c++对象模型系列
一 概括
指针和引用,在C++的软件开发中非常常见,如果能恰当的使用它们能够极大的提 高整个软件的效率,但是很多的C++学习者对它们的各种使用情况并不是都了解,这就导致了实际的软件开发中经常会内存泄漏,异常抛出,程序崩溃等问题。对 于C和C++的初学者,那更是被它们搞的迷迷糊糊。本篇作为[深入C++]系列的第一节,我们就带领大家把指针和引用这个基本功练好。
二 指针
指针,指针的定义是什么呢?好像要想给个直接的定义还是很难的哦,所以我们这里用它的语法结合图来认识它。
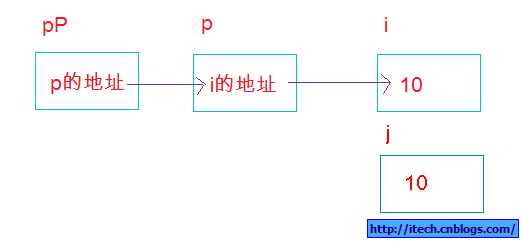
int i = 10;int *p = NULL;p = &i;int j = *p; int **pP = NULL; pP = &p;
在上面的几条语句中,&用来定义引用变量或对变量取其地址,*用来定义指针或得到指针所指向的变量,其中p为定义的指针变量,它指向int变量i,而pP为二级指针变量,它指向指针变量p。相应的示意图如下:
C++是对C的扩展,我们首先来看指针在C中的使用,下面的经典实例来自林锐的 《高质量编程》,记住函数的默认参数传递方式为按值传递,即实参被传入函数内时进行了拷贝,函数内其实是对拷贝对象的操作,还有当函数使用return返 回变量时,其实返回的是原对象的一个拷贝,此时的实参和原对象有可能是一般变量也有可能是指针变量。
#pragma once
#include <cstring>
#include <cstdio>
#include <cstdlib>
// -----------------------------------------------
void GetMemory1(char *p, int num)
{
p = (char*)malloc(num);
}
void Test1(void)
{
char *str = NULL;
GetMemory1(str, 100);
strcpy(str, "hello world");
printf(str);
}
// -----------------------------------------------
void GetMemory2(char **p, int num)
{
*p = (char*)malloc(num);
}
void Test2(void)
{
char * str = NULL;
GetMemory2(&str, 100);
strcpy(str, "hello world");
printf(str);
free(str);
}
// -----------------------------------------------
char* GetMemory3(void)
{
char p[] ="hello world";
return p;
}
void Test3(void)
{
char* str = NULL;
str = GetMemory3();
printf(str);
}
// -----------------------------------------------
char* GetMemory4(void)
{
char *p = "hello world";
return p;
}
void Test4()
{
char* str = NULL;
str = GetMemory4();
printf(str);
}
// -----------------------------------------------
char* GetMemory5(void)
{
char *p = (char*)malloc(100);
strcpy(p,"hello world");
return p;
}
void Test5()
{
char* str = NULL;
str = GetMemory5();
printf(str);
free(str);
}
// -----------------------------------------------
void Test6( void )
{
char * str = (char*)malloc(100);
strcpy(str, "hello");
free(str);
if (str != NULL)
{
strcpy(str, "world" );
printf(str);
}
}
// -----------------------------------------------
void TestPointerAndReference()
{
// -----------------------------------------------
// 请问运行Test1函数会有什么样的结果?
//
// 答:程序崩溃。同时有内存泄漏。
//
// 因为在GetMemory1函数的调用过程中,其实是对实参指针p做了拷贝,拷贝为局部变量,
// 在函数内的操作是对局部变量的操作,局部变量与实参是两个不同的变量,相互不影响。
//
// 所以,当GetMemory1调用结束时,Test1函数中的 str一直都是 NULL。
// strcpy(str, "hello world");将使程序崩溃。
//
//Test1();
// -----------------------------------------------
// 请问运行Test2函数会有什么样的结果?
//
// 答:(1)能够输出hello world; (2)但是调用结束要对内存释放,否则内存泄漏;
//
Test2();
// -----------------------------------------------
// 请问运行Test3函数会有什么样的结果?
//
// 答:可能是乱码。
//
// 因为GetMemory3返回的是指向“栈内存”的指针,
// 该指针的地址不是 NULL,但其原现的内容已经被清除,新内容不可知。
//
Test3();
// -----------------------------------------------
// 请问运行Test4函数会有什么样的结果?
//
// 答:(1)能够输出hello world; (2) 此时的str指向了常量区,不需要程序员释放,程序结束自动释放。
//
Test4();
// -----------------------------------------------
// 请问运行Test5函数会有什么样的结果?
//
// 答:(1)能够输出hello world; (2)但是调用结束要对内存释放,否则内存泄漏;
//
Test5();
// -----------------------------------------------
// 请问运行Test6函数会有什么样的结果?
//
// 答:篡改动态内存区的内容,后果难以预料,非常危险。
//
// 因为free(str);之后,str成为野指针,
// if(str != NULL)语句不起作用。
//
Test6();
}
三 C++指针与引用
引用,其实是变量的别名,与变量是同一个东东。例如 int i = 10; int &a = i; int &b = i; 这样 a,b为i的引用,即a,b为i的别名,还有 int * pi = new int(10); int *& pa = pi; int *& pb = pi; 此时pa,pb为pi的别名。在C++中引入了引用概念后,我们不仅可以定义引用变量,相应的函数的传递方式也增加了按引用传递,当参数以引用方式传递 时,函数调用时不对实参进行拷贝,传入函数内的变量与实参是同一个变量。下面的实例演示了指针和引用在C++的使用。
#pragma once
#include <iostream>
class Point
{
public:
Point(int x, int y)
{
_x = x;
_y = y;
}
void SetX(int x)
{
_x = x;
}
void SetY(int y)
{
_y = y;
}
void PrintPoint()
{
std::cout << "The Point is : "<< '(' << _x << ',' << _y << ')' << std::endl;
}
void PrintPointAdress()
{
std::cout << "The Point's adress is : " << this << std::endl;
}
private:
int _x;
int _y;
};
// 默认按值传递,当传入时对对像进行了拷贝,函数内只是对所拷贝值的修改,所以实参没被修改。
void ChangeValue(Point pt, int x, int y)
{
pt.SetX(x);
pt.SetY(y);
}
// 按引用传递,函数内外同一值,所以修改了实参。
void ChangeValueByReference(Point& pt, int x, int y)
{
pt.SetX(x);
pt.SetY(y);
}
// 通过传递指针,虽然实参指针传入时也产生了拷贝,但是在函数内通过指针任然修改了指针所指的值。
void ChangeValueByPointer(Point *pt, int x, int y)
{
pt->SetX(x);
pt->SetY(y);
}
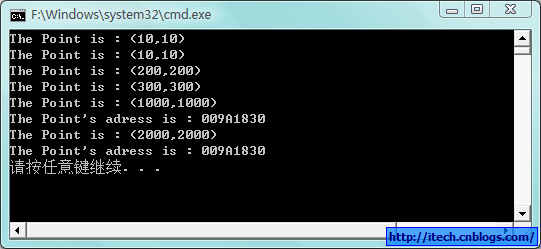
void TestChangeValue()
{
Point pt(10,10);
pt.PrintPoint();
ChangeValue(pt,100,100);
pt.PrintPoint();
ChangeValueByReference(pt,200,200);
pt.PrintPoint();
ChangeValueByPointer(&pt,300,300);
pt.PrintPoint();
}
// 按引用传递,所以指针可以被返回。
void ChangePointerByReference(Point *& pPt, int x, int y)
{
pPt = new Point(x, y);
}
// 对二级指针拷贝,但是二级指针指向的一级指针被返回。
void ChangePointerByTwoLevelPointer(Point **pPt, int x, int y)
{
*pPt = new Point(x, y);
}
void TestChangePointer()
{
Point *pPt = NULL;
ChangePointerByReference(pPt, 1000,1000);
pPt->PrintPoint();
pPt->PrintPointAdress();
delete pPt;
pPt = NULL;
int *p = new int(10);
//int *p2 = new int(10);
//int *p3 = new int(10);
ChangePointerByTwoLevelPointer(&pPt, 2000,2000);
pPt->PrintPoint();
pPt->PrintPointAdress();
delete pPt;
pPt = NULL;
}
void TestPointerAndReference2()
{
TestChangeValue();
TestChangePointer();
}
运行结果如下:
