本章内容
使用客户端对象(client object)连接到本地或远程ElasticSearch集群。
逐条或批量索引文档。
更新文档内容。
使用各种ElasticSearch支持的查询方式。
处理ElasticSearch返回的错误信息。
通过发送各种管理指令来收集集群状态信息或执行管理任务。
8.3 连接到集群
8.3.1 成为ElasticSearch节点
第一种连接到ElasticSearch节点的方式是把应用程序当成ElasticSearch集群中的一个节点。
Node node=nodeBuilder().clusterName("escluster2").client (true).node();
Client client=node.client();8.3.2 使用传输机连接方式
Settings settings = ImmutableSettings.settingsBuilder().put("cluster.name","escluster2").build();
TransportClient client=new TransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress("127.0.0.1",9300));注意这里的端口号不是9200,而是9300。 9200端口用来让HTTP REST API访问ElasticSearch,而9300端口是传输层监听的默认端口。
我们再回过头来看TransportClient类的可用配置:
- client.transport.sniff(默认值:false):如果设为true , ElasticSearch会读取集群中的 节点信息。因此你不需要在建立TransportClient对象时提供所有节点的网络地址。 ElasticSearch很智能,它会自动检测到活跃节点并把它们加人到列表中。
- client.transport.ignore_cluster_name(默认值:false ):如果设为true,则ElasticSearch会忽视配置中的集群名称并尝试连接到某个可连接集群上,而不管集群名称是否匹配。这一点很危险,你可能会首先连接到你不想要的集群上。
- client.transport.ping_timeout(默认值:5s):该参数指定了ping命令响应的超时时间。 如果客户端和集群间的网络延迟较大或连接不稳定,可能需要调大这个取值。
- client.transport.nodes_sampler_interval默认值:5s):该参数指定了检查节点可用 性的时间间隔。与前一个参数类似,如果网络延迟较大或者网络不稳定,可能需要调大这个值。
8.3.3 选择合适的连接方式
第一种方式让 启动顺序复杂化了,即客户端节点必须加人集群并建立与其他节点的连接,而这需要时间和资源。然而,操作却可以更快地执行,因为所有关于集群、索引、分片的信息都对客户端节点可见。
另一方面,使用TransportClient对象启动速度更快,需要的资源更少,如更少的socket连接。然而,发送查询和数据却需要消耗更多的资源,TransportClient对象对 集群和索引拓扑结构的信息一无所知,所以它无法把数据直接发送到正确的节点,而是先把数据发给某个初始传输节点,然后再由ElasticSearch来完成剩下的转发工作。此外,TransportClient对象还需要你提供一份待连接节点的网络地址列表。
在选择合适的连接方式时请记住,第一种方式并不总是可行的。例如,当要连接的ElasticSearch集群处于另一个局域网中,唯一可选的方式就是使用TransportClient对象。
8.4 API部析
- 获取特定文档记录
GetResponse response=client
.prepareGet(”library","book",”1")
.setFields("title",”_source")
.execute().actionGet();在完成准备工作之后,我们用构造器对象创建一个请求 (利用request()方法)以备随后使用,或者直接通过execute()调用送出查询请求,这里我们选择后者。
ELasticSearch的API是天生异步的。这意味着execute()调用 不会等待ElasticSearch的响应结果,而是直接把控制权交回给调用它的代码段,而查询请求在后台执行。本例中我们使用actionGet()方法,这个方法会等待查询执行完毕并返回数据。这样做比较简单,但在更复杂的系统中这显然不够。接下来是一个使用异步API的例子。首先引人相关声明:
ListenableActionFuture future=client
.prepareGet("library","book","1")
.setFields("title",”_source")
.execute();
future.addListener( new ActionListener(){
@Override
public void onResponse(GetResponse response){
System.out.println("Document:"+response.getIndex()
+”/“
+response .getType()
+”/"
+response.getId());
}
@Override
public void onFailure(Throwable e){
throw new RuntimeException(e);
}
}); 8.5 CRUD操作
8.5.1 读取文档
GetResponse response=client
.prepareGet("library","book","1")
.setFields("title","_source")
.execute().actionGet();- GetRequestBuilder的方法
setFields(String):
setIndex(String) , setType(String) , setId(String):
setRouting(String):
setParent(String):
setPreference(String): 【_local, _primary】
setRefresh(Boolean): 【false】
setRealtime(Boolean):【true】- 响应GetResponse的方法
isExists():
