Shell编程基础之sed/awk高级文件处理
sed:更改文件中的内容。
awk:切片文件中的内容。
grep:过滤文件中的内容。
并称shell文件处理三剑客。对于nginx,apache这些访问日志文件可以用awk进行相应的实现。
sed:
sed它在脚本里面是逐行处理的.处理完一行再处理下一行,
例1:
更改数据流.主要是对文本中的一些内容进行更改替换.但不生效在文件中.
[root@localhost 20200420]# vim sed_test.txt

[root@localhost 20200420]# cat sed_test.txt | sed 's/HELLO/Hello/'
#查看文本内容管道给sed,然后sed ‘ s/HELLO/hello/’
固定写法 sed 后加双引或单引,然后s///,三个杠中间会产生2个位置,第一个位置是匹配出来你要替换的内容,sed s/HELLO//,第二个位置是你要替换成的内容,sed ‘s/HELLO/Hello/’ 最后就是上面看到的内容,替换掉了.
例2:
把模式空间中的内容覆盖到文本.
对源文件修改或不修改取决于加不加-i
sed -i + 替换的内容 + 操作的对象
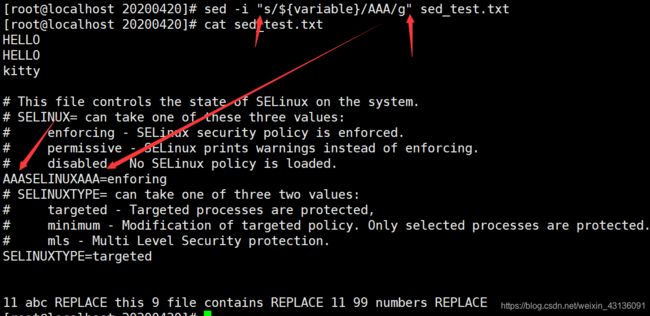
[root@localhost 20200420]# sed -i "s/hello/HELLO/" sed_test.txt

修改SELINUX配置文件:
[root@localhost 20200420]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config

例3:
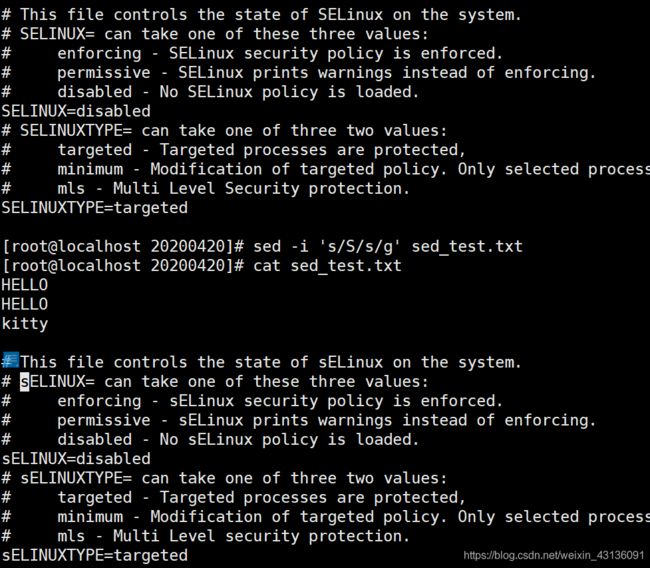
[root@localhost 20200420]# sed -i 's/S/s/g' sed_test.txt
sed -i ‘/被替换/替换成/g’ #g是全局的意思
和vim里面:% s///g一个意思
例4:
[root@localhost 20200420]#
echo "thisthisthisthis" | sed 's/this/THIS/2g'

#2g在上面这里代表从第二个this开始替换.