四 函数参数传递方式,函数中return语句和拷贝构造函数的关系
通过上面的2个实例,如果还有人对函数的参数传递方式和return有疑问的啊,可以对下面的代码亲自debug。
#pragma once
#include <iostream>
class CopyAndAssign
{
public:
CopyAndAssign(int i)
{
x = i;
}
CopyAndAssign(const CopyAndAssign& ca)
{
std::cout << "拷贝构造!" << std::endl;
x = ca.x;
}
CopyAndAssign& operator=(const CopyAndAssign& ca)
{
std::cout << "赋值操作符" << std::endl;
x = ca.x;
return *this;
}
private:
int x;
};
CopyAndAssign ReturnCopyAndAssign()
{
CopyAndAssign temp(20); // 构造
return temp;
}
void CopyAndAssignAsParameter(CopyAndAssign ca)
{
}
CopyAndAssign& ReturnCopyAndAssignByReference()
{
CopyAndAssign temp(20); // 构造
return temp;
}
void CopyAndAssignAsParameterByReference(CopyAndAssign& ca)
{
}
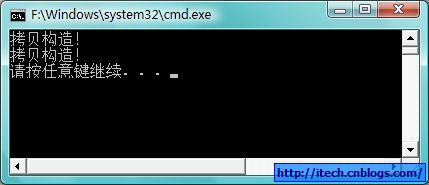
void TestCopyAndAssign()
{
CopyAndAssign c1(10); // 构造
CopyAndAssignAsParameter(c1); // 拷贝构造
ReturnCopyAndAssign(); // 拷贝构造
CopyAndAssignAsParameterByReference(c1);
ReturnCopyAndAssignByReference();
}
亲自debug,效果会更好,运行结果如下:
五 总结
1) 指针也是变量,它存储其他变量的地址。例如int *p = new int(10); p是指针变量,p实际是存储了一个int变量的地址。
2)引用其实是一个别名,跟原对象是同一个东东。例如 std::string str = "hello"; std::string & strR = str;此时strR跟str其实是同一个东东,strR可以看成是str的一个小名。
3) 函数默认的传参方式为按值传递,即当实参传入是其实是做了拷贝,函数内其实是对所拷贝对象的操作。例如 void Increase(int x) { x++; } 调用时 int i = 10; Increase(i); Increase函数内部其实是对i的一个拷贝(我们假设为ii)进行++。所以在函数调用结束后原来的i的值仍然保持不变。
4)函数的传参方式 可以显示的指定按引用来传递,按引用传递时,函数内即对实参的操作,没有拷贝操作,所以函数内对实参的修改,当然后调用结束后反映到实参上。例如void Increase(int & x) { x++;} 调用 int i = 10; Increase(i);此时Increase内部的++即是对i的操作,所以函数调用结束后i的值被修改。
5)函数中如果有return返回变量时,其实所返回的也是一个拷贝。所以当使用return返回对象时一定要考虑所返回对象的拷贝构造函数是否能够满足要求。
六 使用注意
1) malloc/free一起使用。
2)new/delete一起使用。
3)对于new中有[]时,相应的必须使用delete[]来释放。
4)用free或delete释放了内存之后,立即将指针设置为NULL,防止产生“野指针”。
5)对指针的使用前,应该检查是否为空,空指针可能导致程序崩溃。
6)非内置类型的参数传递,使用const引用代替一般变量。
七 谢谢!
二 指针与数组
一 C指针操作函数
new和delete对C++的程序员也许很熟悉,但是malloc和free被用来在C代码中用来内存分配和释放,很多C++开发者并不能游刃有余的使用,下面实例解析malloc和free的使用。
| malloc | void *malloc(long NumBytes):该函数分配了NumBytes个字节,并返回了指向这块内存的指针。如果分配失败,则返回一个空指针(NULL)。 |
| free | void free(void *FirstByte): 该函数是将之前用malloc分配的空间还给程序或者是操作系统,也就是释放了这块内存,让它重新得到自由。 |
实例如下:
#pragma once
#include <string>
void TestMallocAndFree()
{
char *ptr = NULL;
ptr = (char*)malloc(100 * sizeof(char));
if (NULL == ptr)
{
return;
}
memcpy(ptr,"Hello!",strlen("Hello!"));
free(ptr);
ptr = NULL;
typedef struct data_type
{
int age;
char *name;
} data;
data *willy = NULL;
willy = (data*) malloc( sizeof(data) );
willy->age = 20;
willy->name = "jason"; // 此时的name指向了常量区,所以name指针不需要程序员释放。
free( willy );
willy = NULL;
}
malloc/free 和new/delete的区别:
1)new/delete是保留字,不需要头文件支持. malloc/free需要头文件库函数支持. 使用malloc/free需要包含 #include
2) new 建立的是一个对象,new会根据对象计算大小,直接返回对象的指针,当使用完毕后调用delete来释放,但malloc分配的是一块内存,需要用户制定 所要分配内存的大小,而且返回的均为void的指针,使用时需要相应的强制类型转化,使用结束后调用free来释放内存.
3)new/delete的使用除了分配内存和释放,还调用了类型的构造函数和析构函数,而malloc/free只是简单的分配和释放内存。
二 数组与指针
C++的数组经常需要和指针来结合使用,下面来进行相关的强化训练。实例如下:
#pragma once
#include <iostream>
using namespace std;
void PrintArray(double *p, int num)
{
for(int i = 0; i < num; ++i)
{
cout << " " << p[i] << " ";
}
cout << endl << "The array is end!" << endl;
}
void PrintArray(double arr[3])
{
for(int i = 0; i < 3; ++i)
{
cout << " " << *(arr+i)/*arr[i]*/ << " ";
}
cout << endl << "The array is end!" << endl;
}
void ChangeArray(double arr[3]) // 数组传参为传指针,所以函数内可以修改
{
for(int i = 0; i < 3; ++i)
{
arr[i] = 10;
}
}
void PrintArray(double arr[3][3])
{
for(int i = 0; i < 3; ++i)
for(int j = 0; j < 3; ++j)
cout << " " << arr[i][j] << " ";
cout << endl << "The array is end!" << endl;
}
int GetLength(){return 3;}
void TestArray()
{
// 数组的定义和初始化
short months[12] = {31,28,31,30,31,30,31,31,30,31,30,31};
double arr[3];
arr[0] = 1.0;
arr[1] = 2.0;
arr[2] = 3.0;
double arr2[] = {1.0,2.0,3.0};
//double arr3[3] = arr; // error
PrintArray(arr,3);
PrintArray(&arr[0],3);
PrintArray(arr2);
double matrix2 [2][2] = {1.0,0.0,0.0,1.0};
double matrix3 [3][3] = {{1.0,0.0,0.0},
{0.0,1.0,0.0},
{0.0,0.0,1.0}};
PrintArray(matrix3[0],3*3);
PrintArray(&matrix3[0][0],3*3);
//PrintArray(matrix3,3*3);
PrintArray(matrix3);
// 指针来模拟数组
double *p3 = new double[GetLength()];
p3[0] = 10.0;
p3[1] = 20.0;
p3[2] = 30.0;
PrintArray(p3,3);
PrintArray(p3);
delete []p3;
// 数组+指针实现二维变长数组
double *p4[2];
p4[0] = new double[2];
p4[1] = new double[4];
p4[0][0] = 10;
p4[0][1] = 20;
p4[1][0] = 30;
p4[1][1] = 40;
p4[1][2] = 50;
p4[1][3] = 60;
PrintArray(p4[0],2);
PrintArray(p4[1],4);
delete [] p4[0];
delete [] p4[1];
PrintArray(arr); // 数组传参为传指针,所以函数内可以修改
ChangeArray(arr);
PrintArray(arr);
}
代码分析总结:
1)数组的定义必须使用常量指定长度,例如:double arr[3],但是使用指针时可以是运行时指定,例如double *p3 = new double[getLength()]。
2)数组定义时即分配空间且在栈上,不需要程序员来对内存管理,但是如果对指针使用了new[],则必须由程序员在使用完毕后delete[]。
3) 一维数组数组名即第一个元素的地址,例如:double arr[3]中,arr == &arr[0]为true。
4)二维数组中第一行的地址即为第一个元素的地址,例如:double matrix3 [3][3],matrix[0] == &matrix[0][0]为true。
5)可以使用指针数组来模拟变长二维数组,例如:double *p4[2]; p4[0] = new double[2]; p4[1] = new double[4];
6)二维数组内存中同一维数组仍为连续的区域,所以可以将二维数组和一维相互转化。
7)一维数组名即为第一个元素的地址,所以可以同指针隐式转化,但二维数组名不是第一个元素地址,所以不能转化。
8) 当函数传入数组,实际传首元素的指针,所以可以在函数内修改数组元素。
三 完!
