Hadoop HDFS JavaAPI操作
创建maven工程并导入jar包
由于cdh版本的所有的软件涉及版权的问题,所以并没有将所有的jar包托管到maven仓库当中去,而是托管在了CDH自己的服务器上面,所以我们默认去maven的仓库下载不到,需要自己手动的添加repository去CDH仓库进行下载,以下两个地址是官方文档说明,请仔细查阅
https://www.cloudera.com/documentation/enterprise/release-notes/topics/cdh_vd_cdh5_maven_repo.html
https://www.cloudera.com/documentation/enterprise/release-notes/topics/cdh_vd_cdh5_maven_repo_514x.html
首先创建一个maven项目,在pom文件中加入以下内容
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-client</artifactId>
<version>2.6.0-mr1-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-common</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-hdfs</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<dependency>
<groupId>org.apache.Hadoop</groupId>
<artifactId>Hadoop-mapreduce-client-core</artifactId>
<version>2.6.0-cdh5.14.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
<!-- <plugin>
<artifactId>maven-assembly-plugin </artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>cn.itcast.Hadoop.db.DBToHdfs2</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>-->
</plugins>
</build>
接下来的步骤需要启动集群,不然会报错:Connection refused
使用url的方式访问数据(了解)
@Test
public void demo1()throws Exception{
//第一步:注册hdfs 的url,让java代码能够识别hdfs的url形式
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
InputStream inputStream = null;
FileOutputStream outputStream =null;
//定义文件访问的url地址
String url = "hdfs://192.168.100.201:8020/test/input/install.log";
//打开文件输入流
try {
inputStream = new URL(url).openStream();
outputStream = new FileOutputStream(new File("c:\\hello.txt"));
IOUtils.copy(inputStream, outputStream);
} catch (IOException e) {
e.printStackTrace();
}finally {
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
}
}
如果执行出现以下错误,可以看下面解决,也可以不用理会,不会影响程序的执行。记得配置完成环境变量之后重启开发工具
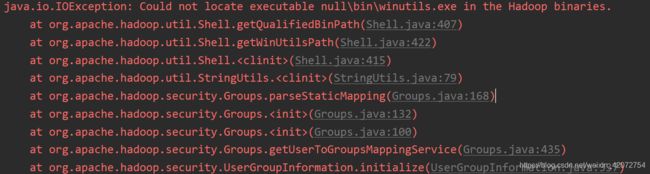
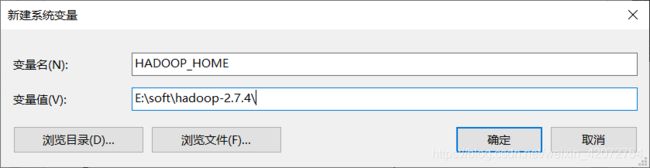
首先下载一个hadoop2.7.4的压缩包
然后解压到某个文件夹E:\soft\hadoop-2.7.4。
然后配置环境变量:
再给path环境变量添加如下内容
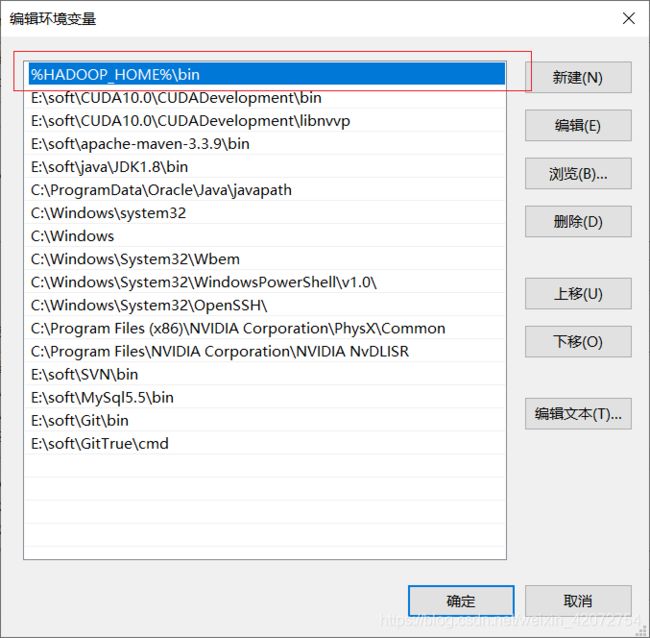
重启电脑即可生效。
使用文件系统方式访问数据
在 java 中操作 HDFS,主要涉及以下 Class:
Configuration:该类的对象封转了客户端或者服务器的配置;
FileSystem:该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过 FileSystem 的静态方法 get 获得该对象。
FileSystem fs = FileSystem.get(conf)
get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类型的文件系统。
如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath下也没有给定相应的配置,conf中的默认值就来自于Hadoop的jar包中的core-default.xml , 默 认 值 为 : file:/// , 则 获 取 的 将 不 是 一 个DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象
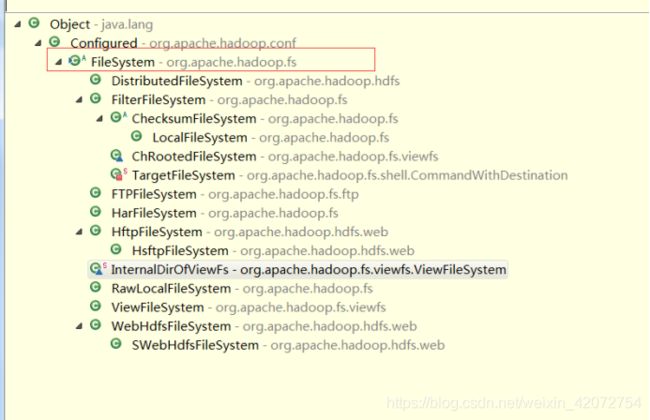
获取FileSystem的几种方式
第一种方式获取FileSystem
@Test
public void getFileSystem() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), configuration);
System.out.println(fileSystem.toString());
}
第二种获取FileSystem类的方式
@Test
public void getFileSystem2() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.52.100:8020");
FileSystem fileSystem = FileSystem.get(new URI("/"), configuration);
System.out.println(fileSystem.toString());
}
第三种获取FileSystem类的方式
@Test
public void getFileSystem3() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://192.168.52.100:8020"), configuration);
System.out.println(fileSystem.toString());
}
第四种获取FileSystem类的方式
@Test
public void getFileSystem4() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://192.168.52.100:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
递归遍历文件系统当中的所有文件
通过递归遍历hdfs文件系统
@Test
public void listFile() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
if(fileStatus.isDirectory()){
Path path = fileStatus.getPath();
listAllFiles(fileSystem,path);
}else{
System.out.println("文件路径为"+fileStatus.getPath().toString());
}
}
}
public void listAllFiles(FileSystem fileSystem,Path path) throws Exception{
FileStatus[] fileStatuses = fileSystem.listStatus(path);
for (FileStatus fileStatus : fileStatuses) {
if(fileStatus.isDirectory()){
listAllFiles(fileSystem,fileStatus.getPath());
