 但是与许多成熟的工艺一样,there is a well-understood process that places a structure on the problem, allowing reasonable consistency, repeatability, and objectiveness。 数据挖掘过程是由跨行业数据挖掘标准流程(CRISP-DM; Shearer,2000)给出,如下图2-2所示:
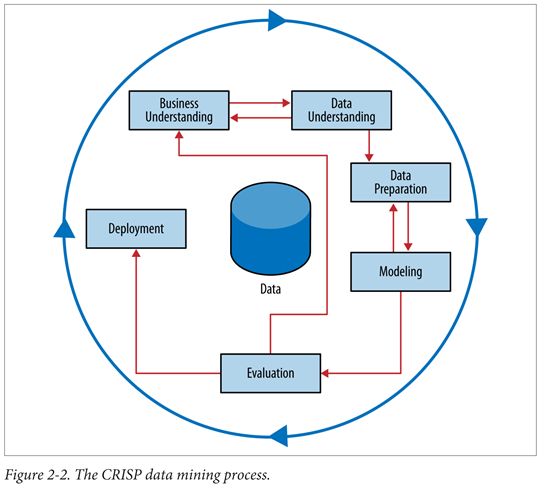
This process diagram makes explicit the fact that iteration is the rule rather than the exception. Going through the process once without having solved the problem is, generally speaking, not a failure. Often the entire process is an exploration of the data, and after the first iteration the data science team knows much more. The next iteration can be much more well-informed. Let’s now discuss the steps in detail.
这个过程图显示了反复的进行数据循环分析,这是数据分析很重要的一个过程,而并不是一种异常。如果一个问题没有立即解决,一般来说,这并不是一种失败,因为整个过程通常是对数据的探索,在第一次迭代之后,数据科学团队能够知道的更多,下一次迭代可以更加清楚。 现在来详细讨论这些步骤。