spark-shell on yarn 出错(arn application already ended,might be killed or not able to launch applic)解决
今天想要将spark-shell 在yarn-client的状态下 结果出错:
[hadoop@localhost spark-1.0.1-bin-hadoop2]$ bin/spark-shell --master yarn-client
Spark assembly has been built with Hive, including Datanucleus jars on classpath
14/07/22 17:28:46 INFO spark.SecurityManager: Changing view acls to: hadoop
14/07/22 17:28:46 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop)
14/07/22 17:28:46 INFO spark.HttpServer: Starting HTTP Server
14/07/22 17:28:46 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:28:46 INFO server.AbstractConnector: Started [email protected]:49827
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.0.1
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_55)
Type in expressions to have them evaluated.
Type :help for more information.
14/07/22 17:28:51 WARN spark.SparkConf:
SPARK_CLASSPATH was detected (set to '/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar').
This is deprecated in Spark 1.0+.
Please instead use:
- ./spark-submit with --driver-class-path to augment the driver classpath
- spark.executor.extraClassPath to augment the executor classpath
14/07/22 17:28:51 WARN spark.SparkConf: Setting 'spark.executor.extraClassPath' to '/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar' as a work-around.
14/07/22 17:28:51 WARN spark.SparkConf: Setting 'spark.driver.extraClassPath' to '/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar' as a work-around.
14/07/22 17:28:51 INFO spark.SecurityManager: Changing view acls to: hadoop
14/07/22 17:28:51 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop)
14/07/22 17:28:51 INFO slf4j.Slf4jLogger: Slf4jLogger started
14/07/22 17:28:51 INFO Remoting: Starting remoting
14/07/22 17:28:51 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://spark@localhost:41257]
14/07/22 17:28:51 INFO Remoting: Remoting now listens on addresses: [akka.tcp://spark@localhost:41257]
14/07/22 17:28:51 INFO spark.SparkEnv: Registering MapOutputTracker
14/07/22 17:28:51 INFO spark.SparkEnv: Registering BlockManagerMaster
14/07/22 17:28:51 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20140722172851-5d58
14/07/22 17:28:51 INFO storage.MemoryStore: MemoryStore started with capacity 294.9 MB.
14/07/22 17:28:51 INFO network.ConnectionManager: Bound socket to port 36159 with id = ConnectionManagerId(localhost,36159)
14/07/22 17:28:51 INFO storage.BlockManagerMaster: Trying to register BlockManager
14/07/22 17:28:51 INFO storage.BlockManagerInfo: Registering block manager localhost:36159 with 294.9 MB RAM
14/07/22 17:28:51 INFO storage.BlockManagerMaster: Registered BlockManager
14/07/22 17:28:51 INFO spark.HttpServer: Starting HTTP Server
14/07/22 17:28:51 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:28:51 INFO server.AbstractConnector: Started [email protected]:57197
14/07/22 17:28:51 INFO broadcast.HttpBroadcast: Broadcast server started at http://localhost:57197
14/07/22 17:28:51 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-9b5a359c-37cf-4530-85d6-fcdbc534bc84
14/07/22 17:28:51 INFO spark.HttpServer: Starting HTTP Server
14/07/22 17:28:51 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:28:51 INFO server.AbstractConnector: Started [email protected]:34888
14/07/22 17:28:52 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:28:52 INFO server.AbstractConnector: Started [email protected]:4040
14/07/22 17:28:52 INFO ui.SparkUI: Started SparkUI at http://localhost:4040
14/07/22 17:28:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
--args is deprecated. Use --arg instead.