[root@localhost 20200420]# sed -i 's/aaa/111/3g' sed_test.txt
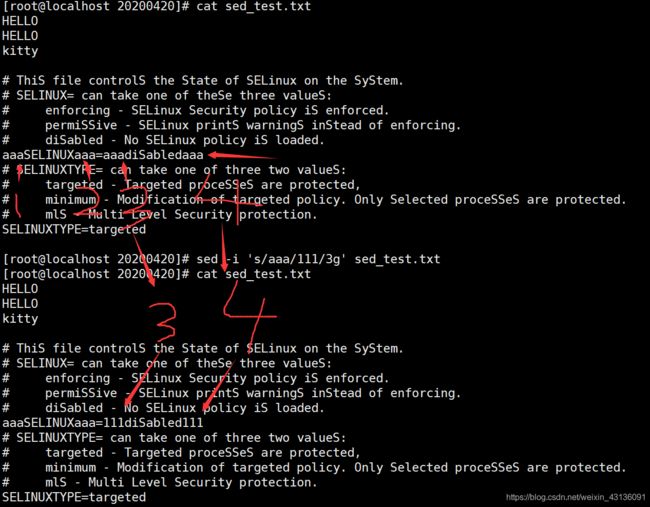
例5:
sed中的分隔符可以替换成别的字符,因为s标识会认为后面的字符为分隔符。它默认s后面的字符就是分隔符,只要保持3个符号是一致的就没问题。起决定作用的是s后面跟着的第一个符号是什么。# 号 :号 /号都可以,随个人喜好。
sed -i 's/aaa/111/3g' sed_test.txt
可以写成
sed -i 's#aaa#111#3g' sed_test.txt
例6:
可以利用sed来删除文件中的空行或内容.
需要用到正则表达式.
[root@localhost 20200420]# grep ^$ sed_test.txt
#过滤出空行. ^$这个组合代表空行.
[root@localhost 20200420]# sed -i '/^$/d' sed_test.txt
sed -i ‘/ 空行或者内容 /d’ #sed -i ‘//d’ 是删除匹配模式
要删除谁,就在两个/斜线中间加入你要删除的项.可以用正则,也可以确切到字符.d代表删除的意思.

删除内容例子:
正则表达式搭配sed删除文本内容.
[root@localhost 20200420]# echo "[Error] - 31/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# sed -i '/.*31\/Jan\/2018.*/d' sed_test.txt
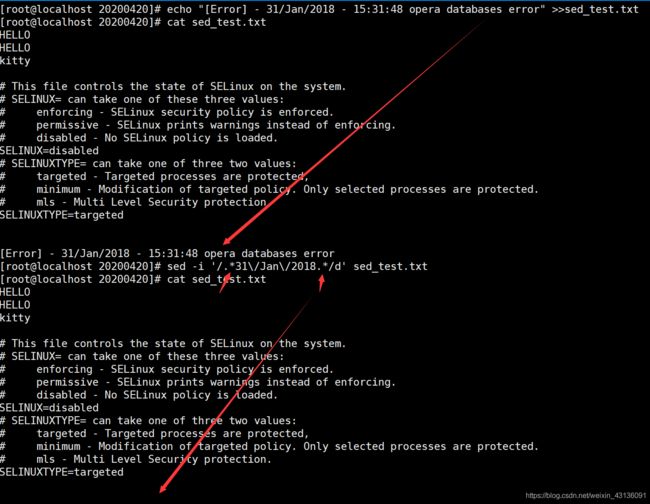
[root@localhost 20200420]# echo "[Error] - 31/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# sed -i /[\^.]*31\/Jan\/2018[^.]*/d' sed_test.txt

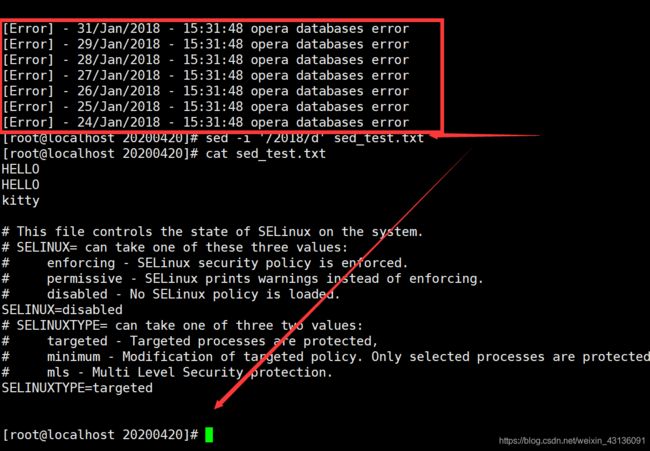
[root@localhost 20200420]# echo "[Error] - 31/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# echo "[Error] - 29/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# echo "[Error] - 28/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# echo "[Error] - 27/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# echo "[Error] - 26/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# echo "[Error] - 25/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
[root@localhost 20200420]# echo "[Error] - 24/Jan/2018 - 15:31:48 opera databases error" >>sed_test.txt
```bash
[root@localhost 20200420]# sed -i '/2018/d' sed_test.txt
#直接2018的就全删掉了.
