shardingjdbc 学习(四)-SQL路由实现
一 序
上一篇整理了jdbc的过程 ,update大概分两步,route跟执行。查询还有结果集归并。
上面本篇继续从路由开始整理。大概分为:分库分表整体,route包源码分析。
本文主要基于shardingjdbc 2.0.3版本整理。感谢芋道源码:http://www.iocoder.cn/Sharding-JDBC/sql-route-2/
二 分库分表:
这一部分算是第二篇API的补充吧。假设你阅读本文的时候已经熟悉相关概念或者阅读过官网的手册。
2.1 tablerule: rule包下面
表规则配置对象
public TableRule(final String logicTable, final List actualDataNodes, final Map dataSourceMap,
final ShardingStrategy databaseShardingStrategy, final ShardingStrategy tableShardingStrategy,
final String generateKeyColumn, final KeyGenerator keyGenerator, final String logicIndex) {
this.logicTable = logicTable.toLowerCase();
this.actualDataNodes = null == actualDataNodes || actualDataNodes.isEmpty() ? generateDataNodes(logicTable, dataSourceMap) : generateDataNodes(actualDataNodes, dataSourceMap);
this.databaseShardingStrategy = databaseShardingStrategy;
this.tableShardingStrategy = tableShardingStrategy;
this.generateKeyColumn = generateKeyColumn;
this.keyGenerator = keyGenerator;
this.logicIndex = null == logicIndex ? null : logicIndex.toLowerCase();
} 有TableRuleConfiguration.build生成tablerule
2.2 DataNode 分库分表数据单元
private List generateDataNodes(final String logicTable, final Map dataSourceMap) {
List result = new LinkedList<>();
for (String each : dataSourceMap.keySet()) {
result.add(new DataNode(each, logicTable));//逻辑表
}
return result;
}
//物理表
private List generateDataNodes(final List actualDataNodes, final Map dataSourceMap) {
List result = new LinkedList<>();
for (String each : actualDataNodes) {
DataNode dataNode = new DataNode(each);
Preconditions.checkArgument(dataSourceMap.containsKey(dataNode.getDataSourceName()), String.format("Cannot find data source in sharding rule, invalid actual data node is: '%s'", each));
result.add(dataNode);
}
return result;
} public DataNode(final String dataNode) {
Preconditions.checkArgument(DataNode.isValidDataNode(dataNode), String.format("Invalid format for actual data nodes: '%s'", dataNode));
List segments = Splitter.on(DELIMITER).splitToList(dataNode);
dataSourceName = segments.get(0);
tableName = segments.get(1);
} datanode 配置为 ${dataSourceName}.${tableName} 时。获取根据“.”截取数据源名称,表名。
2.3 shardingrule
分库分表规则配置对象,包含如下属性:
public final class ShardingRule {
private final Map dataSourceMap;
private final String defaultDataSourceName;
private final Collection tableRules;
private final Collection bindingTableRules = new LinkedList<>();
private final ShardingStrategy defaultDatabaseShardingStrategy;
private final ShardingStrategy defaultTableShardingStrategy;
private final KeyGenerator defaultKeyGenerator; tableRules 分表规则
BindingTableRule Binding表规则配置对象.