getindex():
getType():
getId():
getVersion():
isSourceEmpty():
getSourceXXX():【getSourceAsString(),getSourceAsMap(),getSourceAsBytes()】
getField(String):8.5.2 索引文档
IndexResponae response=client.prepareIndex("library","book","2")
.setSource("{\"title\":\"Mastering ElasticSearch\"}")
.execute().actionGet();- 构造器对象提供了如下方法:
setSource():
setlndex(String), setType(String), setId(String):
setRouting(String) , setParent(String):
setOpType():【index,create】
setRefresh(Boolean):【false】
setReplicationType():【sync,async,default】
setConsistencyLevel():【DEFAULT,ONE,QUORUM,ALL】多少副本活跃才进行该操作
setVersion(long):多亏了这个方法。程序可以确保在读取和更新文档期间没有别人更改这个文档。
setVersionType(VersionType):
setPercolate(String):
setTimestamp(String):
setTTL(long):超过这个时长后文档会被自动删除
getlndex():返回请求的索引名称
getType():返回文档类型名称
getId():返回被索引文档的ID
getVersion():返回被索引文档的版本号
getMatches():返回匹配被索引文档的过滤器查询列表,如果没有匹配的查询,则返回null8.5.3 更新文档
Mapparams=Maps.newHashMap();
params.put("ntitle","ElasticSearch Server Book");
UpdateResponse response = client.prepareUpdate("library","book","2")
.setScript("ctx._source.title=ntitle")
.setScriptParams(params)
.execute().actionGet(); - UpdateRequestBuilder 方法
setIndex(String) , setType(String) , setId(String):
setRouting(String), setParent(String):
setScript(String):
setScriptLang(String):
setScriptParams(Map):
addScriptParam(String, Object):
setFields(String...):
setRetryOnConflict(int):默认值为0。在ElasticSearch中,更新一个文档意味着先检索出文档的旧版本,修改它的结构,从索引中删除旧版本然后重新索引新版本。这意味着,在检索出旧版本和写人新版本之间,目标文档可能被其他程序修改。ElasticSearch通过比较文档版本号来检测修改,如果发现修改则返回错误。除了直接返回错误,还可以选择重试本操作。而这个重试次数就可以由本方法指定。
setRefresh(Boolean):【false】
setRepliactionType():【sync, async, default】。本方法用于控制在更新过程中的复制类型。默认情况下,只有所有副本执行更新后才认为更新操作是成功的,对应这里的取值为sync或等价枚举值。另一种选择是不等待副本上的操作完成就直接返回,对应取值为async或等价枚举值。还有一种选择是让ElasticSearch根据节点配置来决定如何操作,对应取值为default或等价枚举值。
setConsistencyLevel():【DEFAULT,ONE,QUORUM,ALL】本方法设定有多少个活跃副本时才能够执行更新操作。
setPercolate(String):这个方法将导致索引文档要经过percolator的检查,其参数是 一个用来限制percolator查询的查询串。取值为`*`表示所有查询都要检查。
setDoc():这类方法用来设置文档片段,而这些文档片段将合并到索引中相同ID的 文档上。如果通过setScript()方法设置了script,则文档将被忽略。ElasticSearch提供了本方法的多种版本,分别需要输入字符串、字节数组、XContentBuilder, Map 等多种类型表示的文档。
setSource():
setDocsAsUpsert(Boolean):默认值为false。设置为true后,如果指定文档在索引中不存在,则setDoc()方法使用的文档将作为新文档加人到索引中。 - 更新请求返回的响应为一个UpdateResponse对象方法:
getIndex():
getType():
getld():
getVersion():
getMatches():
getGetResult():8.5.4 删除文档
DeleteResponse response=client.prepareDelete("library","book","2")
.execute().actionGet();- DeleteRequestBuilder 方法
setIndex(String), setType(String), setId(String):
setRouting(String), setParent(String):
setRefresh(Boolean):
setVersion(long):本方法指定索引时被删除文档的版本号。如果指定ID的文档不 存在,或者版本号不匹配,则删除操作会失败。这个方法确保了程序中没有别人更改这个文档。
setVersionType(VersionType):本方法告知ElasticSearch使用哪个版本类型。
setRepliactionType():【sync, async和default】