线上的日志文件无时无刻会有人访问变得很大,当文件小于200M的时候可以快速使用这种方法去删掉文件中不必要的信息.大于200M的话损失的数据会更多,这种清理方法要慎用.
例7:
替换指定字符串或数字.
[root@localhost 20200420]# echo '11 abc 111 this 9 file contains 111 11 99 numbers 0000' >>sed_test.txt
[root@localhost 20200420]# sed -i 's/[0-9]\{3,\}/REPLACE/' sed_test.txt
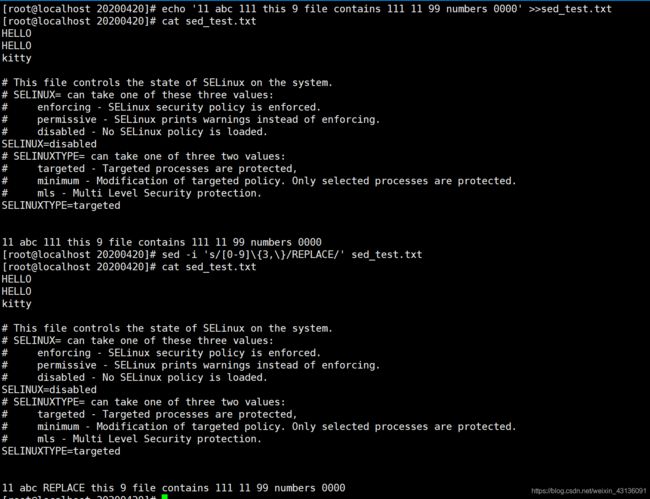
[root@localhost 20200420]# sed -i 's/[0-9]\{3,\}/REPLACE/g' sed_test.txt
#加个小g就全局替换.
#/b
#\b \b 等价于正则表达式的( )
例8:
由于sed使用-i参数的时候比较危险,我们可以在使用-i的时候后面加上个.bak就会产生一个备份文件,以防后悔.这种方法鼓励去使用.
sed -i.bak 's/SELINUX=disabled/SELINUX=enforing/' sed_test.txt


例9:
sed中要引用变量,就是把单引号’换成双引号”
如果脚本里面sed要调用到函数,那么记得把匹配模式的单引号换双引号.
[root@localhost 20200420]# variable=aaa
[root@localhost 20200420]# sed -i 's/${variable}/AAA/' sed_test.txt
#这样去sed的话文本内容没变.
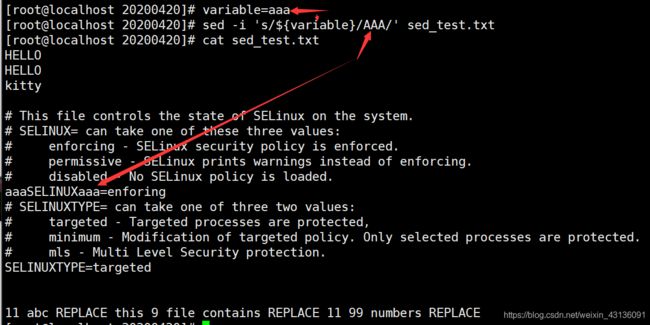
[root@localhost 20200420]# sed -i "s/${variable}/AAA/g" sed_test.txt
#换成双引号,就生效了.
生产案例:
删除mysql数据库⽇志中12⽉20⽇之前的⽇志条⽬
#!/usr/bin/env bash
#
# Author: bavdu
# Email: [email protected]
# Github: https://github.com/bavdu
# Date: 2018/12/20
for days in {1..31};do
{
sed -ri "/[^.]*${days}\/Jan\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Feb\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Mar\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Apr\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/May\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Jun\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Jul\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Aug\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Sep\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Oct\/2018[^.]*/d" $1
sed -ri "/[^.]*${days}\/Nov\/2018[^.]*/d" $1
}&
done
wait
echo "1 ~ 11 months remove finish..."
for days in {1..19}
do
{
sed -ri "/[^.]*${days}\/\/2018[^.]*/d" $1
}&
done
wait
echo "12 months remove finish..."
awk文本高级处理:
主要用于对文本做一些切片操作.
awk中的特殊变量:
NR: 表示记录编号, 当awk将⾏为记录时, 该变量相当于当前⾏号
NF: 表示字段数量, 当awk将⾏为记录时, 该变量相当于当前列号
$0: 表示当前记录的⽂本内容
$1: 表示当前记录的第⼀列⽂本内容
$2: 表示当前记录的第⼆列⽂本内容
[root@localhost 20200420]# cp /etc/passwd ./passwd
[root@localhost 20200420]# awk ‘BEGIN{} {} END {}’ passwd
#BEGIN{ }:通常去声明分隔符,比如你在这个文件里想用哪个字符作为参照物进行分割.