defaultDatabaseShardingStrategy 默认分库策略
defaultTableShardingStrategy 默认分表策略
defaultKeyGenerator 主键生成
this.defaultDatabaseShardingStrategy = null == defaultDatabaseShardingStrategy ? new NoneShardingStrategy() : defaultDatabaseShardingStrategy;
this.defaultTableShardingStrategy = null == defaultTableShardingStrategy ? new NoneShardingStrategy() : defaultTableShardingStrategy;构造方法里面,没有分库分表策略,则 使用 NoneShardingStrategy
三 SQL路由
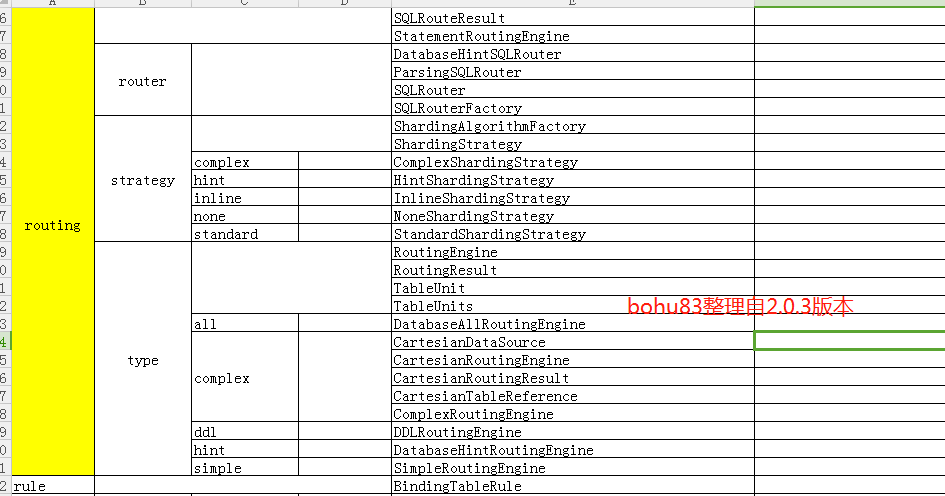
整体源码包结构
3.1 SQLRouteResult
经过 SQL解析、SQL路由后,产生SQL路由结果,即 SQLRouteResult。根据路由结果,生成SQL,执行SQL。

public final class SQLRouteResult {
private final SQLStatement sqlStatement;
private final Set executionUnits = new LinkedHashSet<>();
private final List generatedKeys = new LinkedList<>();
} executionUnits :SQL最小执行单元集合。SQL执行时,执行每个单元。
generatedKeys :插入SQL语句生成的主键编号集合
3.2 分库分表策略
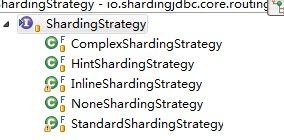
举个例子:StandardShardingStrategy
@SuppressWarnings("unchecked")
private Collection doSharding(final Collection availableTargetNames, final ListShardingValue shardingValue) {
Collection result = new LinkedList<>();
for (PreciseShardingValue each : transferToPreciseShardingValues(shardingValue)) {
result.add(preciseShardingAlgorithm.doSharding(availableTargetNames, each));
}
return result;
} 可见具体的实现有算法的dosharding来实现。shardingjdbc支持的具体的算法如下:
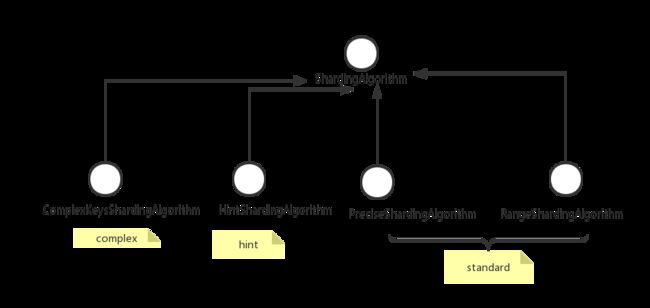
3.3 路由流程
本图来自与芋道源码整理
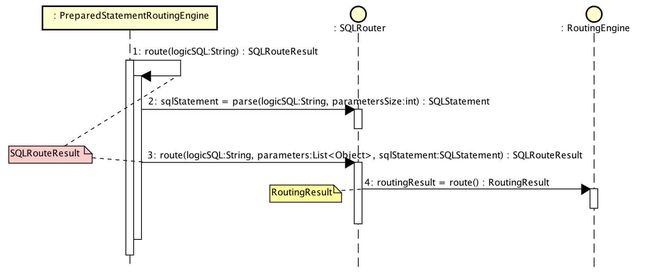
public SQLRouteResult route(final List也是PreparedStatementRoutingEngine的核心方法route。
SQLRouter,SQL 路由器接口,共有两种实现:
DatabaseHintSQLRouter:通过提示且仅路由至数据库的SQL路由器
ParsingSQLRouter:需要解析的SQL路由器
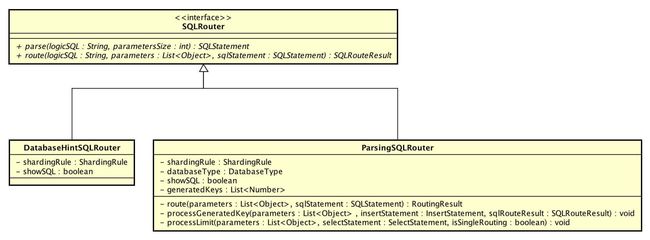
它们实现 #parse()进行SQL解析,#route()进行SQL路由。
RoutingEngine,路由引擎接口,共有6种实现:
后面在细说下对应的内部实现。
由结果有两种:
RoutingResult:简单路由结果 CartesianRoutingResult:笛卡尔积路由结果
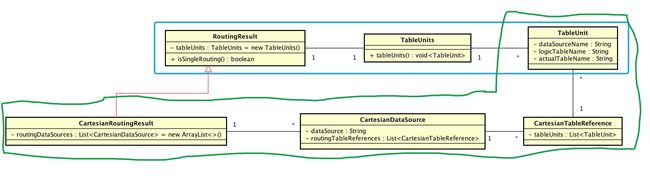
SQLRouteResult 和 RoutingResult 有什么区别?
