第四讲案例
第四讲案例
- 扇贝单词
- 网易云音乐的所有歌手
- 古诗文爬取
- 小说
扇贝单词
首先打开扇贝网址,直接使用这个网址即可https://www.shanbay.com/wordlist/110521/232414/
导入lxml模块
from lxml import etree
然后分析页面结构
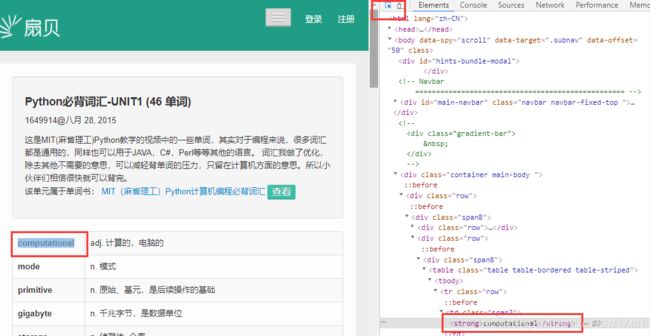
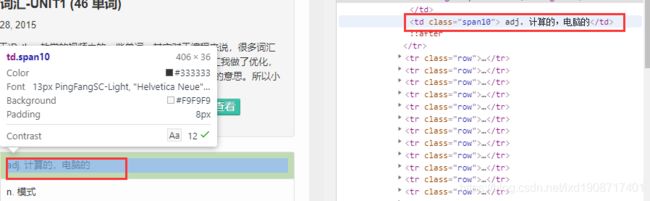
使用xpath解析节点
word = tree.xpath('//strong/text()')
fan = tree.xpath('//td[@class="span10"]/text()')
完整代码参考如下:
"""
扇贝单词
"""
import requests
from lxml import etree
def main():
"""爬取扇贝单词"""
# 获取页面内容
url = 'https://www.shanbay.com/wordlist/110521/232414/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
content = requests.get(url, headers=headers).text
# print(content)
# 创建xpath对象
tree = etree.HTML(content)
# 获取单词
word = tree.xpath('//strong/text()')
fan = tree.xpath('//td[@class="span10"]/text()')
# print(word, fan)
# 使用enumerate合并单词和释义,防止长度不一报错
for i, one in enumerate(word):
wore_dict = dict()
wore_dict['e'] = one
wore_dict['c'] = fan[i]
print(wore_dict)
if __name__ == '__main__':
main()
网易云音乐的所有歌手
百度搜索网易云音乐,点击歌手,通过分类获取所有歌手。
https://music.163.com/#/discover/artist
注意:该链接中有锚点#,不影响浏览器打开网页,但是使用爬虫请求不到需要的内容,因此需要将请求的url去掉锚点。

通过xpath解析获得各类别的url,这里只获得了路径及之后的部分,需要将协议和ip拼接,才是完整的可以请求的url:
![]()
每类之中又通过歌手名字首字母划分,因此也要通过xpath获取url分别请求才能拿到全部的歌手信息。

为避免重复获取,应使用位置节点去掉热门这一类:
'//ul[@id="initial-selector"]/li[position()>1]/a/@href'
完整代码如下:
"""
爬取网易云所有歌手名字即歌单页面
"""
import requests
from lxml import etree
from day_4.Excel_Utils.excel_utiles import ExcelUtils
import os
def get_content(url):
"""
发送请求获取响应
:param url: 请求url
:return: 网页内容,xpath解析对象
"""
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
response = requests.get(url, headers=headers)
# print(response.text)
return etree.HTML(response.text)
def get_url(content):
"""
获取歌单分类的url
:param content: 分类页面内容
:return: url列表
"""
url = content.xpath('//div[@class="blk"]/ul/li/a/@href')
# print(url)
return url
def get_word_url(fen_content):
"""
获取单词分页url
:param fen_content: 地区分类内容
:return: url序列
"""
return fen_content.xpath('//ul[@id="initial-selector"]/li[position()>1]/a/@href')
def get_singer(word_content):
"""
# 6、获取首字母分类下的歌手名字和链接
:param word_content:
:return:
"""
name = word_content.xpath('//ul[@id="m-artist-box"]/li/p/a/text()|//ul[@id="m-artist-box"]/li/a/text()')
url = word_content.xpath('//ul[@id="m-artist-box"]/li/p/a/@href|//ul[@id="m-artist-box"]/li/a/@href')
# print(name,url)
# 使用enumerate获取索引
for i, name in enumerate(name):
singer_dict = dict()
singer_dict['name'] = name
singer_dict['url'] = 'https://music.163.com'+url[i]
# print(singer_dict)
info_singer.append(singer_dict)
print(info_singer)
filename = '网易云.xls'