setConsistencyLevel():本方法设定有多少个活跃副本时才能够执行更新操作。【DEFAULT,ONE,QUORUM,ALL】- 删除操作的响应DeleteResponse类提供了如下方法:
getIndex():返回请求的索引名称。
getType():返回文档类别名称。
getId():返回被索引文档的ID。
getVersion():返回被索引文档的版本号。
isNotFound():如果请求未找到待删除文档,则返回true8.6 ElasticSearch查询
8.6.1 准备查询请求
SearchResponse response=client.prepareSearch("library"
.addFields('title","_source")
.execute().actionGet();
for(SearchHit hit:response.getHits().getHits()){
System.out.println(hit.getId());
if (hit.getFields().containsKey("title"}){
System.out.println("field.title: "
+hit.getFields().get("title").getValue())
}
System.out.println("source.title: "
+hit.getSource().get("title"));
}8.6.2 构造查询
QueryBuilder queryBuilder=QueryBuilders
.disMaxQuery()
.add(QueryBuilders.termQuery("title","Elastic"))
.add(QueryBuilders.prefixQuery("title","el"));
System.out.println(queryBuilder.toString());
SearchResponse response=client.prepareSearch("library")
.setQuery(queryBuilder)
.execute().actionGet();匹配查询
queryBuilder=QueryBuilders
.matchQuery("message","a quick brown fox")
.operator(Operator.AND)
.zeroTermsQuery(ZeroTermsQuery.ALL);使用地理位置查询
queryBuilder = QueryBuilders.geoShapeQuery("location",
ShapeBuilder.newRectangle()
.topLeft(13, 53)
.bottomRight(14, 52)
.build());8.6.3 分页
SearchResponse response=client.prepareSearch("library")
.setQuery(QueryBuilders.matchAllQuery())
.setFrom(10)
.setSize(20)
.execute().actionGet();8.6.4 排序
SearchResponse response=client.prepareSearch("library")
.setQuery(QueryBuilders.matchAllQuery())
.addSort(SortBuilders.fieldSort("title"))
.addsort("_score",SortOrder .DESC)
.execute().actionGet();除了上述排序方法外,ElasticSearcb还提供了一种基于脚本的排序方法:scriptSort(String, String),以及一种基于空间距离排序的方法:geoDistanceSort(String).
8.6.5 过滤
FilterBuilder filterBuilder=FilterBuilders
.andFilter(
FilterBuilders .existsFilter("title").filterName("exist”),
FilterBuilders.termFilter("title","elastic")
);
SearchResponse response=client.prepareSearch("library")
.setFilter(filterBuilder)
.execute().actionGet();8.6.6 切面计算
FacetSBuilder facetBuilder=FacetBuilders
.filterFacet("test")
.filter(FilterBuilders .termFilter("title","elastic"));
SearchResponse response=client.prepareSearch("library")
.addFacet(facetBuilder)
.execute()actionGet();8.6.7 高亮
SearchResponse response=client.preparesearch("wikipedia")
.addHighlightedField("title")
.setQuery(QueryBuilders.termQuery("title","actress"))
.setHighlighterPreTags("<1>", "<2>")
.setHighlighterPostTags(""," ")
.execute().actionGet();- 高亮处理
for(SearchHit hit:response.getHits().getHits()){
HighlightField hField = hit.getHighlightFields()get("title");
for (Text t:hField.fragments()){
System.out.println(t.string());
}
}8.6.8 查询建议
SearchResponse response=client.prepareSearch("wikipedia")
.setQuery(QueryBuilders.matchAllQuery())
.addSuggestion(new TermSuggestionBuilder("first_suggestion")
.text("graphics designer")
