如何结合Node和Puppeteer做网络爬虫
相信大家都听说过爬虫,我们也听说过Python是可以很方便地爬取网络上的图片,但是奈何本人不会Python,就只有通过Node来实践一下了。

01 前言
何谓爬虫
其实爬虫用很官方的语言来描述就是“自动化浏览网络程序”,我们不用手动去点击、去下载一些文章或者图片。大家或许用过抢票软件,其实就是不断地通过软件访问铁路官方的接口,达到抢票的效果。但是,这类抢票软件是违法的。
那么怎么判断爬虫是不是违法呢?关于爬虫是否非法其实没有很明确的说法,一直都是中立的态度。爬虫是一种技术,技术本身没有违法的。但是你使用这种技术去爬取不正当的信息、有版权的图片等用于商用,那么你就是违法了。其实我们只要在使用爬虫技术的时候不要去爬个人隐私信息,不要爬取有版权的图片,最重要的是信息不要用于商业化的行为,爬虫不得干扰网站的正常运行等。
说了这么多其实就是要大家谨慎使用这一项技术。
怎么爬
我查了一下资料,使用Node做爬虫的话其实有很多的途径,很多人比较喜欢的就是使用cheerio以及request来爬取。但是我也发现了一个比较好用的工具就是puppeteer,这一项技术是谷歌官方提供的一款工具。它其实就是把人来做的事情变成了调用接口来实现。看了一下官方的文档,主要可以实现以下的功能:puppeteer官方文档
- 生成页面的屏幕截图和PDF。
- 爬取SPA(单页应用程序)并生成预渲染的内容(即“ SSR”(服务器端渲染))。
- 自动执行表单提交,UI测试,键盘输入等。
- 创建最新的自动化测试环境。使用最新的JavaScript和浏览器功能,直接在最新版本的Chrome中运行测试。
- 捕获站点的时间线跟踪以帮助诊断性能问题。
- 测试Chrome扩展程序。
同时也看了一些同学的评价,觉得这个东西是非常的amazing啊!虽然我还没有深入去了解全部的API,但是也算是懂得大概的流程。大家如果官方的文档看不懂的话可以去B站看一下基本的介绍,puppeteer系列教程。
02 安装过程
puppeteer安装
关于这个安装的事情真的是非常的头疼,搞了许久才安装成功。原因就是高高的围墙使得城内的人出不去。所以我们只有换另外一种方法来安装了。
我们直接npm安装的过程默认是要下载浏览器的,我就是在这里一直卡住然后报错,试了好几次都是这样。经过网友们的介绍我们是可以不用在安装puppeteer的时候下载浏览器的,我们可以事后才去下载。
env PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i puppeteer
我们这样就可以成功安装puppeteer了,接下来我们就要去手动安装浏览器了。那么我们要去哪里下载呢?我要手动下载
这里面非常多的版本号,看了网上的教程我们要选择合适的版本号(不知道随便下载一个可不可以),我们回到项目的根目录下面node_modules/puppeteer/package.json这个目录,查看一下我们的浏览器版本是多少。
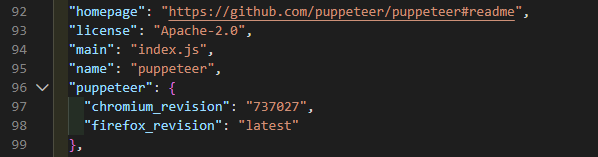

我这里就是现实737027的版本号,我们就去手动下载这个浏览器就可以了。大家可以根据自己的版本进行下载。
浏览器引用
我们光安装了之后还不行,还要进行浏览器的引入。这个也是非常的头疼,看了好多的教程都不可以。可能是他们的系统不一样,在这里折腾很久都想放弃了。还好有这篇文章解决了我的问题,我知道是路径有误但我不知道怎么写。
浏览器下载之后我们就解压放到根目录下面,与package.json同级。然后我们在根目录下新建一个index.js文件。
const puppeteer = require("puppeteer");
const fs = require("fs");
const request = require("request");
const path = require("path");
//配置路径,关键!
const pathToExtension = require("path").join(
__dirname,
"./chrome-win/chrome.exe"
);
最后我的项目目录:
03 选择网站
我们都设置好了之后我们就开始选取一个网站进行测试了,我这里就选择了这个来爬取图片。
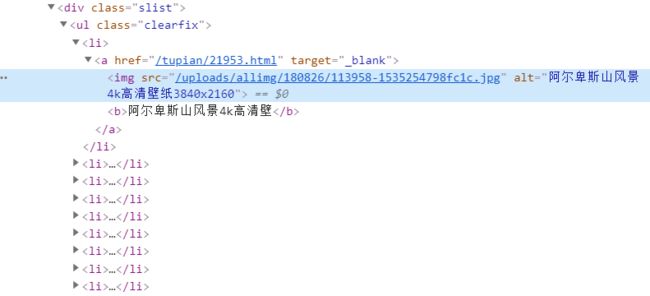
其实我们知道万物皆可爬,只要分析对了就好。前端最熟悉不过的F12走一波就好。看了一下大概结构是长这样的,准备好了之后开始撸码。
反手一写(CV)就出来这样的代码。
const puppeteer = require("puppeteer");
const fs = require("fs");
const request = require("request");
const path = require("path");
let i = 2;//页数
async function netbian(i) {
const pathToExtension = require("path").join(
__dirname,
"./chrome-win/chrome.exe"
);
const browser = await puppeteer.launch({
headless: false,
executablePath: pathToExtension,
});
const page = await browser.newPage();
await page.goto(`http://pic.netbian.com/4kfengjing/index_${i}.html`);//为了方便从第二页开始
let images = await page.$$eval("ul>li>a>img", (el) =>//图片节点,API可查看官方介绍
el.map((x) => "http://pic.netbian.com" + x.getAttribute("src"))//获取图片的src地址
);
mkdirSync(`./images`); // 存放目录
for (m of images) {
await downloadImg(m, "./images/" + new Date().getTime() + ".jpg");
}
netbian(++i);//下一页,具体结束页可以自己限制
// 关闭
await browser.close();
}
netbian(i);//这里执行
// 同步创建目录
function mkdirSync(dirname) {
if (fs.existsSync(dirname)) {
return true;
} else {
if (mkdirSync(path.dirname(dirname))) {
fs.mkdirSync(dirname);
return true;
}
}
return false;
}
// 下载文件 保存图片
async function downloadImg(src, path) {
return new Promise(async function (resolve, reject) {
let writeStream = fs.createWriteStream(path);
let readStream = await request(src);
await readStream.pipe(writeStream);
readStream.on("end", function () {
console.log("文件下载成功");
});
readStream.on("error", function () {
console.log("错误信息:" + err);
});
writeStream.on("finish", function () {
console.log("文件写入成功");
writeStream.end();
resolve();
});
});
}
03 开始爬取
我们直接在根目录运行node index.js就可以了。执行之后我们发现多了一个images目录,里面就是我们的图片了。
04 小结
其实关于puppeteer的使用还有很多,这里我只是介绍了爬虫是怎么用的而已。正如我们操作浏览器一样,我们也可以使用对应的API来实现,本人也是刚开始,后面还要慢慢去探讨这一项技术。我们其实不能保证网站的结构不改变,其实改变了我们就跟着变就好。
项目代码:github仓库