感谢,Thanks!
三 指针与字符串
开始之前必须明确strlen的含义,原型为size_t strlen( char *str ); strlen返回字符串的长度,即null("0)之前的字符的数量。
一 char* 与 char []
实例加注释:
void TestCharPointerAndArray()
{
char *c1= "abc";//abc"0常量区,c1在栈上, 常量区程序结束后自动释放。
//c1[1] = 'g';// 常量不能修改
int i= strlen(c1);// 3
char c2[]= "abc";// c2,abc"0都在栈上
c2[1]= 'g';// 可以修改
int j= strlen(c2);// 3
int jj= sizeof(c2);// 4
char *c3= ( char* )malloc(4* sizeof(char));// c3 栈上
memcpy(c3,"abc",4);// abc"0 在堆上, 4 = 3(strlen("abc")) + 1('"0');
c3[1]= 'g';// 可以修改
int x= strlen(c3);// 3
free(c3); //如果这里不free,会内存泄漏
c3 = "abc";// abc"0 在常量区,c3指向了常量区
//c3[1] = 'g';// 常量不能修改
int y= strlen(c3);// 3
}
字符串都以"0结尾,所以例如:char *c1= "abc";char c2[] = "abc";,使用strlen得到长度都为3,但是实际的存储空间为strlen+1即3+1。
二 C中字符串操作函数
C++的程序员对C中的字符串指针操作的函数却并不是相当的熟悉。而C中的这些字符串的指针操作函数有的时候也是必须要面对的,比如我们的库要提供 C函数接口,保持向后兼容和跨平台,还有我们经常使用一些第三方的库中都或多或少的使用到了这些C中的指针操作函数,所以下面列出C的指针操作函数,帮助 大家熟悉之。
1) memcpy/memset/memcmp
| memcpy |
原型:extern void *memcpy( void *to, const void *from, size_t count ); |
| memset |
原型:extern void* memset( void* buffer, int ch, size_t count ); |
| memcmp |
原型:extern int memcmp(const void *buffer1, const void *buffer2, size_t count ); |
memchr |
原型: extern void *memchr( const void *buffer, int ch, size_t count ); 包含:#include 功能:查找ch在buffer中第一次出现的位置。 说明:如果发现返回指针,如果没有返回NULL。 |
实例:
void TestMemFunction()
{
char *s1="Hello!";// Hello!"0
int l= strlen(s1);// 6
char *d1= new char[l+1];// d1 需要strlen(s1) + 1 空间
memcpy(d1,s1,l+1);
memcpy(d1,d1,l);
memmove(d1 + 1,d1,l-1);
const int ARRAY_LENGTH= 5;
char the_array[ARRAY_LENGTH];
// zero out the contents of the_array
memset( the_array, 'c', ARRAY_LENGTH );
char *a1= "source1";
char arr1[8]= "source2";
int r = memcmp(a1,arr1,strlen(a1)- 1);// 仅比较source,所以相等
char str[17];
char *ptr;
strcpy(str, "This is a string");
ptr = (char*)memchr(str,'r', strlen(str));
}
2) strlen/strcpy/strcat/strcmp/strchr/strcoll/strstr/strtok/strtod/strtol
strcpy |
char *strcpy(char *s1, const char *s2) 将字符串s2复制到字符串数组s1中,返回s1的值 |
strcat |
char *strcat(char *s1, const char *s2) |
strcmp |
int strcmp(const char *s1, const char *s2) |
| strchr | char *strchr(char * str,int c ); 在str中查找c第一次出现的位置。 |
| strstr | char *strstr(char *str,const char *strSearch );在string1中查找string2第一次出现的位置。 |
| strtok | char *strtok(char *strToken,const char *strDelimit ); 分割字符串。 |
实例:
void TestStrFunction()
{
char string[11];
char *str1 = "123456789"; // 123456789"0
strcpy(string, str1);
strcat(string,"A"); //123456789A"0
int r = strcmp(string,"123456789B"); // 123456789A"0 < 123456789B"0
}
void TestStrFunction2()
{
int ch = 'r';
char string[] = "The quick # brown dog # jumps over # the lazy fox";
char *pdest = NULL;
pdest = strchr( string, ch );
pdest = NULL;
char * str = "dog";
pdest = strstr(string,str);
pdest = NULL;
char delims[] = "#";
pdest = strtok( string, delims );
while( pdest != NULL )
{
pdest = strtok( NULL, delims );
}
}
总结:
1)以mem开始的函数用来bytes的操作,所以需要指定长度,但是以str用来操作以"0结尾的字符串,不需要指定长度。