.field("_all")
)
.execute().actionGet()- 结果处理
for(Entry entry: response.getSuggest()
.getSuggestion("first_suggestion").getEntries()){
System.out.println("Check for: "
+entry.getText()
+". Options:");
for(Option option: entry.getOptions()){
System.out.println("\t"+option.getText());
}8.6.9 计数
有时 候,我们不在乎具体会返回哪些文档,而只想知道匹配的结果数量。在这种情况下,我们需要使用计数请求,因为它的性能更好:不需要做排序,也不需要从索引中取出文档。
CountResponse response=client.prepareCount("library")
.setQuery(QueryBuilders.termQuery("title","elastic"))
.execute().actionGet();8.6.10 滚动
要使用ElasticSearch Java API的滚动功能获取大量文档集合:
SearchResponse responseSearch=client.prepareSearch("library" )
.setScroll("1m")
.setSearchType(SearchType.SCAN)
.execute().actionGet();
String scrolled=responseSearch.getScrollId();
SearchResponse response = client.prepareSearchScroll(scrollld)
.execute().actionGet(),其中有两个请求:第一个请求指定了查询条件以及滚动属性,如滚动的有效时长(使用 setScroll()方法);第二个请求指定了查询类型,如这里我们切换到扫描模式(scan mode)。扫描模式下会忽略排序而仅执行取出文档操作。
8.7 批量执行多个操作
8.7.1 批量操作
BulkResponse response=client.prepareBulk()
.add(client.prepareIndex("library", "book","5")
.setSource("{\"title\":\"Solr Cookbook\"}"
.request()
.add(client.prepareDelete("library", "book", "2").request())
.execute().actionGet();该请求向Iibrary索引的boo(类型中添加了一个文档(ID为5),又从这个索引中删除了一 个文档(ID为2)。得到响应后,通过getItems()方法可得到一个由org.elasticsearch.action.bulk.BulkItemResponse对象组成的数组。
8.7.2 根据查询删除文档
DeleteByQueryResponse response=client.
prepareDeleteByQuery("library")
.setQuery(QueryBuilders.termQuery("title","ElasticSearch"))
.execute().actionGet();8.7.3 Multi GET
MultiGetResponse response = client.prepareMultiGet()
.add("library", "book", "1","2")
.execute().actionGet();这个请求的响应对象包含一个getResponses()方法,而该方法返回了一个由org. elasticsearch.action.get.MultiGetItemResponse对象构成的数组。
8.7.4 Multi Search
MultiSearchResponse response=client.prepareMultiSearch()
.add(client.prepareSearch("library","book").request())
.add(client.prepareSearch("news").
.setFilter(FilterBuilders.termFilter("tags", "important")))
.execute().actionGet();本操作包含一个getResponses()方法。该方法返回了一个由 elasticsearch.action.search.MultiSearchResponse.Item对象组成的数组。
8.8 Percolator
percolator是查询的逆过程。我们可以根据某个文档来找出与之匹配的所有查询。假 定有一个prc ltr的索引,我们可以使用如下代码向_percolator索引的prcltr类型索引一个查询:
client.prepareIndex(”_percolator","prcltr","query:1")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("query",
QueryBuilders .termQuery("test","abc"))
.endObject())
.execute().actionGet();本例中我们定义了一个ID为“query: 1”的查询,用来检查test字段中是否包含abc这个 值。既然percolator已经准备好了,那么可以使用如下代码片段来向它发送一个文档:
PercolateResponse response =client.preparePercolate("prcltr","type")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.startObject("doc")
.field("test").value("abc")
.endObject()
.endObject())
.execute().actionGet();我们发送的这个文档应该是与percolator中存储的那个查询匹配,这一点可以通过 getMatches()方法来检验。具体可以使用如下代码:
