
桔妹导读:本文给出其中稳定性相关的规范,这些规范都是顺风车成立五年来,对大量真实线上故障复盘、总结得到的,希望对大家服务的稳定性提升有所帮助。
服务端作为顺风车技术部内最大的工程团队,随着人员的扩张和迭代,流程规范在其中扮演着原来越重要的角色。一方面规范化可以提高我们的交付质量、交付效率,另一方面,我们也希望在一次次的实战中不断的总结,探索出适用于我们团队的最佳实践。
基于此,我们制定并推广了一套适用于服务端开发的可执行、最小限制的工程规范,包括研发流程、稳定性、性能成本等多个方面。
本文给出其中稳定性相关的规范,这些规范都是顺风车成立五年来,对大量真实线上故障复盘、总结得到的,希望对大家服务的稳定性提升有所帮助。
1. 名词解释
下文的描述中,会用到很多的技术名词,为更容易的理解,在这里对这些名词做下简要说明:
- 服务分级: 根据业务需要,一般的我们需要针对最小系统划分为一级服务,一旦出问题需要第一优先级跟进。我们将影响业务核心指标(比如发单量、成单量等)的服务定义为一级服务,其他为二级服务。
- 预览集群: 和线上生产环境的部署完全一致的一套环境,只是无线上流量,可以内部访问,集群内流量闭环。
- 小流量集群: 和线上生产环境的部署完全一致的一套环境,通过流量控制,只有个别城市的流量会落到此集群,集群内流量闭环。
- 灰度发布: 将发布过程分为预览集群、灰度城市集群、10%流量、50%流量、100%流量的发布机制,确保安全上线过程。
- 全链路压测: 在不影响线上服务的前提下,对生产环境进行压力测试的解决方案。用以摸清生产环境的容量、瓶颈点等。
- 机房多活: 通过多机房部署,当一个机房出现故障时,可以快速将流量切到其他机房,以减少损失。涉及流量路由、流量闭环、数据同步、数据一致性、灾难应对等诸多环节的整套解决方案。
2. 稳定性规范
稳定性设计
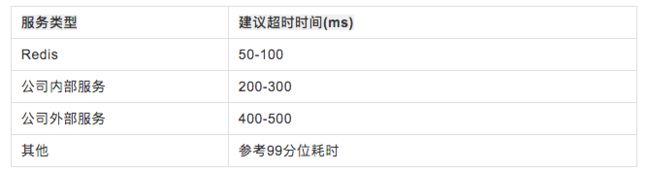
- 【强制】调用方必须设置超时时间,且调用链路超时从上往下递减,建议超时时间设置如下:
- 【强制】核心流程新增依赖默认为弱依赖,如需新增强依赖,需要经过评审决议;
- 【强制】下游服务如提供服务发现,所有服务必须通过服务发现访问该服务,方便服务发现控制下游节点和超时时间;
- 【强制】所有内部服务必须接入服务发现,外部服务尽量推动接入服务发现;
- 【建议】建议框架支持依赖服务手动一键熔断;
- 【建议】服务设计优先考虑无状态设计;
- 【建议】写接口建议考虑防重入;
- 【建议】系统设计原则简单可靠,优先使用成熟技术;
- 【建议】核心服务强制,其他建议,接口建议设置合理的限流配置。
部署和运维
- 【强制】严禁在临时脚本中未通过接口或封装方法,直接操作线上数据,如有需要,必须经过QA测试;
- 【强制】服务上线必须通过上线平台,并接入质量平台(功能包括自动化case、核心曲线图及其他上线checklist),强制停留观察’
- 【强制】一级服务需要包含预览集群、小流量集群(除部分特殊服务)并且双机房部署;
- 【建议】非一级线上服务建议包含预览集群;
- 【建议】新服务上线建议进行容量规划,建议通过接口压测或全流量压测验证模块容量。
监控告警
- 【强制】线上服务机器必须有基础监控报警,包含CPU、IO、内存、磁盘、coredump、端口;
- 【强制】线上服务必须有基础的服务监控,包括接口qps、fatal数量、耗时;
- 【建议】核心业务指标(发单量、抢单量、支付量等)必须有监控和报警;
- 【建议】需要有服务整体大盘,能够涵盖该方向核心模块监控,方便快速定位服务问题。
变更管理
- 【强制】任何一级服务变更,均需要走灰度发布机制;
- 【强制】任何一级服务变更,包括服务变更、配置变更,均需要有相应的回滚预案,保证变更异常时可以快速回退;
- 【建议】尽量避免代码搭车上线;
- 【建议】服务回滚时建议同时回滚相应的代码和配置,保证主线代码的正确性;
- 【建议】配置变更,特别是复杂的配置变更时,建议增加相应的配置校验机制。
预案管理
- 【强制】必须有多活切流预案,且需要保障有效性,必须定期组织演练,建议1月1次;
- 【强制】全链路压测通道需要保证有效性,定期组织压测;
