1.思路构想
上一节主要通过webdriver写了一个demo来写了拔取小说的功能,虽然功能实现了,但是每次拔取不同的小说都要改很多数据,更改起来有很多不方便的地方,所以我们来吧数据层单独放在一起,并加入了日志等功能,下面首先来看一下我的文件分层结构吧!!!
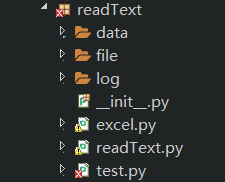
首先,我里面有文件夹和具体的实现文件,这只是我的初级构想,实际上还可以进行继续进一步的优化,比如把基础的功能单独放在一个文件夹里
介绍一下我的结构吧
data:放置excel表格,里面记录着驱动的数据,比如baseUrl、目录的xpath、日志路径、文件路径等等
file:放置生成的txt小说
log:放置日志文件,里面有拔取时的日志,方便后期进行查看
excel:读取excel文件的代码
readText:拔取小说的逻辑代码
test:运行程序的代码
2.代码实现
首先我们的exccel读取时,引用了第三方的库:xlrd
我们可以通过cmd进行安装:pip install xlrd
读取excel文件的代码excel.py
# coding=utf-8
import xlwt
import xdrlib ,sys
import xlrd
def open_excel(file= 'file.xls'):
try:
data = xlrd.open_workbook(file)
return data
except Exception:
print (Exception)
def excel_table_byindex(file= 'file.xls',colnameindex=0,sheet_index=0):
"""根据索引获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,sheet_index:表的索引"""
data = open_excel(file)
table = data.sheets()[sheet_index]
nrows = table.nrows #行数
ncols = table.ncols #列数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(len(colnames)):
app[colnames[i]] = row[i]
list.append(app)
return list
def excel_table_byname(file= '../test_data/abc.xlsx',colnameindex=0,sheet_name='Sheet1'):
"""根据名称获取Excel表格中的数据 参数:file:Excel文件路径 colnameindex:表头列名所在行的所以 ,sheet_index:Sheet1名称"""
data = xlrd.open_workbook(file)
table = data.sheet_by_name(sheet_name)
nrows = table.nrows #行数
ncols =table.ncols #列数
colnames = table.row_values(colnameindex) #某一行数据
list =[]
for rownum in range(1,nrows):
row = table.row_values(rownum)
if row:
app = {}
for i in range(ncols):
app[colnames[i]] = row[i]
list.append(app)
return list
def excel_get_valueFromTitle(list,colName,colValue):
""" list : 列表 colName:列名 colValue列名值
返回包含特定数据的一行(字典)
"""
for row in list:
if row[colName]== colValue:
return row
拔取小说内容的逻辑代码readText.py
from selenium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import logging
import sys
class readTexts():
def logger(self,logName):
""" 获取logger"""
self.logger =logging.getLogger()
logger = self.logger
formatter = logging.Formatter('%(asctime)s %(levelname)-8s: %(message)s')
file_handler = logging.FileHandler(logName)
file_handler.setFormatter(formatter)
console_handler = logging.StreamHandler(sys.stdout)
console_handler.formatter = formatter
logger.addHandler(file_handler)
logger.addHandler(console_handler)
logger.setLevel(logging.INFO)
return logger
def driver(self):
"""创建driver"""
self.driver = webdriver.Chrome()
return self.driver
def file(self,fileName):
self.f = open(fileName,"w")
return self.f
def count(self,b):
b= b+1
return b
def setA(self,a):
self.a = a
return a
def setB(self,b):
self.b = b
return b
def setC(self,c):
self.c = c
return c
def setD(self,d):
self.d = d
return d
# def count(self,b):
# count=self.a+str(b)+self.c
# return count
def doText(self,log,file,driver,baseUrl,locatePath,titlePath,textPath):
logger = log
driver = driver
f= file
driver.get(baseUrl)
while self.bimport excel
import readText as rt
class tests():
def mian(self):
#通过excel获取数据
excelList =excel.excel_table_byname("data/abc.xlsx", 0, "a")
rows =excel.excel_get_valueFromTitle(excelList, "name", "黑铁之堡")
#将数据通过字典传入到数据字段
log = rt.readTexts.logger(self,rows["logname"])
file = rt.readTexts.file(self,rows["filename"])
driver = rt.readTexts.driver(self)
rt.readTexts.setA(self,rows["a"])
rt.readTexts.setB(self,rows["b"])
rt.readTexts.setC(self,rows["c"])
rt.readTexts.setD(self,rows["d"])
baseUrl = rows["baseurl"]
locatePath=rows["locatepath"]
titlePath=rows["titlepath"]
textPath=rows["textpath"]
#记录日志
log.info("loading字典数据:")
log.info(rows)
rt.readTexts.doText(self,log,file,driver,baseUrl,locatePath,titlePath,textPath)
tests =tests()
tests.mian()
| filename | logname | a | b | c | d | baseurl | locatepath | titlepath | textpath | name |
| file/校园狂神1.txt | log/校园狂神1.log | .//*[@id='chapterslist']/dl/dd[ | 0 | ]/a | 1907 | http://www.biquge5.com/10_10000/ | .//*[@id='chapterslist']/dl/dt[2] | .//*[@id='webbegin']/div[4]/div/div[2]/h1 | .//*[@id='content'] | 校园狂神 |
| file/黑铁之堡.txt | log/黑铁之堡.log | .//*[@id='list']/dl/dd[ | 9 | ]/a | 2059 | http://www.biquge.com/0_249 | .//*[@id='footer']/div[2]/p[1] | .//*[@id='wrapper']/div[5]/div[2]/div[2]/h1 | .//*[@id='content'] | 黑铁之堡 |
最后我要说的是,我的代码还不是很完善,不过基本实现了数据驱动和日志记录的功能,需要改进的是循环的读取并保存小说和添加动态数据的逻辑代码,每次写完一些东西总是要总结的,这是推动每一次更改代码的动力。不过我在下面也试过加入新的功能,比如ddt数据驱动、unittest框架等等,不过因为一直没有调试好就不放上来了,下一次准备好好学习一下python的爬虫,毕竟webdriver的功能还是有些局限的,希望能用其他的库来实现更多有意思的事情。