14/07/22 17:28:52 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
14/07/22 17:28:53 INFO yarn.Client: Got Cluster metric info from ApplicationsManager (ASM), number of NodeManagers: 1
14/07/22 17:28:53 INFO yarn.Client: Queue info ... queueName: default, queueCurrentCapacity: 0.0, queueMaxCapacity: 1.0,
queueApplicationCount = 1, queueChildQueueCount = 0
14/07/22 17:28:53 INFO yarn.Client: Max mem capabililty of a single resource in this cluster 8192
14/07/22 17:28:53 INFO yarn.Client: Preparing Local resources
14/07/22 17:28:53 INFO yarn.Client: Uploading file:/home/hadoop/spark/assembly/target/scala-2.10/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar to hdfs://localhost:9000/user/hadoop/.sparkStaging/application_1406018656679_0002/spark-assembly_2.10-0.9.1-hadoop2.2.0.jar
14/07/22 17:28:54 INFO yarn.Client: Setting up the launch environment
14/07/22 17:28:54 INFO yarn.Client: Setting up container launch context
14/07/22 17:28:54 INFO yarn.Client: Command for starting the Spark ApplicationMaster: List($JAVA_HOME/bin/java, -server, -Xmx512m, -Djava.io.tmpdir=$PWD/tmp, -Dspark.tachyonStore.folderName=\"spark-10325217-bdb0-4213-8ae8-329940b98b95\", -Dspark.yarn.secondary.jars=\"\", -Dspark.home=\"/home/hadoop/spark\", -Dspark.repl.class.uri=\"http://localhost:49827\", -Dspark.driver.host=\"localhost\", -Dspark.app.name=\"Spark shell\", -Dspark.jars=\"\", -Dspark.fileserver.uri=\"http://localhost:34888\", -Dspark.executor.extraClassPath=\"/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar\", -Dspark.master=\"yarn-client\", -Dspark.driver.port=\"41257\", -Dspark.driver.extraClassPath=\"/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar\", -Dspark.httpBroadcast.uri=\"http://localhost:57197\", -Dlog4j.configuration=log4j-spark-container.properties, org.apache.spark.deploy.yarn.ExecutorLauncher, --class, notused, --jar , null, --args 'localhost:41257' , --executor-memory, 1024, --executor-cores, 1, --num-executors , 2, 1>, /stdout, 2>, /stderr)
14/07/22 17:28:54 INFO yarn.Client: Submitting application to ASM
14/07/22 17:28:54 INFO impl.YarnClientImpl: Submitted application application_1406018656679_0002 to ResourceManager at /0.0.0.0:8032
14/07/22 17:28:54 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021334568
yarnAppState: ACCEPTED
14/07/22 17:28:55 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021334568
yarnAppState: ACCEPTED
14/07/22 17:28:56 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021334568
yarnAppState: ACCEPTED
14/07/22 17:28:57 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021334568
yarnAppState: ACCEPTED
14/07/22 17:28:58 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021334568
yarnAppState: ACCEPTED
14/07/22 17:28:59 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021334568
yarnAppState: FAILED
org.apache.spark.SparkException: Yarn application already ended,might be killed or not able to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApp(YarnClientSchedulerBackend.scala:105)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:82)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:136)
at org.apache.spark.SparkContext.(SparkContext.scala:318)
at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:957)
at $iwC$$iwC.(:8)
at $iwC.(:14)
at (:16)
at .(:20)
at .()
at .(:7)
at .()
at $print()
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:788)
at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1056)
at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:614)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:645)
at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:609)
at org.apache.spark.repl.SparkILoop.reallyInterpret$1(SparkILoop.scala:796)
at org.apache.spark.repl.SparkILoop.interpretStartingWith(SparkILoop.scala:841)
at org.apache.spark.repl.SparkILoop.command(SparkILoop.scala:753)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$1.apply(SparkILoopInit.scala:121)
at org.apache.spark.repl.SparkILoopInit$$anonfun$initializeSpark$1.apply(SparkILoopInit.scala:120)
at org.apache.spark.repl.SparkIMain.beQuietDuring(SparkIMain.scala:263)
at org.apache.spark.repl.SparkILoopInit$class.initializeSpark(SparkILoopInit.scala:120)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:56)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1$$anonfun$apply$mcZ$sp$5.apply$mcV$sp(SparkILoop.scala:913)
at org.apache.spark.repl.SparkILoopInit$class.runThunks(SparkILoopInit.scala:142)
at org.apache.spark.repl.SparkILoop.runThunks(SparkILoop.scala:56)
at org.apache.spark.repl.SparkILoopInit$class.postInitialization(SparkILoopInit.scala:104)
at org.apache.spark.repl.SparkILoop.postInitialization(SparkILoop.scala:56)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply$mcZ$sp(SparkILoop.scala:930)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply(SparkILoop.scala:884)
at org.apache.spark.repl.SparkILoop$$anonfun$process$1.apply(SparkILoop.scala:884)
at scala.tools.nsc.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:135)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:884)
at org.apache.spark.repl.SparkILoop.process(SparkILoop.scala:982)
at org.apache.spark.repl.Main$.main(Main.scala:31)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.spark.deploy.SparkSubmit$.launch(SparkSubmit.scala:303)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:55)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Spark context available as sc.