2)对于unicode,相应的字符串操作函数前缀为wcs,例如wcscpy,wcscat,wcscmp,wcschr,wcsstr,wcstok等。
3)在vc中还提供了有安全检测的字符串函数后缀_s,例如strcpy_s,strcat_s,strcmp_s,wcscpy_s,wcscat_s,wcscmp_s等。
4)char*如果指向常量区,不能被修改,且此char*不需要delete。例如 char* pStr = "ABC";。
三 std::string和std::wstring使用相当简单哦!
四 完!
感谢,Thanks!
四 堆栈与函数调用
一 C++程序内存分配
1) 在栈上创建。在执行函数时,函数内局部变量的存储单元都在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,一般使用寄存器来存取,效率很高,但是分配的内存容量有限。
2) 从堆上分配,亦称动态内存分配。程序在运行的时候用malloc或new申请任意多少的内存,程序员自己负责在何时用free或delete来释放内存。动态内存的生存期由程序员自己决定,使用非常灵活。
3) 从静态存储区域分配。内存在程序编译的时候就已经分配好,这块内存在程序的整个运行期间都存在。例如全局变量,static变量。
4) 文字常量分配在文字常量区,程序结束后由系统释放。
5)程序代码区。
经典实例:(代码来自网络高手,没有找到原作者)
#include <string>
int a=0; //全局初始化区
char *p1; //全局未初始化区
void main()
{
int b;//栈
char s[]="abc"; //栈
char *p2; //栈
char *p3="123456"; //123456"0在常量区,p3在栈上。
static int c=0; //全局(静态)初始化区
p1 = (char*)malloc(10);
p2 = (char*)malloc(20); //分配得来得10和20字节的区域就在堆区。
strcpy(p1,"123456"); //123456"0放在常量区,编译器可能会将它与p3所向"123456"0"优化成一个地方。
}
二 三种内存对象的比较
栈对象的优势是在适当的时候自动生成,又在适当的时候自动销毁,不需要程序员操心;而且栈对象的创建速度一般 较堆对象快,因为分配堆对象时,会调用operator new操作,operator new会采用某种内存空间搜索算法,而该搜索过程可能是很费时间的,产生栈对象则没有这么麻烦,它仅仅需要移动栈顶指针就可以了。但是要注意的是,通常栈 空间容量比较小,一般是1MB~2MB,所以体积比较大的对象不适合在栈中分配。特别要注意递归函数中最好不要使用栈对象,因为随着递归调用深度的增加, 所需的栈空间也会线性增加,当所需栈空间不够时,便会导致栈溢出,这样就会产生运行时错误。
堆对象创建和销毁都要由程序员负责,所以,如果 处理不好,就会发生内存问题。如果分配了堆对象,却忘记了释放,就会产生内存泄漏;而如 果已释放了对象,却没有将相应的指针置为NULL,该指针就是所谓的“悬挂指针”,再度使用此指针时,就会出现非法访问,严重时就导致程序崩溃。但是高效 的使用堆对象也可以大大的提高代码质量。比如,我们需要创建一个大对象,且需要被多个函数所访问,那么这个时候创建一个堆对象无疑是良好的选择,因为我们 通过在各个函数之间传递这个堆对象的指针,便可以实现对该对象的共享,相比整个对象的传递,大大的降低了对象的拷贝时间。另外,相比于栈空间,堆的容量要 大得多。实际上,当物理内存不够时,如果这时还需要生成新的堆对象,通常不会产生运行时错误,而是系统会使用虚拟内存来扩展实际的物理内存。
静态存储区。所有的静态对象、全局对象都于静态存储区分配。关于全局对象,是在main()函数执行前就分配好了的。其实,在main()函数中的显示代 码执行之前,会调用一个由编译器生成的_main()函数,而_main()函数会进行所有全局对象的的构造及初始化工作。而在main()函数结束之 前,会调用由编译器生成的exit函数,来释放所有的全局对象。比如下面的代码:
| void main(void) |
实际上,被转化成这样:
| void main(void) |
除了全局静态对象,还有局部静态对象通和class的静态成员,局部静态对象是在函数中定义的,就像栈对象一样,只不过,其前面多了个 static关键字。局部静态对象的生命期是从其所在函数第一次被调用,更确切地说,是当第一次执行到该静态对象的声明代码时,产生该静态局部对象,直到 整个程序结束时,才销毁该对象。class的静态成员的生命周期是该class的第一次调用到程序的结束。
三 函数调用与堆栈
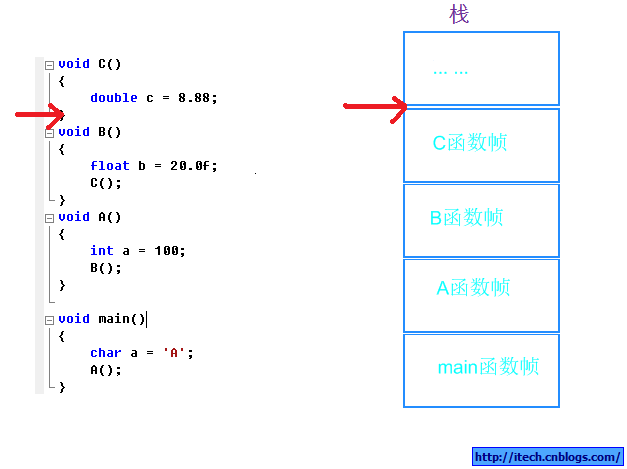
1)编译器一般使用栈来存放函数的参数,局部变量等来实现函数调用。有时候函数有嵌套调用,这个时候栈中会有多个函数的信息,每个函数占用一个连续的区域。一个函数占用的区域被称作帧(frame)。同时栈是线程独立的,每个线程都有自己的栈。例如下面简单的函数调用:
另外函数堆栈的清理方式决定了当函数调用结束时由调用函数或被调用函数来清理函数帧,在VC中对函数栈的清理方式由两种:
| 参数传递顺序 | 谁负责清理参数占用的堆栈 | |
| __stdcall | 从右到左 | 被调函数 |
| __cdecl | 从右到左 | 调用者 |
2) 有了上面的知识为铺垫,我们下面细看一个函数的调用时堆栈的变化:
代码如下:
int Add(int x, int y)
{
return x + y;
}
void main()
{
int *pi = new int(10);
int *pj = new int(20);
int result = 0;
result = Add(*pi,*pj);
delete pi;
delete pj;
}
对上面的代码,我们分为四步,当然我们只画出了我们的代码对堆栈的影响,其他的我们假设它们不存在,哈哈!
第一,int *pi = new int(10); int *pj = new int(20); int result = 0; 堆栈变化如下:
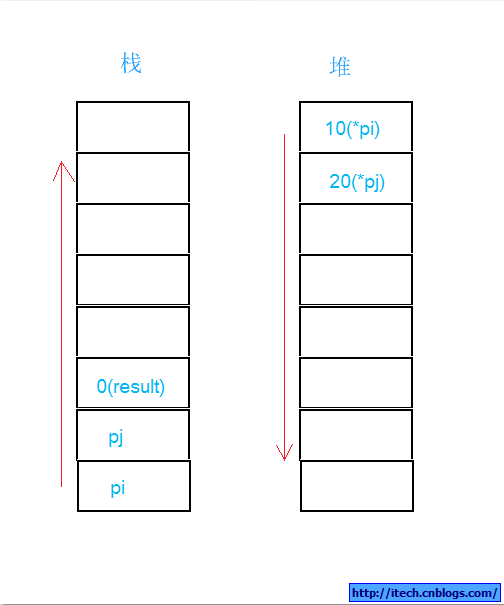
第二,Add(*pi,*pj);堆栈如下:
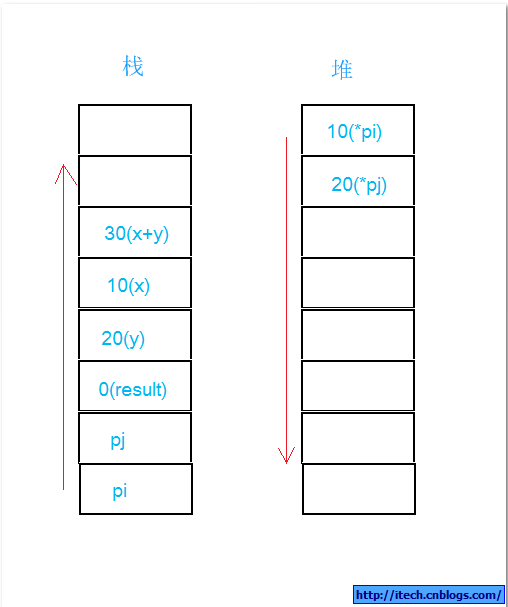
第三,将Add的结果给result,堆栈如下:

第四,delete pi; delete pj; 堆栈如下:

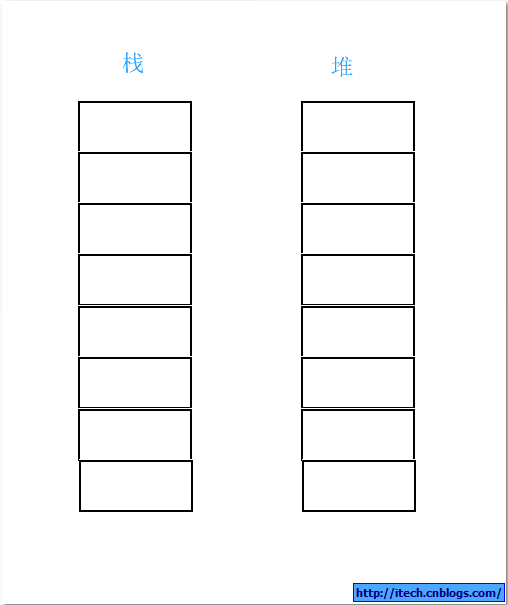
第五,当main()退出后,堆栈如下,等同于main执行前,哈哈!
四 完!
感谢,Thanks!