# 将获取的数据写入Excel文件
if os.path.exists(filename):
ExcelUtils.append_to_excel(info_singer, filename)
else:
ExcelUtils.write_to_excel(info_singer, filename)
# 保存后将原有数据清空,方面下一类保存
info_singer.clear()
def main():
"""
主线任务
:return:
"""
# 1、准备url,注意去掉url中的锚点#
base_url = 'https://music.163.com/discover/artist'
# 2、获取分类页面内容
base_content = get_content(base_url)
# print(base_content)
# 3、截取分类的url序列
fen_url = get_url(base_content)
for u in fen_url:
# 4、拼接url
url = 'https://music.163.com' + u
# 5、获取该类的页面内容
fen_content = get_content(url)
# print(fen_content)
word_url = get_word_url(fen_content)
# print(word_url)
# 6、获取首字母分类下的歌手名字和链接
for u in word_url:
url = 'https://music.163.com' + u
# 获取首字母页面内容
word_content = get_content(url)
# 获取目标
get_singer(word_content)
print(info_singer)
if __name__ == '__main__':
info_singer = list()
main()
将数据写入Excel不是必要的步骤,有兴趣的可以看一下“python使用xlwt与xlrd模块将数据存储到Excel文件”这篇文章。https://blog.csdn.net/lxd1908717401/article/details/107236958
古诗文爬取
百度搜索古诗文,通过右侧分类标签获取全部类别的url,再在每类中获取每首诗的url,通过该链接获取古诗的题目、内容、作者、释义等信息。https://www.gushiwen.org/
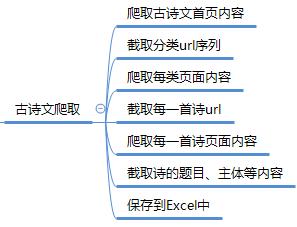
与上一个案例基本一致,但要注意使用xpath时,分析页面结构要精确,大胆尝试,灵活变通才能获取到完整准确的数据。
参考代码如下
import requests
import os
from lxml import etree
from day_4.Excel_Utils.excel_utiles import ExcelUtils
def get_content(url):
"""
获取响应内容
:param url:
:return:xpath解析对象
"""
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
response = requests.get(url, headers=headers)
# print(response.text)
return etree.HTML(response.text)
def get_song_info(song_content):
"""
截取诗的标题、作者、内容、译文
:param song_content:
:return:存储一首诗数据的字典
"""
song = dict()
# xpath解析节点
song['title'] = song_content.xpath('//div[@class="sons"]/div/h1/text()')[0]
# print(title)
a = song_content.xpath('//div[@class="sons"]/div/p/a/text()')
song['author'] = a[0]+a[1]
song['content'] = song_content.xpath('string(//div[@class="left"]/div[2]/div/div[2])')
song['fanyi'] = song_content.xpath('string(//div[@class="left"]/div[3]/div/p)')
# print(song)
return song
def main():
"""
爬取古诗文网站主线任务
:return:
"""
# 1、爬取古诗文首页内容
base_url = 'https://www.gushiwen.org/'
base_content = get_content(base_url)
# 2、截取分类url序列
fen_url = base_content.xpath('//div[@class="right"]/div[2]/div[2]/a/@href')
# print(fen_url)
# 3、爬取每类页面内容
for u in fen_url:
fen_content = get_content(u)
# 4、截取每一首诗url
song_url = fen_content.xpath('//div[@class="sons"]/div/span/a/@href')
# print(song_url)
# 5、爬取每一首诗页面内容
for u in song_url:
if 'http' not in u:
u = 'https://so.gushiwen.cn'+u
song_content = get_content(u)