0001和0002是失败的,
这时候可以通过任务右侧的Tracking UI查看job的history
点进去后进入这个画面:

这里大概能看出一点端倪,就是在调用runWorker时候失败了 还是不够详细 我们发现下面有ApplicationMasters的logs 我们点进去:

可以看到有两个log 一个是stdout 一个是stderr stdout是空的 我们自然点开stderr看:
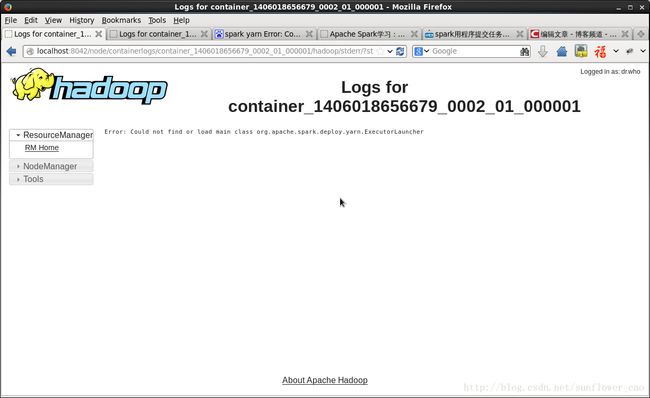
log内容为:
Error: Could not find or load main class org.apache.spark.deploy.yarn.ExecutorLauncher就是找不到这个类,这时候就很自然的想到没有export spark的jar包
我们先export jar包 然后运行on yarn就没有问题了
[hadoop@localhost spark-1.0.1-bin-hadoop2]$ export SPARK_JAR=lib/spark-assembly-1.0.1-hadoop2.2.0.jar
[hadoop@localhost spark-1.0.1-bin-hadoop2]$ bin/spark-shell --master yarn-client
Spark assembly has been built with Hive, including Datanucleus jars on classpath
14/07/22 17:34:02 INFO spark.SecurityManager: Changing view acls to: hadoop
14/07/22 17:34:02 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop)
14/07/22 17:34:02 INFO spark.HttpServer: Starting HTTP Server
14/07/22 17:34:02 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:34:02 INFO server.AbstractConnector: Started [email protected]:51297
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.0.1
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_55)
Type in expressions to have them evaluated.
Type :help for more information.
14/07/22 17:34:07 WARN spark.SparkConf:
SPARK_CLASSPATH was detected (set to '/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar').
This is deprecated in Spark 1.0+.
Please instead use:
- ./spark-submit with --driver-class-path to augment the driver classpath
- spark.executor.extraClassPath to augment the executor classpath
14/07/22 17:34:07 WARN spark.SparkConf: Setting 'spark.executor.extraClassPath' to '/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar' as a work-around.
14/07/22 17:34:07 WARN spark.SparkConf: Setting 'spark.driver.extraClassPath' to '/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar' as a work-around.
14/07/22 17:34:07 INFO spark.SecurityManager: Changing view acls to: hadoop
14/07/22 17:34:07 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop)
14/07/22 17:34:07 INFO slf4j.Slf4jLogger: Slf4jLogger started
14/07/22 17:34:07 INFO Remoting: Starting remoting
14/07/22 17:34:07 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://spark@localhost:58666]
14/07/22 17:34:07 INFO Remoting: Remoting now listens on addresses: [akka.tcp://spark@localhost:58666]
14/07/22 17:34:07 INFO spark.SparkEnv: Registering MapOutputTracker
14/07/22 17:34:07 INFO spark.SparkEnv: Registering BlockManagerMaster
14/07/22 17:34:07 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-local-20140722173407-9c9c
14/07/22 17:34:07 INFO storage.MemoryStore: MemoryStore started with capacity 294.9 MB.
14/07/22 17:34:07 INFO network.ConnectionManager: Bound socket to port 41701 with id = ConnectionManagerId(localhost,41701)
14/07/22 17:34:07 INFO storage.BlockManagerMaster: Trying to register BlockManager
14/07/22 17:34:07 INFO storage.BlockManagerInfo: Registering block manager localhost:41701 with 294.9 MB RAM
14/07/22 17:34:07 INFO storage.BlockManagerMaster: Registered BlockManager
14/07/22 17:34:07 INFO spark.HttpServer: Starting HTTP Server
14/07/22 17:34:07 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:34:07 INFO server.AbstractConnector: Started [email protected]:52090
14/07/22 17:34:07 INFO broadcast.HttpBroadcast: Broadcast server started at http://localhost:52090
14/07/22 17:34:07 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-c4e1f63c-c50a-49af-bda5-580eabeff77c
14/07/22 17:34:07 INFO spark.HttpServer: Starting HTTP Server
14/07/22 17:34:07 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:34:07 INFO server.AbstractConnector: Started [email protected]:38401
14/07/22 17:34:08 INFO server.Server: jetty-8.y.z-SNAPSHOT
14/07/22 17:34:08 INFO server.AbstractConnector: Started [email protected]:4040
14/07/22 17:34:08 INFO ui.SparkUI: Started SparkUI at http://localhost:4040
14/07/22 17:34:08 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
--args is deprecated. Use --arg instead.