SQLRouteResult:整个SQL路由返回的路由结果
RoutingResult:RoutingEngine返回路由结果
***********************
DatabaseHintSQLRouter 是基于hint的,这里不展开,以后单独整理hint的时候梳理下。下面说一下ParsingSQLRouter
4 ParsingSQLRouter
ParsingSQLRouter,需要解析的SQL路由器。ParsingSQLRouter 使用 SQLParsingEngine 解析SQL。
@Override
public SQLStatement parse(final String logicSQL, final int parametersSize) {
SQLParsingEngine parsingEngine = new SQLParsingEngine(databaseType, logicSQL, shardingRule);
SQLStatement result = parsingEngine.parse();
if (result instanceof InsertStatement) {
((InsertStatement) result).appendGenerateKeyToken(shardingRule, parametersSize);
}
return result;
} private RoutingResult route(final ListParsingSQLRouter 在路由时,会根据表情况使用不同的路由引擎:
DDLRoutingEngine DDL 这种比较少 DatabaseAllRoutingEngine 表名为空的情况
SimpleRoutingEngine 如果sql中只有一个表名,或者多个表名之间是绑定表关系,或者所有表都在默认数据源指定的数据库中(即不参与分库分表的表),那么用SimpleRoutingEngine作为路由判断引擎;(多表互为BindingTable关系时,每张表的路由结果是相同的,所以只要计算第一张表的分片即可。isAllBindingTables可以看看源码怎么判断的,比较长)
其他为ComplexRoutingEngine。
下面说一下常见的两种引擎类型:
4.1 SimpleRoutingEngine
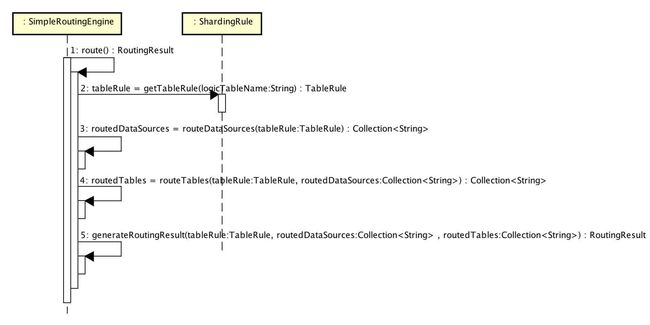
@Override
public RoutingResult route() {
// 根据逻辑表得到tableRule
TableRule tableRule = shardingRule.getTableRule(logicTableName);
// 根据规则先路由数据源:即根据shardingkey取模路由
Collection routedDataSources = routeDataSources(tableRule);
// routedMap保存路由到的目标数据源和表的结果:key为数据源,value为该数据源下路由到的目标表集合
Map> routedMap = new LinkedHashMap<>(routedDataSources.size());
// 遍历路由到的目标数据源
for (String each : routedDataSources) {
// 再根据规则路由表:即根据shardingkey取模路由
routedMap.put(each, routeTables(tableRule, each));
}
// 将得到的路由数据源和表信息封装到RoutingResult中,RoutingResult中有个TableUnits类型属性,TableUnits类中有个List tableUnits属性,TableUnit包含三个属性:dataSourceName--数据源名称,logicTableName--逻辑表名称,actualTableName--实际表名称
return generateRoutingResult(tableRule, routedMap);
} 最终需要执行的表数量为路由到的数据源个数*路由到的实际表个数;可以自己跟一下调用过程。
4.2 ComplexRoutingEngine
ComplexRoutingEngine,混合多库表路由引擎。
public final class ComplexRoutingEngine implements RoutingEngine {
private final ShardingRule shardingRule; //分库分表规则
private final List4.3 CartesianRoutingEngine
如上分析,求得简单路由结果集后,求笛卡尔积就是复杂路由的最终路由结果,笛卡尔积路由引擎CartesianRoutingEngine的核心源码如下:
public final class CartesianRoutingEngine implements RoutingEngine {
private final Collection routingResults;
@Override
public CartesianRoutingResult route() {
CartesianRoutingResult result = new CartesianRoutingResult();
for (Entry> entry : getDataSourceLogicTablesMap().entrySet()) { // Entry<数据源(库), Set<逻辑表>> entry
// 获得当前数据源(库)的 路由表单元分组
List> actualTableGroups = getActualTableGroups(entry.getKey(), entry.getValue()); // List>
List> tableUnitGroups = toTableUnitGroups(entry.getKey(), actualTableGroups);//tableUnit的属性有:数据源名称,逻辑表名,实际表名(这三个属性才能确定最终访问的表)
// 笛卡尔积,并合并结果
result.merge(entry.getKey(), getCartesianTableReferences(Sets.cartesianProduct(tableUnitGroups)));