for (String match:response.getMatches()){
System.out.println("Match:"+match);
}8.9 explain API
最后一个关于查询ElasticSearch的API是explain API。explain API可以帮助检查关于 相关度的问题,并指出文档匹配与否的依据。请看下面的代码:
ExplainResponse response=client
.prepareExplain(“library","book","1")
.setQuery(QueryBuilders.termQuery("title","elastic"))
.execute().actionGet();8.11 管理API
ElasticSearch把管理操作划分为 两类:集群管理和索引管理。我们先看第一类。
8.11.1 集群管理API
ClusterAdminClient cluster=client.admin().cluster()集群和索引健康状态API
ClusterHealthResponse response=client.admin().cluster()
.prepareHealth("library")
.execute().actionGet();在响应中,可以读取到集群状态、已分配分片数、总分片数、特定 索引的副本数等信息。
集群状态API
集群状态API可以让我们获取集群相关信息,如路由、分片分配情况以及映射等。
ClusterStateResponse response=client.admin().cluster()
.prepareState()
.execute().actionGet();设置更新API
设置更新API可以设置集群范围的配置参数。
Map map=Maps.newHashMap()
map.put("indices.ttl.interval","10m");
ClusterUpdateSettingsResponse response=client.admin().cluster()
.prepareUpdateSettings()
.setTransientSettings(map)
.execute().actionGet(); 重新路由API
重新路由API可以在节点间移动分片,以及取消或强制进行分片分配行为。
ClusterRerouteResponse response=client .admin().cluster()
.prepareReroute()
.setDryRun(true)
.add(
new MoveAllocationCommand(new ShardId("library",3),
"G3czOt4HQbKZT1RhpPCULw",
PvHtEMuRSJ6rLJ27AW3U6w"),
new CancelAllocationCommand(new ShardId("‘library", 2),
"G3czOt4HQbKZT1RhpPCULw",
true))
.execute().actionGet();节点信息API
节点信息(nodes information) API提供了一个或多个特定节点的信息。该API输出的信息涵盖Java虚拟机、
操作系统以及网络(如IP地址或局域网地址以及插件信息等)。
NodesInfoResponse response = client.admin().cluster()
.prepareNodesInfo()
.setNetwork(true)
.setPlugin(true)
.execute().actionGet();节点统计API
节点统计(node statistics ) API和节点信息API很相似,只是它输出的是有关 ElasticSearch使用情况的信息,如索引统计、文件系统、HTTP模块、Java虚拟机等。
NodesStatsResponse response=client.admin().cluster()
.prepareNodesStats()
.all()
.execute().actionGet();节点热点线程API
节点热点线程API用于在ElasticSearch出故障或CPU使用率超过正常值时检查节点状 态。
NodesHotThreadsResponse response=client.admin().cluster()
.prepareNodesHotThreads()
.execute().actionGet();节点关闭API
节点关闭(node shutdown ) APl比较简单,它允许我们关闭指定节点(或所有节点)。 如果需要,还可以设置关闭延迟时间。例如,下面代码将立即关闭整个集群:
NodeaShutdownResponse response=client.admin().cluster()
.prepareNodesShutdown()
.execute().actionGet();查询分片API
查询分片(searchshard ) API也比较简单,它允许我们检查哪些节点将用于处理查询。 它还可以设置路由参数,因此在使用自定义路由时特别方便。
ClusterSearchShardsResponse response=client.admin().cluster()
.prepareSearchShards()
.setIndices("library")
.setRouting("12")
.execute().actionGet();8.11.2 索引管理API
IndicesAdminClient cluster = client.admin().indices();索引存在API
类型存在API
索引统计API
索引统计(indicesstats ) API可以提供关于索引、文档、存储以及操作的信息,如获取、 查询、索引、预热器、合并过程、清空缓冲区、刷新等。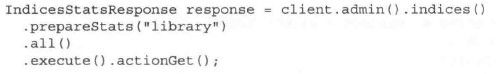
索引状态
索引段信息API
创建索引API
删除索引API
关闭索引API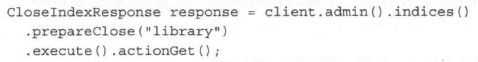
打开索引API
刷新API
清空缓冲区API
索引优化API
设置映射API
删除映射API
别名API
获取别名API
别名存在API
清空缓存API
更新设置API
分析API
设置模板API
删除模板API
查询验证API
设置预热器API
删除预热器API