14/07/22 17:34:08 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
14/07/22 17:34:09 INFO yarn.Client: Got Cluster metric info from ApplicationsManager (ASM), number of NodeManagers: 1
14/07/22 17:34:09 INFO yarn.Client: Queue info ... queueName: default, queueCurrentCapacity: 0.0, queueMaxCapacity: 1.0,
queueApplicationCount = 2, queueChildQueueCount = 0
14/07/22 17:34:09 INFO yarn.Client: Max mem capabililty of a single resource in this cluster 8192
14/07/22 17:34:09 INFO yarn.Client: Preparing Local resources
14/07/22 17:34:09 INFO yarn.Client: Uploading file:/home/hadoop/spark-1.0.1-bin-hadoop2/lib/spark-assembly-1.0.1-hadoop2.2.0.jar to hdfs://localhost:9000/user/hadoop/.sparkStaging/application_1406018656679_0003/spark-assembly-1.0.1-hadoop2.2.0.jar
14/07/22 17:34:12 INFO yarn.Client: Setting up the launch environment
14/07/22 17:34:12 INFO yarn.Client: Setting up container launch context
14/07/22 17:34:12 INFO yarn.Client: Command for starting the Spark ApplicationMaster: List($JAVA_HOME/bin/java, -server, -Xmx512m, -Djava.io.tmpdir=$PWD/tmp, -Dspark.tachyonStore.folderName=\"spark-9c1f20d9-47ba-42e7-8914-057a19e7659f\", -Dspark.yarn.secondary.jars=\"\", -Dspark.home=\"/home/hadoop/spark\", -Dspark.repl.class.uri=\"http://localhost:51297\", -Dspark.driver.host=\"localhost\", -Dspark.app.name=\"Spark shell\", -Dspark.jars=\"\", -Dspark.fileserver.uri=\"http://localhost:38401\", -Dspark.executor.extraClassPath=\"/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar\", -Dspark.master=\"yarn-client\", -Dspark.driver.port=\"58666\", -Dspark.driver.extraClassPath=\"/home/hadoop/spark-1.0.1-bin-hadoop2/lib/*.jar\", -Dspark.httpBroadcast.uri=\"http://localhost:52090\", -Dlog4j.configuration=log4j-spark-container.properties, org.apache.spark.deploy.yarn.ExecutorLauncher, --class, notused, --jar , null, --args 'localhost:58666' , --executor-memory, 1024, --executor-cores, 1, --num-executors , 2, 1>, /stdout, 2>, /stderr)
14/07/22 17:34:12 INFO yarn.Client: Submitting application to ASM
14/07/22 17:34:12 INFO impl.YarnClientImpl: Submitted application application_1406018656679_0003 to ResourceManager at /0.0.0.0:8032
14/07/22 17:34:12 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: ACCEPTED
14/07/22 17:34:13 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: ACCEPTED
14/07/22 17:34:14 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: ACCEPTED
14/07/22 17:34:15 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: ACCEPTED
14/07/22 17:34:16 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: ACCEPTED
14/07/22 17:34:17 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: ACCEPTED
14/07/22 17:34:18 INFO cluster.YarnClientSchedulerBackend: Application report from ASM:
appMasterRpcPort: 0
appStartTime: 1406021652123
yarnAppState: RUNNING
14/07/22 17:34:20 INFO cluster.YarnClientClusterScheduler: YarnClientClusterScheduler.postStartHook done
14/07/22 17:34:21 INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
scala> 14/07/22 17:34:25 INFO cluster.YarnClientSchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@localhost:58394/user/Executor#1230717717] with ID 1
14/07/22 17:34:27 INFO cluster.YarnClientSchedulerBackend: Registered executor: Actor[akka.tcp://sparkExecutor@localhost:39934/user/Executor#520226618] with ID 2
14/07/22 17:34:28 INFO storage.BlockManagerInfo: Registering block manager localhost:52134 with 589.2 MB RAM
14/07/22 17:34:28 INFO storage.BlockManagerInfo: Registering block manager localhost:58914 with 589.2 MB RAM
scala>
scala>
运行结果如下图所示:

application_0003显示已经running 我们又可以愉快的玩耍了~~