}
log.trace("cartesian tables sharding result: {}", result);
return result;
} 第二步,遍历数据源(库),获得当前数据源(库)的路由表单元分组。
第三步,对路由表单元分组进行笛卡尔积,并合并到路由结果。
// 第一步
// CartesianRoutingEngine.java
private Map> getDataSourceLogicTablesMap() {
Collection intersectionDataSources = getIntersectionDataSources();
Map> result = new HashMap<>(routingResults.size());
// 获得同库对应的逻辑表集合
for (RoutingResult each : routingResults) {
for (Entry> entry : each.getTableUnits().getDataSourceLogicTablesMap(intersectionDataSources).entrySet()) { // 过滤掉不在数据源(库)交集的逻辑表
if (result.containsKey(entry.getKey())) {
result.get(entry.getKey()).addAll(entry.getValue());
} else {
result.put(entry.getKey(), entry.getValue());
}
}
}
//这里得到的结果是:数据源+逻辑表
return result;
}
private Collection getIntersectionDataSources() {
Collection result = new HashSet<>();
for (RoutingResult each : routingResults) {
if (result.isEmpty()) {
result.addAll(each.getTableUnits().getDataSourceNames());
}
result.retainAll(each.getTableUnits().getDataSourceNames()); //交集
}
return result;
} 这一步很关键的一点是同数据源的取交集。
第二步
private List> getActualTableGroups(final String dataSource, final Set logicTables) {
List> result = new ArrayList<>(logicTables.size());
for (RoutingResult each : routingResults) {
result.addAll(each.getTableUnits().getActualTableNameGroups(dataSource, logicTables));
}
return result;
} private List> toTableUnitGroups(final String dataSource, final List> actualTableGroups) {
List> result = new ArrayList<>(actualTableGroups.size());
for (Set each : actualTableGroups) {
result.add(new HashSet<>(Lists.transform(new ArrayList<>(each), new Function() {
@Override
public TableUnit apply(final String input) {
return findTableUnit(dataSource, input);
}
})));
}
return result;
} private List getCartesianTableReferences(final Set> cartesianTableUnitGroups) {
List result = new ArrayList<>(cartesianTableUnitGroups.size());
for (List each : cartesianTableUnitGroups) {
result.add(new CartesianTableReference(each));
}
return result;
} public final class CartesianRoutingResult extends RoutingResult {
@Getter
private final List routingDataSources = new ArrayList<>();
void merge(final String dataSource, final Collection routingTableReferences) {
for (CartesianTableReference each : routingTableReferences) {
merge(dataSource, each);
}
}
private void merge(final String dataSource, final CartesianTableReference routingTableReference) {
for (CartesianDataSource each : routingDataSources) {
if (each.getDataSource().equalsIgnoreCase(dataSource)) {
each.getRoutingTableReferences().add(routingTableReference);
return;
}
}
routingDataSources.add(new CartesianDataSource(dataSource, routingTableReference));
} 最后:回来看下ParsingSQLRouter 主#route()
@Override
public SQLRouteResult route(final String logicSQL, final List这块代码看起来比较长。自己debug跟一下对比着表就清晰多了。