- 【强制】一键限流预案需要保障有效性,定期review和演练;
- 【强制】强依赖降级预案需要保障有效性,定期演练。
故障处理原则
- 【强制】线上出现故障时,必须第一优先级进行处理;
- 【强制】线上出现故障时,如果有变更,第一时间回滚;
- 【强制】线上出现故障,必须组织复盘;
- 【强制】需要有复盘规范,复盘按照规范执行。
3. 稳定性反模式
本章节主要是基于大量的线上故障case,以具体实例驱动,加上研发全流程中各个环节容易犯的一些稳定性问题,提取一些反模式出来,供大家参考,尽量避免后续的工作中犯同样的问题,提高线上服务的稳定性。
3.1.容灾和容错设计
反模式3.1.1
过度的节点熔断策略
【实例】
为了提高请求成功率,在下游故障时对下游节点采取熔断措施,比如1分钟内连续出现5次访问出错,则将该节点熔断,不再调用(过一段时间后再恢复),某天网络抖动,下游服务4个实例中的3个均进入熔断模式,导致访问下游的所有流量均落到剩余的这个实例上,压力过大,将该实例压垮。下游服务雪崩,整个系统不可用。
【解决方案】
熔断模式下,还需要有熔断保护措施,避免过度熔断带来的稳定性问题。
**反模式3.1.2
固定的重试序列**
【实例】
每次重试序列都为“下一台”。
【后果】
一个是雪崩:假设某一类 query 的重试序列为A B,当 A 出现故障时,B 要承受两倍的压力,如果 B 扛不住,那么 B 的下一个也会被压垮;一个是上线损失流量:假设重试次数是2,上线时如果 A 和 B 同时重启,那么重试序列为 A B的 query 必然无结果。
【解决方案】
评估新的重试算法,比如随机重试。不过相对于固定的重试序列,随机重试序列也可能给系统带来风险,例如可能会降低下游模块的cache命中率,降低系统性能。
**反模式3.1.3
不合理的超时设置**
【实例】
上游服务超时时间设置不合理,下游出现问题时,直接把上游服务拖垮。
【解决方案】
应该根据链路的99分位耗时来设置超时时间,同时定期对链路的通信相关配置进行review。
**反模式3.1.4
未考虑同一请求中多次调用下游的影响**
【实例】
服务调用下游时超时时间设置没有问题,但同一请求中会串行多次调用某个下游服务,下游服务故障时,也会把上游服务直接拖垮。
【解决方案】
除了考虑对下游服务的单次超时,还需要考虑对下游服务的总体超时。
**反模式3.1.5
不合理的重试逻辑**
【实例】
整条链路多个地方有重试,下游服务故障时,重试被放大,导致服务雪崩。
【解决方案】
评估重试机制,梳理请求处理的整个链路,保证重试收敛在一个地方。
**反模式3.1.6
没有考虑到业务毛刺的影响**
【实例】
某业务形态有个特点,在半点和整点时刻有请求尖刺,某次受节假日影响,访问下游的流量瞬间暴增,导致下游服务雪崩。
【解决方案】
对业务尖刺进行平衡处理,减少对下游服务的峰值流量冲击。
**反模式3.1.7
没有对异常输入进行容错处理**
【实例】
业务没有对异常输入进行容错处理,仍然按照正常逻辑处理,导致数据混乱。
【解决方案】
业务特别是业务入口,必须对不合理的异常输入进行容错处理,保证整个系统的健壮性。
**反模式3.1.8
接口不支持幂等性设计**
【实例】
接口不支持幂等性,网络故障时引发大量的重试,导致核心数据大量出错。
【解决方案】
接口设计的时候就需要考虑幂等性的需求。
**反模式3.1.9
没有对非核心流程弱依赖化**
【实例】
没有对流程进行弱依赖化,导致系统整体上比较脆弱,每个依赖单元故障都会导致整个业务瘫痪。
【解决方案】
定期对系统的流程进行梳理,最小系统化,非必须流程尽量弱依赖化。
**反模式3.1.10
没有考虑ID溢出的影响**
【实例】
某ID使用int32,超出后ID溢出,导出服务异常。
【解决方案】
增加资源相关的ID字段时要考虑ID的范围,是否有溢出风险
定期对资源相关的ID字段进行review,提前预防,最大限度防止故障的发生
3.2.部署和运维
**反模式3.2.1
部署时未考虑网段因素**
【实例】
服务部署时未考虑网段因素,服务的多个实例都部署到一个交换机下,导致交换机故障时,服务的多个实例不可用,服务所在集群雪崩