五 sizeof与内存布局
有了前面几节的铺垫,本节开始摸索C++的对象的内存布局,平台为windows32位+VS2008。
一 内置类型的size
内置类型,直接上代码,帮助大家加深记忆:
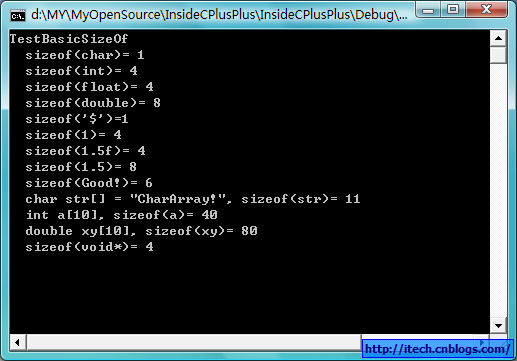
void TestBasicSizeOf()
{
cout << __FUNCTION__<< endl;
cout << " sizeof(char)=" << sizeof (char ) << endl;
cout << " sizeof(int)=" << sizeof (int ) << endl;
cout << " sizeof(float)=" << sizeof (float ) << endl;
cout << " sizeof(double)=" << sizeof (double ) << endl;
cout << " sizeof('$')=" << sizeof ( '$' )<< endl;
cout << " sizeof(1)=" << sizeof (1 ) << endl;
cout << " sizeof(1.5f)=" << sizeof (1.5f ) << endl;
cout << " sizeof(1.5)=" << sizeof (1.5 ) << endl;
cout << " sizeof(Good!)=" << sizeof ("Good!" )<< endl ;
char str[]= "CharArray!";
int a[10];
double xy[10];
cout << " char str[] = ""CharArray!""," << " sizeof(str)= " << sizeof (str)<< endl;
cout << " int a[10]," << " sizeof(a)= " << sizeof (a)<< endl;
cout << " double xy[10]," << " sizeof(xy)= " << sizeof (xy) << endl;
cout << " sizeof(void*)=" << sizeof(void*)<< endl;
}
运行结果如下:
二 struct/class的大小
在C++中我们知道struct和class的唯一区别就是默认的访问级别不同,struct默认为public,而class的默认为 private。所以考虑对象的大小,我们均以struct为例。对于struct的大小对于初学者来说还确实是个难回答的问题,我们就通过下面的一个 struct定义加逐步的变化来引出相关的知识。
代码如下:
struct st1
{
short number;
float math_grade;
float Chinese_grade;
float sum_grade;
char level;
}; //20
struct st2
{
char level;
short number;
float math_grade;
float Chinese_grade;
float sum_grade;
};//16
#pragma pack(1)
struct st3
{
char level;
short number;
float math_grade;
float Chinese_grade;
float sum_grade;
}; //15
#pragma pack()
void TestStructSizeOf()
{
cout << __FUNCTION__ << endl;
cout << " sizeof(st1)= " << sizeof (st1) << endl;
cout << " offsetof(st1,number) " << offsetof(st1,number) << endl;
cout << " offsetof(st1,math_grade) " << offsetof(st1,math_grade) << endl;
cout << " offsetof(st1,Chinese_grade) " << offsetof(st1,Chinese_grade) << endl;
cout << " offsetof(st1,sum_grade) " << offsetof(st1,sum_grade) << endl;
cout << " offsetof(st1,level) " << offsetof(st1,level) << endl;
cout << " sizeof(st2)= " << sizeof (st2) << endl;
cout << " offsetof(st2,level) " << offsetof(st2,level) << endl;
cout << " offsetof(st2,number) " << offsetof(st2,number) << endl;
cout << " offsetof(st2,math_grade) " << offsetof(st2,math_grade) << endl;
cout << " offsetof(st2,Chinese_grade) " << offsetof(st2,Chinese_grade) << endl;
cout << " offsetof(st2,sum_grade) " << offsetof(st2,sum_grade) << endl;
cout << " sizeof(st3)= " << sizeof (st3) << endl;
cout << " offsetof(st3,level) " << offsetof(st3,level) << endl;
cout << " offsetof(st3,number) " << offsetof(st3,number) << endl;
cout << " offsetof(st3,math_grade) " << offsetof(st3,math_grade) << endl;
cout << " offsetof(st3,Chinese_grade) " << offsetof(st3,Chinese_grade) << endl;
cout << " offsetof(st3,sum_grade) " << offsetof(st3,sum_grade) << endl;
}
运行结果如下;
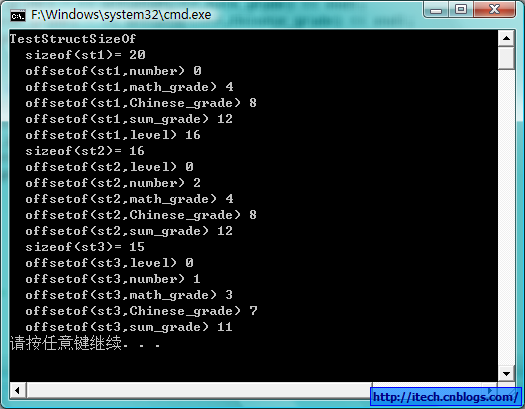
基于上面的对struct的测试,我们是不是有些惊呆哦,对于C++的初学者更是情不自禁的说:“我靠!原来顺序不同所占空间都不同啊,还有那个 pack是啥东东啊?”,其实这里蕴含了一个内存对齐的问题,在计算机的底层进行内存的读写的时候,如果内存对齐的话可以提高读写效率,下面是VC的默认 规则:
1) 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2) 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍, 如有需要编译器会在成员之间加上填充字节(internal adding);
3) 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节(trailing padding)。
当然VC提供了工程选项/Zp[1|2|4|8|16]可以修改对齐方式,当然我们也可以在代码中对部分类型实行特殊的内存对齐方式,修改方式为#pragma pack( n ),n为字节对齐
数,其取值为1、2、4、8、16,默认是8,取消修改用#pragma pack(),如果结构体某成员的sizeof大于你设置的,则按你的设置来对齐。
三 struct的嵌套
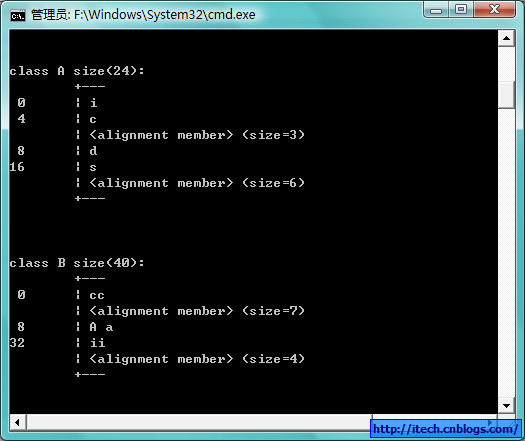
1)实例:
struct A
{
int i;
char c;
double d;
short s;
}; // 24
struct B
{
char cc;
A a;
int ii;
}; // 40
布局:(使用VS的未发布的编译选项/d1 reportAllClassLayout 或 /d1 reportSingleClassLayout)
2)实例:
#pragma pack(4)
struct A2
{
int i;
char c;
double d;
short s;
}; // 20
#pragma pack()
struct B2
{
char cc;
A2 a;
int ii;
}; // 28
布局:(使用VS的未发布的编译选项/d1 reportAllClassLayout 或 /d1 reportSingleClassLayout)
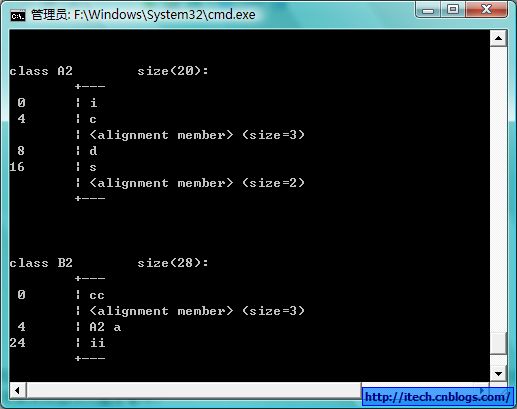
总结:
由于结构体的成员可以是复合类型,比如另外一个结构体,所以在寻找最宽基本类型成员时,应当包括复合类型成员的子成员,而不是把复合成员看成是一个整体。但在确定复合类型成员的偏移位置时则是将复合类型作为整体看待。
四 空struct/class和const,static成员
实例:
struct empty{}; // 1
struct constAndStatic
{
const int i;
static char c;
const double d;
static void TestStatic(){}
void TestNoStatic(){}
}; // 16
布局:(使用VS的未发布的编译选项/d1 reportAllClassLayout 或 /d1 reportSingleClassLayout)
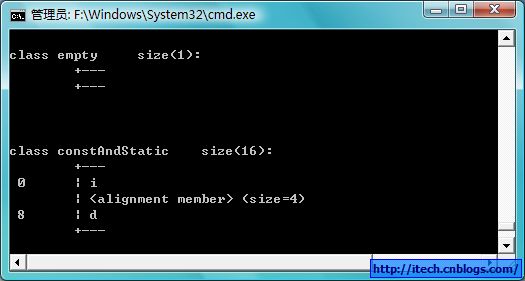
上面的实例中empty的大小为1,而constAndStatic的大小为16。
总结:
因为static成员和函数其实是类层次的,不在对象中分配空间,而成员函数其实是被编译为全局函数了,所以也不在对象中。
五 本节完,下次探讨虚函数对内存布局的影响!
感谢,Thanks!
