对于一个刚上线的互联网项目来说,由于前期活跃用户数量并不多,并发量也相对较小,所以此时企业一般都会选择将所有数据存放在一个数据库中进行访问操作。但随着后续的市场推广力度不断加强,用户数量和并发量不断上升,这时如果仅靠一个数据库来支撑所有访问压力,几乎是在自寻死路。所以一旦到了这个阶段,大部分Mysql DBA就会将数据库设置成读写分离状态,也就是一个Master节点对应多个Salve节点。经过Master/Salve模式的设计后,完全可以应付单一数据库无法承受的负载压力,并将访问操作分摊至多个Salve节点上,实现真正意义上的读写分离。但大家有没有想过,单一的Master/Salve模式又能抗得了多久呢?如果用户数量和并发量出现量级上升,单一的Master/Salve模式照样抗不了多久,毕竟一个Master节点的负载还是相对比较高的。为了解决这个难题,Mysql DBA会在单一的Master/Salve模式的基础之上进行数据库的垂直分区(分库)。所谓垂直分区指的是可以根据业务自身的不同,将原本冗余在一个数据库内的业务表拆散,将数据分别存储在不同的数据库中,同时仍然保持Master/Salve模式。经过垂直分区后的Master/Salve模式完全可以承受住难以想象的高并发访问操作,但是否可以永远高枕无忧了?答案是否定的,一旦业务表中的数据量大了,从维护和性能角度来看,无论是任何的CRUD操作,对于数据库而言都是一件极其耗费资源的事情。即便设置了索引,仍然无法掩盖因为数据量过大从而导致的数据库性能下降的事实,因此这个时候Mysql DBA或许就该对数据库进行水平分区(分表,sharding),所谓水平分区指的是将一个业务表拆分成多个子表,比如user_table0、user_table1、user_table2。子表之间通过某种契约关联在一起,每一张子表均按段位进行数据存储,比如user_table0存储1-10000的数据,而user_table1存储10001-20000的数据,最后user_table3存储20001-30000的数据。经过水平分区设置后的业务表,必然能够将原本一张表维护的海量数据分配给N个子表进行存储和维护,这样的设计在国内一流的互联网企业比较常见,如图所示:
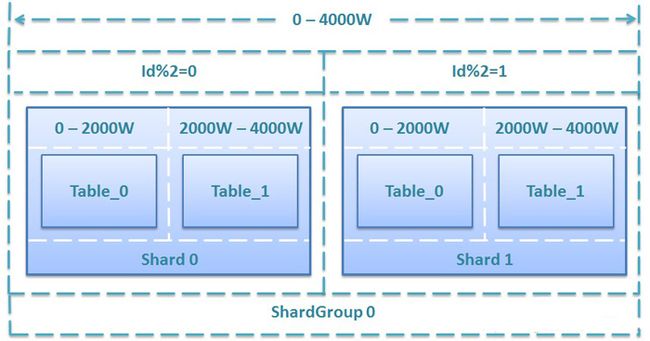
水平分区
以上是数据库分库分表的原理,但是如果每次在数据访问层的设计中实现分库分表,将会显得非常麻烦。笔者参考了了下code google shardbatis的设计方式,发现googlecode上的shardbatis无法做到分库,只能做到分表,而且配置相当不灵活,源码很难找到。所以笔者重新设计了一套mybatis插件,相比google code的那套,该框架可以做到完整的分库分表和友好的配置。组件结构如图所示:
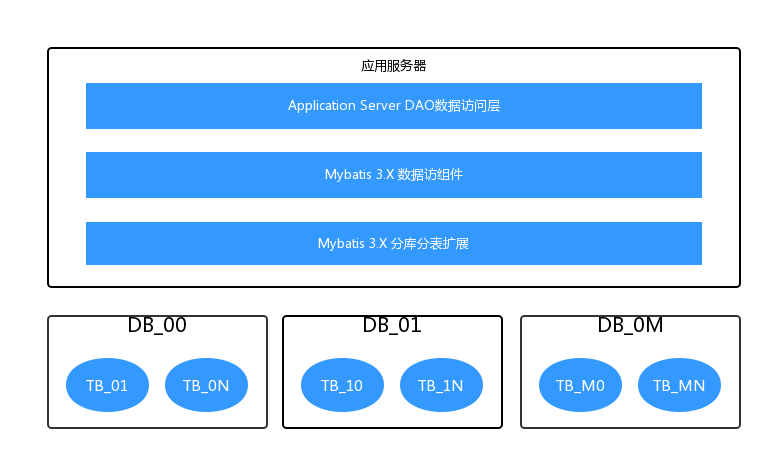
组件结构图
使用方法:
1.准备数据库集群配置文件
2.准备分库分表规则配置
3.为mybatis配置扩展插件
4.为mybatis配置分库分表数据源
5.使用逻辑表配置mybatis mapper
INSERT INTO t_student(no, name, sex) VALUES(#{no}, #{name}, #{sex})
UPDATE t_student
name=#{name},
WHERE no=#{no}
6.编写分库分表规则
public class StudentShardStrategy implements ShardStrategy {
@Override
public ShardCondition parse(Map params) {
String no = (String) params.get("no");
char c = no.charAt(0);
ShardCondition condition = new ShardCondition();
if (c == '1') {
condition.setDatabaseSuffix("_01");
condition.setTableSuffix("_01");
} else {
condition.setDatabaseSuffix("_00");
condition.setTableSuffix("_00");
}
return condition;
}
}
全部配置好了之后就可以按照以前使用mybatis的方式将数据库集群当做一个逻辑表来操作了。剩余的转换操作就交给中间扩展层插件来转换吧。
以下是转换结果:
Shard Original SQL:SELECT * FROM `t_student` WHERE `no` = ?
Shard Convert SQL:SELECT * FROM `test_00`.`t_student_00` WHERE `no` = ?
Shard Original SQL:DELETE FROM `t_student` WHERE `no` = ?
Shard Convert SQL:DELETE FROM `test_00`.`t_student_00` WHERE `no` = ?
Shard Original SQL:INSERT INTO t_student(no, name, sex) VALUES(?, ?, ?)
Shard Convert SQL:INSERT INTO test_00.t_student_00 (no, name, sex) VALUES (?, ?, ?)
Shard Original SQL:UPDATE t_student SET name=? WHERE no=?
Shard Convert SQL:UPDATE test_00.t_student_00 SET name = ? WHERE no = ?
注意:分库分表从原则上是不支持跨库事物的,如果需要使用事务必须保证在多个表在同一个库中。
以下是事物支持的测试用例:
/**
* @author fangjialong
* @date 2015年9月5日 下午4:27:50
*/
public class StudentDAOTransactionTest {
private DalSpringContext context;
private StudentDAO studentDAO;
private TransactionTemplate tt;
@Test
public void test() {
LogFactory.useNoLogging();
this.context = new DalSpringContext();
this.context.refresh();
this.studentDAO = context.getBean(StudentDAO.class);
this.tt = context.getBean("distributeDefaultTransactionTemplate", TransactionTemplate.class);
tt.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus status) {
Student s = new Student();
s.setNo("0001");
s.setName("房佳龙");
studentDAO.update(s);
status.setRollbackOnly();
}
});
context.close();
}
}
change log:
2015-09-08:1、增加指定库表查询方案,2、增加分库分表Sequence创建方案