# 6、截取诗的题目、主体等内容
song_dict = get_song_info(song_content)
infos.append(song_dict)
filename = '古诗文.xls'
if os.path.exists(filename):
ExcelUtils.append_to_excel(infos, filename=filename)
else:
ExcelUtils.write_to_excel(infos, filename)
infos.clear()
if __name__ == '__main__':
infos = list()
main()
小说
参考上述案例,可以尝试爬取该网站的小说信息https://xiaoshuo.2345daohang.com/top.html
要求是:爬取小说排行榜各类小说的书名、简介、字数、作者、详情页链接。
参考代码如下:
"""
爬取小说排行榜各类小说的书名、简介、字数、作者、详情页链接
"""
import requests, re, os
from lxml import etree
from day_4.Excel_Utils.excel_utiles import ExcelUtils
def get_content(url):
"""
通过url发送请求获取响应
:param url: 请求url
:return: 页面内容
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
'Cookie': 'UM_distinctid=173333b1db23c7-00666bc7bc4fcd-3e3e5e0e-100200-173333b1db3244; CNZZDATA5283199=cnzz_eid%3D2132259314-1594288706-%26ntime%3D1594288706',
}
response = requests.get(url, headers=headers)
# print(response.text)
return etree.HTML(response.text)
def content_none(lst):
"""
:param lst:
:return:
"""
if not lst:
lst = ['无']
return lst
def get_info(page_content):
"""
书名、简介、字数、作者、详情页链接
:param page_content:
:return:
"""
li_list = page_content.xpath(f'//div[@class="ls"]/ul/li')
for i in li_list:
dict_novel = dict()
# 书名、简介、字数、作者、详情页链接
title = i.xpath(f'.//div[@class="sm"]/a/text()')
content = content_none(i.xpath(f'.//div[@class="jj"]/a/text()'))
num = content_none(i.xpath(f'.//div[@class="zs"]/text()'))
author = content_none(i.xpath(f'.//div[@class="zz"]/text()'))
url = i.xpath(f'.//div[@class="sm"]/a/@href')[0]
# 保存到字典中
dict_novel['书名'] = title[0]
dict_novel['简介'] = content[0]
dict_novel['字数'] = num[0]
dict_novel['作者'] = author[0]
dict_novel['链接'] = 'https://xiaoshuo.2345daohang.com/'+url
# 保存到infos中
infos.append(dict_novel)
# 写入Excel文件,命名为‘小说.xls'
filename = '小说.xls'
if os.path.exists(filename):
ExcelUtils.append_to_excel(infos, filename)
else:
ExcelUtils.write_to_excel(infos, filename)
# 清空infos
infos.clear()
return
def main():
"""
爬取小说的主线任务
:return: 成功提示
"""
# 1、首页内容
base_url = 'https://xiaoshuo.2345daohang.com/top.html'
base_content = get_content(base_url)
# 2、分类链接
fen_url = base_content.xpath('//div[@id="left"]/div[position()>3]/a/@href')
# print(fen_url)
# 3、拼接页数参数,各类小说页面
for u in fen_url:
u = 'https:' + u
# 拼接前一百页的url
for i in range(1,101):
if i == 1:
url = u
else:
# url = u.split('.htm')[0] + '_' + str(i) +'.htm'
url = u.replace('.htm', f'_{i}.htm')
# print(url)
page_content = get_content(url)
print(page_content)
# 4、截取小说书名、简介等信息
get_info(page_content)
return
if __name__ == '__main__':
infos = list()
main()
感谢各位的耐心阅读和支持!