#{ }花括号:叫命令,根据分隔符去处理文本中的内容.
#END{ }:去处理命令语句块中所产生的数据.通常在上一个命令语句块就已经把数据处理完了,所以这个END一般情况下是用不上的.
**例1:**想去使用awk显示用户名及是否能登陆的shell
[root@localhost 20200420]# cp /etc/passwd ./passwd
[root@localhost 20200420]# awk ‘BEGIN{ FS=":" } { print $1 $NF } END{}’ passwd

[root@localhost 20200420]# awk ‘BEGIN{ FS=":" } { print $2,$3 } END{}’ passwd
#打印第二列第三列同理.
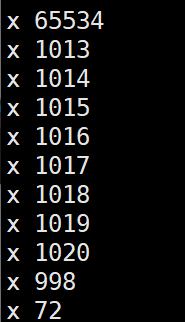
[root@localhost 20200420]# awk -F":" ‘{print $1} END {}’ passwd
#也可以写成这样,把BEGIN踢出去,用-F来声明分隔符.
例2:
打印指定行指定列的某个字符.
[root@localhost 20200420]# awk ‘BEGIN{ FS=":" } NR==2{print $5} END{}’ passwd
bin
NR==2 #表示第几行.
例3:
统计一个文本的行数,打印出文件中所有行的行号.
[root@localhost 20200420]# awk ‘BEGIN{} {print NR} END{}’ passwd
NR: 表示记录编号, 当awk将⾏为记录时, 该变量相当于当前⾏号
这里是固定的搭配,不用再声明分隔符,直接打印行号即可.
NR在指定它的值的时候写在外部,要打印NR它的时候要写在命令的内部.
例4:
在命令行中,传送变量到awk中.
$ var=1000
$ echo | awk -v VARIABLE=$var ‘{ print VARIABLE }’
先声明var=1000,然后awk 用-v去声明awk里面叫什么变量名(awk里的变量名要大写),它的值等于shell里面的$var.然后再应用到awk的命令块中去打印.
例5:
在脚本中,传送多个变量到awk中.
$ var1=“Variable01” ; var2=“Variable02”
$ echo | awk ‘{ print v1, v2}’ v1=$var1 v2=$var2
先声明2个变量.
然后awk里面打印v1,v2,这v1,v2是什么,在后面再声明.
为什么awk里面要{print v1,v2}然后再去声明这两个变量呢,如果写成{print $var1,$var2}实际上在awk里面是变成了{print $1,$2},因为$在awk里面属于特殊符,shell里面的$引用和awk里面的$会造成冲突,所以我们会在外部引用它.
这两种方式的话推荐使用第二种.
例6
在awk中使⽤for循环
awk ‘BEGIN{ FS=" " } { ips[$1]++ } END{ for (ip in ips){ print
ip,ips[ip]}}’ filename
[root@localhost 20200420]# cp /etc/httpd/logs/access_log ./
[root@localhost 20200420]# awk ‘BEGIN{ FS=" " } { ips[$1]++ } END{ for(ip in ips){print ip,":",ips[ip]} }’ access_log | sort -k3 -nr | head -10
192.168.0.103 : 111
::1 : 3
例7:
在awk中使⽤if条件判断
awk ‘BEGIN{ FS=":" } { if($3==0) { print $1 “is a admin.”} }’ /etc/passwd
$ awk -F: ‘{ if($3==0){print $1 " is administrator."} }’ /etc/passwd
$ awk ‘BEGIN{ FS=“分隔符” }{ if(判断条件){条件为真时所执⾏的语句}}’ filename
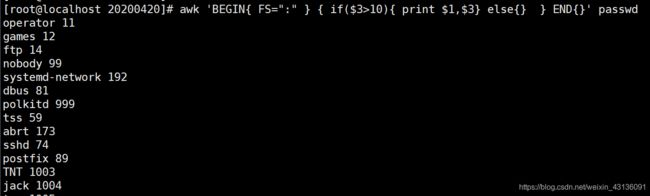
[root@localhost 20200420]# awk ‘BEGIN{ FS=":" } { if($3>10){ print $1,$3} else{} } END{}’ passwd