六 单继承与虚函数表
一 单继承
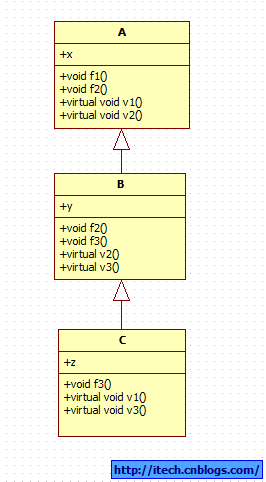
1) 代码:
#include <iostream>
using namespace std;
class A
{
public:
void f1(){cout << "A::f1" << endl;}
void f2(){cout << "A::f2" << endl;}
virtual void v1(){cout << "A::v1" << endl;}
virtual void v2(){cout << "A::v2" << endl;}
int x;
};
class B : public A
{
public:
void f2(){cout << "B::f2" << endl;} // 覆盖
void v2(){cout << "B::v2" << endl;} // 重写
void f3(){cout << "B::f3" << endl;}
virtual void v3(){cout << "B::v3" << endl;}
int y;
};
class C : public B
{
public:
void f3(){cout << "C::f3" << endl;} // 覆盖
void v1(){cout << "C::v1" << endl;} // 重写
void v3(){cout << "C::v3" << endl;} // 重写
int z;
};
2)类图:
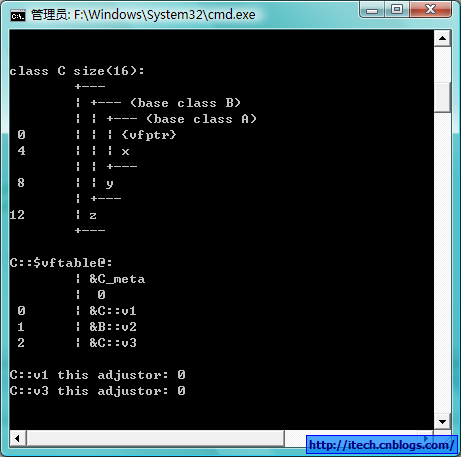
3)VS2008的编译选项查看布局:
4)可视化表示:

5)代码验证:
typedef void (*Fun)();
void PrintVTable(A *pA)
{
int *pVT = (int*)*(int*)(pA);
Fun* pF = (Fun*)(pVT + 0);
int iLength = 0;
while(*pF != NULL)
{
(*pF)();
++iLength;
pF = (Fun*)(pVT + iLength);
}
}
void PrintMembers(A *pA)
{
int *p = (int*)(pA);
int i = 1;
while(i <= 3)
{
cout << *(p+i) << endl;
i++;
}
}
void TestVT()
{
A *pA = new C();
C *pC = dynamic_cast<C*>(pA);
pC->x = 10;
pC->y = 20;
pC->z = 30;
PrintVTable(pA);
PrintMembers(pA);
delete pA;
}
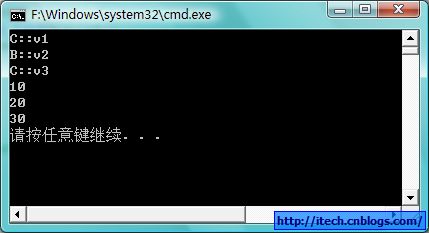
6)验证代码运行结果:
7)总结:
单继承的对象的布局,第一个为虚函数表指针vtbl,其后为成员且先基类后子类,虚函数表里包含了所有的虚函数的地址,以NULL结束。虚函数如果子类有重写,就由子类的重新的代替。
二 单继承运行时类型转化
1)代码验证:
void TestDynamicCast()
{
A *pA = new C();
cout << "A:" << pA << endl;
B *pB = dynamic_cast<B*>(pA);
cout << "B:" << pB << endl;
C *pC = dynamic_cast<C*>(pA);
cout << "C:" << pC << endl;
}
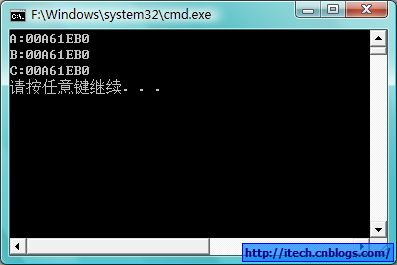
2)验证代码运行结果:
3)总结:
我们上面看了单继承的内存布局,而这样的内存布局也就决定了当dynamic_cast的时候,都还是同一地址,不需要做指针的移动。只是类型的改变即所能访问的范围的改变。
三 完!
感谢,Thanks!
七 多继承与虚函数表
利用vs自带的控制台来进行cl编译器查看类的布局:
cl test3.cpp /-d1reportSingleClassLayoutBase 这段语句是查看test3.cpp文件中Base类的布局
一 多重继承
1) 代码:
#include <iostream>
using namespace std;
class B1
{
public:
int x;
virtual void v1(){ cout << "B1::v1" << endl; }
void f1(){cout << "B1::f1" << endl; }
};
class B2
{
public:
int y;
virtual void v2(){ cout << "B2::v2" << endl; }
void f2(){ cout << "B2::f2" << endl; }
};
class B3
{
public:
int z;
virtual void v3(){ cout << "B3::v3" << endl; }
void f3(){ cout << "B3::f3" << endl; }
};
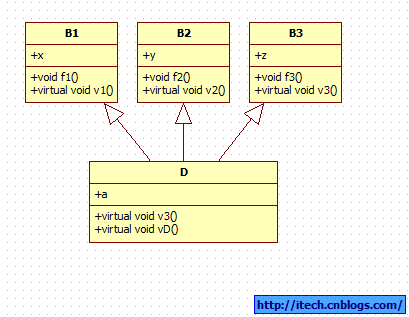
class D : public B1, public B2, public B3
{
public:
int a;
void v3(){ cout << "D::v3" << endl; }
virtual void vD(){ cout << "D::vD" << endl; }
};
2)类图:
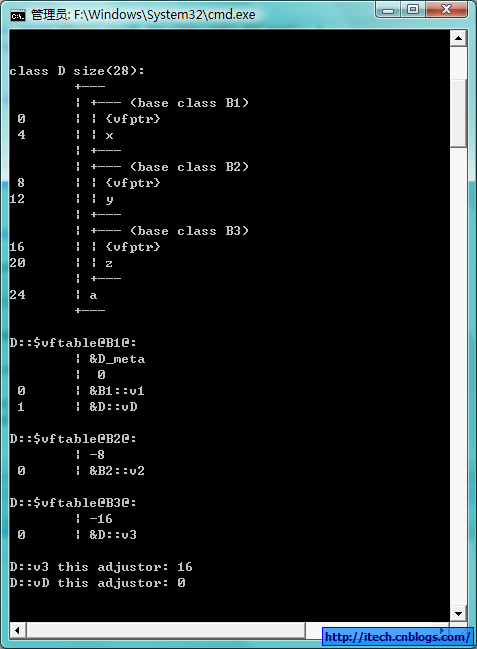
3)VS2008的编译选项查看布局:
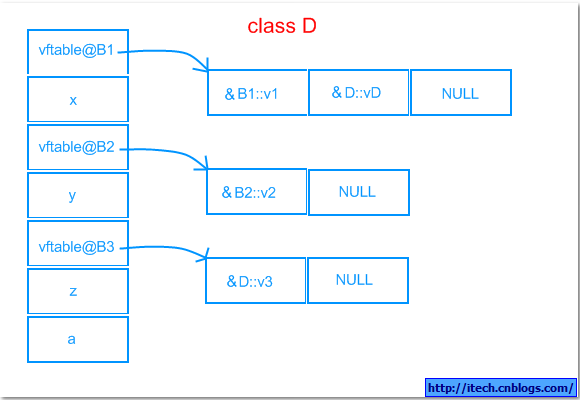
4)可视化表示:
5)代码验证:
typedef void (*Fun)();
void PrintMember(int *pI)
{
cout << *pI << endl;
}
void PrintVT(int *pVT)
{
while(*pVT != NULL)
{
(*(Fun*)(pVT))();
pVT++;
}
}
void PrintVTAndMember(B1 *pD)
{
int *pRoot = (int*)pD;
int *pVTB1 = (int*)*(pRoot + 0);PrintVT(pVTB1);
int *pMB1 = pRoot +1; PrintMember(pMB1);
int *pVTB2 = (int*)*(pRoot + 2);PrintVT(pVTB2);
int *pMB2 = pRoot +3; PrintMember(pMB2);
int *pVTB3 = (int*)*(pRoot + 4);PrintVT(pVTB3);
int *pMB3 = pRoot +5; PrintMember(pMB3);
}
void TestVT()
{
B1 *pB1 = new D();
D *pD = dynamic_cast<D*>(pB1);
pD->x = 10;
pD->y = 20;
pD->z = 30;
pD->a = 40;
PrintVTAndMember(pD);
delete pD;
}
6) 验证代码运行结果:
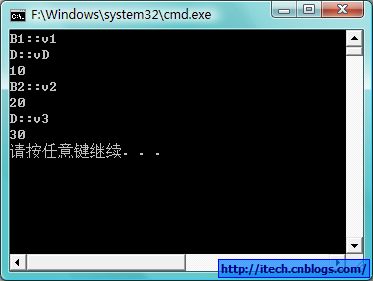
7)总结:
与单继承相同的是所有的虚函数都包含在虚函数表中,所不同的多重继承有多个虚函数表,当子类对父类的虚函数有重写时,子类的函数覆盖父类的函数在对应的虚函数位置,当子类有新的虚函数时,这些虚函数被加在第一个虚函数表的后面。
二 多重继承运行时类型转化
1)代码验证:
void TestDynamicCast()
{
B1 *pB1 = new D();
cout << "B1:" << pB1 << endl;
D *pD = dynamic_cast<D*>(pB1);
cout << "D:"<< pD << endl;
B2 *pB2 = dynamic_cast<B2*>(pB1);
cout << "B2:" << pB2 << endl;
B3 *pB3 = dynamic_cast<B3*>(pB1);
cout << "B3:" << pB3 << endl;
delete pD;
}
2)验证代码的运行结果:
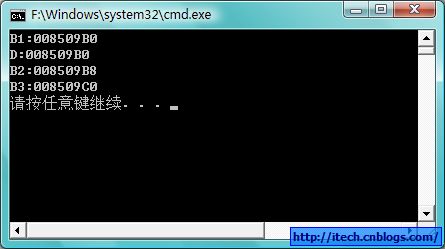
3)总结:
从多重继承的内存布局,我们可以看到子类新加入的虚函数被加到了第一个基类的虚函数表,所以当dynamic_cast的时候,子类和第一个基类的地址相同,不需要移动指针,但是当dynamic_cast到其他的父类的时候,需要做相应的指针的移动。
三 完!