【解决方案】
服务部署时尽量多考虑地理因素,同一服务的多个实例尽可能部署到不同的机房、交换机和网段下
**反模式3.2.2
服务混部时未做好资源隔离**
【实例】
多个服务混部,其中一个CPU占用过高,导致其他服务异常
【解决方案】
多个服务混部的情况下,一定要做好资源隔离,避免因一个服务占用资源过高,导致同一台机器上的其他服务不可用
**反模式3.2.3
没有做到对核心业务和隔离和保护**
【实例】
某非核心流程由于bug向mq写入大量消息,导致整个mq集群不可用,整个业务故障
【解决方案】
核心链路和非核心链路的mq隔离,分开部署,非核心流程的变化不会影响主流程,保证核心流程和业务的稳定性
3.3.容量管理
**反模式3.3.1
容量规划时未考虑故障因素**
【实例】
线上某服务qps不大,只部署了2个实例,一个实例高峰期出问题时,流量都落到另外一个实例上面,把服务压垮
【解决方案】
容量估计时需要考虑容灾因素,预留一定的buffer
如果觉得部署实例多,会浪费机器,可以考虑使用弹性云,比较灵活
**反模式3.3.2
上线新功能未合理进行容量规划**
【实例】
某服务,下游依赖众多,在进行容量规划时,重点都集中在某一依赖服务,未对全局所有依赖方进行全面评估,当其中某一依赖服务出现问题,导致整体服务不可用
【解决方案】
上线新功能时,需要对所有下游依赖服务进行容量规划,防止出现瓶颈点
3.4.变更管理
**反模式3.4.1
代码搭车上线**
【实例】
由于缺乏有效的代码修改管理机制,某产品线由于代码搭车上线,出现过多次线上故障
并且由于变更时涉及的修改比较多,导致问题定位和追查时非常困难
【解决方案】
建立严格的代码管理机制,严禁代码搭车上线,保证任何时刻主干没有未上线验证的代码
**反模式3.4.2
服务回滚时遗漏回滚代码**
【实例】
上线出现问题,服务回滚后没有第一时间把代码回滚掉。第二天其他同学上线时将未回滚的问题代码再次带上线,上线时导致连续两天出现系统故障
【解决方案】
服务回滚的时候同时第一时间回滚代码
**反模式3.4.3
过高的并发部署设置**
【实例】
部署配置的并发个数太高,导致同一时刻只有少数机器可用,引发集群雪崩
【解决方案】
服务部署配置的并发个数,要保证剩余机器能够承载业务全部流量
**反模式3.4.4
服务启动或回滚时间过长**
【实例】
服务上线异常,回滚时单个服务回滚时间太长,导致未能短时间内快速止损
【解决方案】
定期检查服务的启动和回滚时间,保证出现故障时可以第一时间完成回滚操作
**反模式3.4.5
配置文件缺少有效的校验机制**
【实例】
配置文件由模型产出,数据配送系统实时配送到线上服务,模型产生的配置文件有问题,引发线上故障
【解决方案】
针对配置文件,尤其是模型产出的配置文件,建立严格的检查和校验机制
**反模式3.4.6
配置变更没有灰度**
【实例】
配置相关修改,稳定性意识上重视度不够,没有进行足够的观察和灰度,导致故障
【解决方案】
所有变更,包括服务变更、配置变更、数据变更以及环境变更,都需要进行严格的观察和灰度,保证变更的质量
**反模式3.4.7
变更没有经过严格的测试**
【实例】
变更较小,感觉没有必要进行测试,结果出现低级错误,导致故障
【解决方案】
任何变更都要测试、double check,修改一行代码,也可能导致线上的稳定性故障
**反模式3.4.8
变更时没有严格按照变更规范执行**
【实例】
上线时,小流量和A机房均严格按照规范检查,服务和各种曲线没有问题,上线B机房时没有进行检查。结果B机房出现故障。
经排查是因为B机房配置缺失
【解决方案】
任何变更都要严格按照变更规范严格检查,上线的每个阶段都要检查服务的各种曲线和指标
**反模式3.4.9
离线直接通过sql更新db数据**
【实例】
直接通过sql进行离线更新数据库,没有做好限流保护,导致db压力大,线上服务访问时出现大量超时
【解决方案】
除非特殊情况,严禁直接通过sql操作db数据,修改需通过接口修改,方便通过曲线观察,也可降低直接改库的风险;
批量修改db数据需要通报dba,经过review,确认没有问题时才可以进行操作;