}else{
Path path1 = fileStatus.getPath();
System.out.println("文件路径为"+path1);
}
}
}
官方提供的API直接遍历
/**
* 递归遍历官方提供的API版本
* @throws Exception
*/
@Test
public void listMyFiles()throws Exception{
//获取fileSystem类
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());
//获取RemoteIterator 得到所有的文件或者文件夹,第一个参数指定遍历的路径,第二个参数表示是否要递归遍历
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true);
while (locatedFileStatusRemoteIterator.hasNext()){
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
System.out.println(next.getPath().toString());
}
fileSystem.close();
}
下载文件到本地
程序执行的main方法
/**
* 拷贝文件的到本地
* @throws Exception
*/
@Test
public void getFileToLocal()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());
FSDataInputStream open = fileSystem.open(new Path("/test/input/install.log"));
//要下载的文件路径
FileOutputStream fileOutputStream = new FileOutputStream(new File("c:\\install.log"));
//下载到哪个地方的路径
IOUtils.copy(open,fileOutputStream );//执行下载操作
IOUtils.closeQuietly(open);
IOUtils.closeQuietly(fileOutputStream);
fileSystem.close();
}
hdfs上创建文件夹
@Test
public void mkdirs() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());
boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test"));
fileSystem.close();
}
hdfs文件上传
@Test
public void putData() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.52.100:8020"), new Configuration());
fileSystem.copyFromLocalFile(new Path("file:///c:\\install.log"),new Path("/hello/mydir/test"));
//前边是本地文件路径, 后边是hdfs路径
fileSystem.close();
}
另外还有几个需要理解的,放到一个demo类中
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.net.URI;
import java.net.URISyntaxException;
public class demo {
//该类的对象封转了客户端或者服务器的配置
static Configuration conf=new Configuration();
public static void listStatus() throws Exception {
//该类的对象是一个文件系统对象
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
//获取某一目录下的所有文件
FileStatus stats[]=hdfs.listStatus(new Path("/"));
//遍历输出
for(int i = 0; i < stats.length; ++i)
System.out.println(stats[i].getPath().toString());
hdfs.close();
}
public static void rename() throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
Path frpaht=new Path("/aaa");
Path topath=new Path("/aaaaaaa");
boolean isRename=hdfs.rename(frpaht, topath);
String result=isRename?"修改成功!":"修改失败!";
System.out.println(result);
}
public static void GetTime() throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
FileStatus fileStatus=hdfs.getFileStatus(new Path("/yarn-daemons.txt"));
long modiTime=fileStatus.getModificationTime();
System.out.println(modiTime);
}
public static void deletefile() throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
boolean isDeleted=hdfs.delete(new Path("/user/new"),true);
System.out.println("Delete?"+isDeleted);
}
public static void mkdir () throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
boolean bool2=hdfs.mkdirs(new Path("/user/new"));
if (bool2)
{
System.out.println("创建成功!!");
}
else
{
System.out.println("创建失败!!");
}
}
public static void AddFile() throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
byte[] buff="hello hadoop world!\r\n hadoop ".getBytes();
FSDataOutputStream outputStream=hdfs.create(new Path("/tmp/file.txt"));
outputStream.write(buff,0,buff.length);
outputStream.close();
}
public static void put() throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
Path src =new Path("C:/123.py");
Path dst =new Path("/");
hdfs.copyFromLocalFile(src, dst);
}
public static void check() throws Exception {
FileSystem hdfs=FileSystem.get(new URI("hdfs://192.168.100.201:8020"),conf);
Path findf=new Path("/abc");
boolean isExists=hdfs.exists(findf);
System.out.println("Exist?"+isExists);
}
public static void main(String[] args) throws Exception {
//获取指定路径所有文件
listStatus();
//重命名
rename();
//获取文件日期
GetTime();
//创建文件夹
mkdir ();
//删除文件
deletefile();
//创建数据
AddFile();
//上传数据
put();
//检查目录是否存在
check();
}
}