感谢,Thanks!
八 虚继承与虚函数表
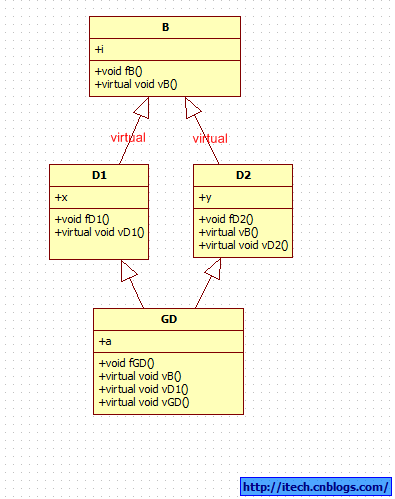
一 虚继承
1) 代码:
#include <iostream>
using namespace std;
class B
{
public:
int i;
virtual void vB(){ cout << "B::vB" << endl; }
void fB(){ cout << "B::fB" << endl;}
};
class D1 : virtual public B
{
public:
int x;
virtual void vD1(){ cout << "D1::vD1" << endl; }
void fD1(){ cout << "D1::fD1" << endl;}
};
class D2 : virtual public B
{
public:
int y;
void vB(){ cout << "D2::vB" << endl;}
virtual void vD2(){ cout << "D2::vD2" << endl;}
void fD2(){ cout << "D2::fD2" << endl;}
};
class GD : public D1, public D2
{
public:
int a;
void vB(){ cout << "GD::vB" << endl;}
void vD1(){cout << "GD::vD1" << endl;}
virtual void vGD(){cout << "GD::vGD" << endl;}
void fGD(){cout << "GD::fGD" << endl;}
};
2)类图:
3)VS2008的编译选项查看布局:
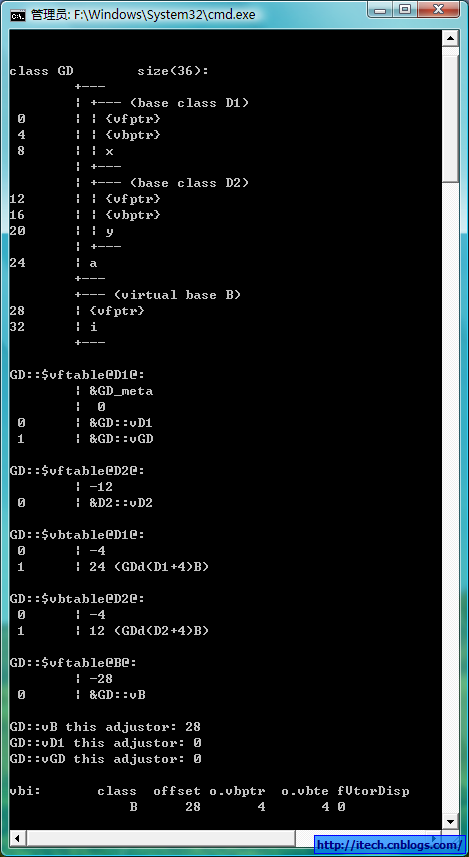
4)可视化表示:
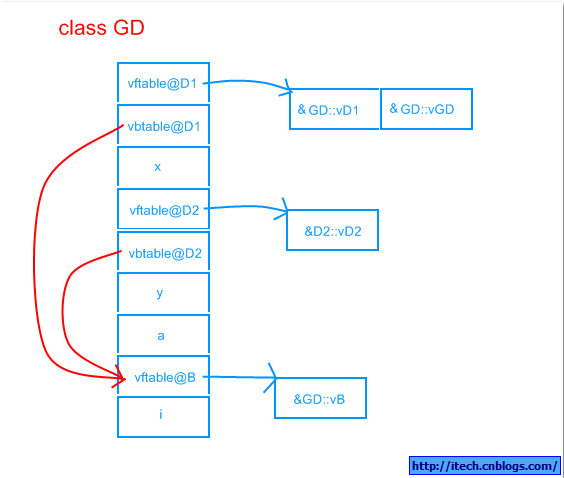
5)代码验证:(此时的虚函数表不是以NULL结尾,为什么?)
typedef void (*Fun)();
void PrintMember(int *pI)
{
cout << *pI << endl << endl;
}
void PrintVT(int *pVT)
{
while(*pVT != NULL)
{
(*(Fun*)(pVT))();
pVT++;
}
}
void PrintMemberAndVT(GD *pGD)
{
int *pRoot = (int*)pGD;
int *pD1VT = (int*)*(pRoot + 0);
(*(Fun*)(pD1VT))(); (*(Fun*)(pD1VT +1))();
int *pVB = (int*)*(pRoot +1); cout << "vbtable's adress:" << *pVB << endl;
int *pX = (pRoot + 2); PrintMember(pX);
int *pD2VT = (int*)*(pRoot + 3);
(*(Fun*)(pD2VT))();
int *pVB2 = (int*)*(pRoot +4); cout << "vbtable's adress:" << *pVB2 << endl;
int *pY = (pRoot + 5); PrintMember(pY);
int *pA = (pRoot + 6); PrintMember(pA);
int *pBVT = (int*)*(pRoot + 7);
(*(Fun*)(pBVT))();
int *pI = (pRoot + 8); PrintMember(pI);
}
void TestVT()
{
B *pB = new GD();
GD *pGD = dynamic_cast<GD*>(pB);
pGD->i = 10;
pGD->x = 20;
pGD->y = 30;
pGD->a = 40;
PrintMemberAndVT(pGD);
delete pGD;
}
6)验证代码结果:
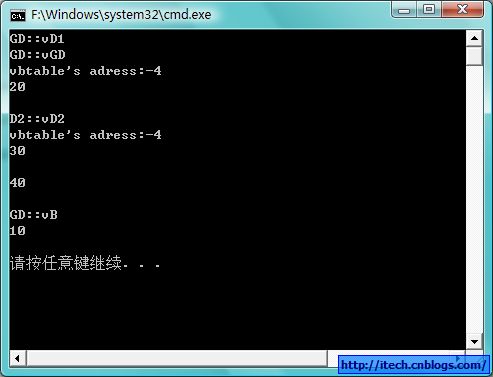
7)总结:
虚继承,使公共的基类在子类中只有一份,我们看到虚继承在多重继承的基础上多了vbtable来存储到公共基类的偏移。
二 虚继承运行时类型转化
1)代码验证:
void TestDynamicCast()
{
B *pB = new GD();
GD *pGD = dynamic_cast<GD*>(pB);
cout << "GD:" << pGD << endl;
D1 *pD1 = dynamic_cast<D1*>(pB);
cout << "D1:" << pD1 << endl;
D2 *pD2 = dynamic_cast<D2*>(pB);
cout << "D2:" << pD2 << endl;
cout << "B:" << pB << endl;
}
2)验证代码结果:
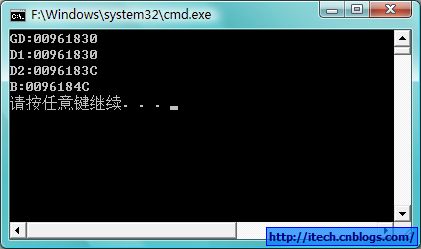
3)总结:
还是从内存布局来看dynamic_cast时地址的变化,第一个基类的地址与子类相同,其他的基类和虚基类需要做偏移。
三 完!