批量增改、增加数据务必做好限流措施。
3.5.监控报警
** 反模式3.5.1
缺少基础监控**
【实例】
缺少基础监控,导致出现故障,未能第一时间感知。
【解决方案】
梳理基础监控checklist,定期对服务的基础监控进行review和演练。
**反模式3.5.2
缺少业务监控**
【实例】
缺少业务监控,导致出现故障,未能第一时间感知。
【解决方案】
对核心流程和核心业务指标,都需要添加业务监控。
**反模式3.5.3
告警阈值设置有问题**
【实例】
由于业务bug导致线上大量告警,先临时将告警阈值从20调整到200,问题修复上线后忘了改回来,就一直维持这个阈值设置,导致后续业务出问题的时候,未能第一时间报出来。
【解决方案】
尽量使用短暂屏蔽报警,而不是调高阈值。
**反模式3.5.4
监控告警当前已失效**
【实例】
业务迭代过快,导致监控告警信息和业务已经不再匹配。
【解决方案】
定期对告警进行演练,保证其有效性。
重大业务迭代,需要将监控告警列入checklist。
3.6.预案管理
**反模式3.6.1
上游流量异常时没有相应的防雪崩预案**
【实例】
服务上游流量突增,导致服务瞬间被压垮,系统雪崩
【解决方案】
服务必须提前做好防雪崩预案,不然很容易导致整个系统级别的故障
**反模式3.6.2
服务没有防刷和防攻击预案**
【实例】
线上问题定位时,发现某个线上服务存在大量刷接口的现象,给线上系统的稳定性带来很大隐患,同时造成很大的资源和成本浪费。
【解决方案】
线上服务,特别是和端交互比较多的服务,设计时就需要考虑好防刷和防攻击策略,提前做好预案
**反模式3.6.3
下游故障时没有相应的处理预案**
【实例】
下游服务故障,上游服务没有相应的处理预案,导致被下游拖垮,因为这种情况导致的大型故障非常多
【解决方案】
下游故障,尤其是下游弱依赖服务故障,需要有相应的处理预案
**反模式3.6.4
故障时预案已失效**
【实例】
由于业务迭代比较快,当前对某下游已经从弱依赖变成强依赖,下游故障时,执行降级预案但业务故障并没有恢复
【解决方案】
定期对预案进行演练,保证预案有效性
3.7.稳定性原则和意识
** 反模式3.7.1
对稳定性缺乏敬畏之心**
【实例】
以为服务出故障是正常的,对稳定性不以为然
【解决方案】
技术同学需要对代码、线上稳定性保持敬畏之心,不能有任何侥幸心理
一行代码的bug,就可能导致整个业务瘫痪掉
**反模式3.7.2
故障时没有第一时间止损**
【实例】
服务出现故障时,相关同学第一时间在定位故障原因,没有第一时间进行止损
【解决方案】
出现故障必须第一优先级处理,第一时间止损
**反模式3.7.3
使用未充分验证过的技术和方案**
【实例】
某服务使用了mq的广播特性,该特性在公司还没有在线上被使用过,上线后触发mq广播消费代码中的一个bug,导致mq集群不可用的故障
【解决方案】
尽量避免使用未充分验证过的技术和方案
如果因为某些原因必须使用,一定要有相应的兜底措施,同时控制好接入的节奏
在非关键服务上验证充分后,才能应用到核心链路上
**反模式3.7.4
使用新技术时未控制好接入节奏**
【实例】
某服务使用了mq的广播特性,在非核心服务验证时间不够的情况下,将此特性引入核心服务,核心服务的流量比较大,触发mq广播消费代码中的一个bug,导致mq集群不可用的故障
【解决方案】
引入新技术时一定要控制好接入的节奏
在非关键服务上验证充分后,才能应用到核心链路上
**反模式3.7.5
稳定性改进方案未及时落实**
【实例】
某服务出现故障,复盘时制定了相应的改进措施,但是未及时有效落实;后该问题再次爆发,又一次服务故障。
【解决方案】
建立改进措施落实的有效跟踪机制,保证改进措施的有效落实。
团队简介
顺风车服务端团队是由一群团结互助、乐观正直、追求极致的小伙伴汇聚而成,致力于构建一流的安全、交易、营销服务端技术体系,助力滴滴顺风车实现“分享出行让生活更美好”的使命 。
如果你想了解滴滴顺风车优质技术分享,欢迎关注「滴滴顺风车技术」公众号,阅读原文与更多技术干货。
欢迎关注滴滴技术公众号!

本文由博客群发一文多发等运营工具平台 OpenWrite 发布