感谢,Thanks!
九 类型转换
一 typeid与dynamic_cast
1)RTTI, Runtime Type Identification (RTTI) or Run-time type information (RTTI),表示在运行时动态决定变量的类型,来调用正确的虚函数。 RTTI在VS2008中默认为关闭,可以通过修改编译选项Enable Run-Time Type Info 为 Yes,来启用RTTI,只有当启动RTTI时,用来RTTI功能的typeid和dynamic_cast才能正常工作。
2)type_info,用来描述类型信息。type_info存储了它所描述的类型的名字。RTTI就是使用type_info来实现的。type_info的定义如下:
class type_info {
public:
virtual ~type_info();
bool operator== (const type_info& rhs) const;
bool operator!= (const type_info& rhs) const;
bool before (const type_info& rhs) const;
const char* name() const;
private:
type_info (const type_info& rhs);
type_info& operator= (const type_info& rhs);
};
问题:RTTI怎么实现那?对象,type_info,虚函数怎么关联那?《深入C++对象模型》中说在虚函数表的开始存储了类型信息,但是实际的VS2008中好像并没有此信息,请高人指点哦!
3)typeid,在运行时获得对象的类型,typeid()返回的是const type_info&,而 type_info包含了对象真实类型的名字。typeid能被用来获取一个引用对象或指针指向的对象的运行时的真实类型。当然如果对象为null或编译 时没有使用/GR的话,typeid的会抛出异常bad_typeid exception或__non_rtti_object。实例代码:
class Base
{
public:
virtual void f(){ }
};
class Derived : public Base
{
public:
void f2() {}
};
void main ()
{
Base *pB = new Derived();
const type_info& t = typeid(*pB);cout <<t.name() << endl;
delete pB;
Derived d;
Base& b = d;
cout << typeid(b).name() << endl;
}
运行结果:
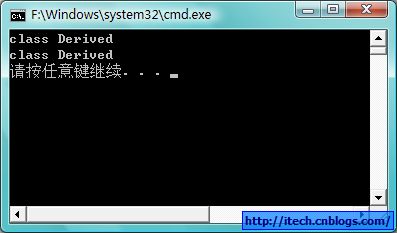
4)dynamic_cast,用来运行时的类型转化,需要/GR来正确运行。
适用:
第一,用于所有的父子和兄弟间指针和引用的转化,有类型安全检查;
第二,对指针类型,如果不成功,返回NULL,对引用类型,如果不成功,则抛出异常;
第三,类型必须要有虚函数,且打开/GR编译选项,否则不能使用dynamic_cast。
实例代码:
class AA
{
public:
virtual void do_sth(){ std::cout<<"AA"n"; }
};
class BB
{
public:
virtual void do_sth(){ std::cout<<"BB"n"; }
};
class CC : public AA, public BB
{
public:
virtual void do_sth(){ std::cout<<"CC"n"; }
};
void DynamicCastTest()
{
AA *pA = new CC;
BB *pB = dynamic_cast<BB*>(pA);
if(pB != NULL)
cout << "cast successful!" << endl;
CC *pC = dynamic_cast<CC*>(pA);
if(pC != NULL)
cout << "cast successful!" << endl;
}
二 其他cast
1)隐式转化,不需要任何操作符,转化被自动执行,当一个值被赋值到它所兼容的类型时。
适用:
第一,内置基本类型的兼容转化;
第二, 子类指针,引用向父类的转化;
实例:
class A
{
public:
virtual ~A(){}
};
class B : public A
{
};
void ImplicitCast()
{
short a = 2000;
int b;
b = a;
double d = 10.05;
int i;
i = d;
int j = 75;
char c;
c = j;
A* pA = new B();
}
2)强制类型转化,即我们常说的C风格的类型转化,基本上可以用于所有的转化,但是没有意义的转化除外,但是父子类,兄弟间的转化没有类型检查可能导致运行是错误。
适用:
第一,基本类型转化;
第二,void*到其他指针的转化;
第三,去除const;
第五,函数指针的转化;
第六,父子类转化,但是多重继承和兄弟转化,可能有运行时错误,没有类型检查;
第七,任何两个类,但是没有实际意义,运行可能出错;
第八,不能用于没有意义的转化,严厉禁止,例如,你不能用static_cast象用C风格的类型转换一样把struct转换成int类型,或者把double类型转换成指针类型;
第九,在C++一般更推荐新加的static_cast,const_cast,dynamic_cast和reinterpret_cast转化方式;
实例:
class CDummy
{
public:
CDummy(float x, float y)
{
i = x;
j = y;
}
private:
float i,j;
};
class CAddition
{
public:
CAddition (int a, int b) { x=a; y=b; }
int result() { return x+y;}
private:
int x,y;
};
int Testing()
{
std::cout << "Testing" << std::endl;
return 10;
}
void ExplicitCast()
{
double r = (double)1 / 3;
int *pi = new int(10);
void *pV;
pV = pi;
int *pj = (int*)pV; // 或 int *pj = int*(pV);
const int* pa = new int(20);
int *pb;
pb = (int*)pa;
*pb = 30;
std::cout << *pa << std::endl;
typedef void (*Fun)();
Fun f = (Fun)Testing;
f();
// 多重继承或将兄弟间的转化可能会出错
// 虽然可以正确的编译,但是运行有问题,所以我们不做没有意义的转化
//CDummy d(10,30);
//CAddition * padd;
//padd = (CAddition*) &d;
//std::cout << padd->result();
// 不做没有意义的转化
//// error
//struct st{int i; double d;};
//st s;
//int x = (int)s; //c2440
//double y = 10.0;
//int *p = (int*)y; // c2440
}
3)static_cast在功能上基本上与C风格的类型转换一样强大,含义也一样。
它也有功能上限制:
第一,不能兄弟间转化,父子间转化没有类型安全检查,有可能会导致运行时错误,父子兄弟的动态转化应该适用dynamic_cast;
第二,不能去除const,适用专用的const_cast;
第三,不能用于两个没有继承关系的类,当然实际上这样的转化也是没有意义的;
第四,当然也不支持没有意义的转化,例如,你不能用static_cast象用C风格的类型转换一样把struct转换成int类型,或者把double类型转换成指针类型;
4)const_cast,用来修改类型的const或volatile属性。
适用:
第一,常量指针被转化成非常量指针,并且仍然指向原来的对象;
第二,常量引用被转换成非常量引用,并且仍然指向原来的对象;
第三,常量对象被转换成非常量对象;
实例:
void ConstCastTest()
{
const int* pa = new int(20);
int *pb;
pb = const_cast<int*>(pa);
*pb = 30;
std::cout << *pa << std::endl;
}
5)reinterpret_cast,此转型操作符的结果取决于编译器,用于修改操作数类型,非类型安全的转换符。
适用:
一般不推荐使用,但是一般用来对函数指针的转化。
实例:
// 不可以移植,不推荐使用
int ReinterpretTest()
{
struct dat { short a; short b;};
long value = 0x00100020;
dat * pd = reinterpret_cast<dat *> (&value);
std::cout << pd->a << std::endl; // 0x0020
std::cout << pd->b << std::endl; // 0x0010
return 0;
}
typedef void (*Fun)();
int Testing()
{
std::cout << "Testing" << std::endl;
return 10;
}
void ReinterpretTest2()
{
//Fun f = (Fun)Testing;
//f();
Fun f = reinterpret_cast<Fun>(Testing);
f();
}
三 总结
在C++一般更推荐新加的static_cast,const_cast,dynamic_cast和reinterpret_cast转化方式;
感谢,Thanks!