人工智能如何处理数据?如果把重点放在数据的处理方式上,那么长期共存的方式大概有两种:
特征学习(featurelearning),又叫表示学习(representation learning)或者表征学习
特征工程(featureengineering),主要指对于数据的人为处理提取,有时候也代指“洗数据”
不难看出,两者的主要区别在于前者是“学习的过程”,而后者被认为是一门“人为的工程”。用更加白话的方式来说,特征学习是从数据中自动抽取特征或者表示的方法,这个学习过程是模型自主的。而特征工程的过程是人为的对数据进行处理,得到我们认为的、适合后续模型使用的样式。
举个简单的例子,深度学习就是一种表示学习,其学习过程是一种对于有效特征的抽取过程。有用的特征在层层学习后抽取了出来,最终交给了后面的分类层进行预测。一种比较不严谨但直观的理解可以是,假设一个n层的深度学习网络,那么输入数据在被网络逐层抽象化,靠前的层(1~k)学到了低阶特征(low level features),中间层(k+1~m)学到了中阶特征(middle level features),而靠后的层上(m+1~n-1)特征达到了高度的抽象化获得了高阶特征(high level features),最终高度的抽象化的特征被应用于分类层(n)上,从而得到了良好的分类结果。一个常用例子是说卷积网络的前面几层可以学到“边的概念”,之后学到了“角的概念”,并逐步学到了更加抽象复杂的如“图形的概念”。下图就给出了一个直观的例子,即图像经过深度网络学习后得到了高度抽象的有效特征,从而作为预测层的输入数据,并最终预测目标是一只猫。
<img src="https://pic2.zhimg.com/v2-af7b9058eae749c647cb5a5ed3af248d_b.jpg" data-size="normal" data-rawwidth="1106" data-rawheight="464" class="origin_image zh-lightbox-thumb" width="1106" data-original="https://pic2.zhimg.com/v2-af7b9058eae749c647cb5a5ed3af248d_r.jpg">

输入数据通过网络后,抽取到了高维的抽象特征,从而促进了分类结果。原图[4]
另一个常见的例子就是下图中,深度信念网络(deep belief network)通过堆叠的受限玻尔兹曼机(Stacked RBM)来学习特征,和cnn不同这个过程是无监督的。将RBF堆叠的原因就是将底层RBF学到的特征逐渐传递的上层的RBF上,逐渐抽取复杂的特征。比如下图从左到右就可以是低层RBF学到的特征到高层RBF学到的复杂特征。在得到这些良好的特征后就可以传入后端的传统神经网络进行学习。
<img src="https://pic4.zhimg.com/v2-1c9649ba5340bef2e7fe293acab8ee3f_b.jpg" data-caption="" data-size="normal" data-rawwidth="720" data-rawheight="219" class="origin_image zh-lightbox-thumb" width="720" data-original="https://pic4.zhimg.com/v2-1c9649ba5340bef2e7fe293acab8ee3f_r.jpg">

换个不严谨的白话说法,深度学习的层层网络可以从数据中自动学习到有用的、高度抽象的特征,而最终目的是为了帮助分类层做出良好的预测。而深度学习为什么效果好?大概和它能够有效的抽取到特征脱不了关系。当然,深度学习的一大特点是其对数据的分布式表示(distributed representation)(*也和稀疏性表示等其他特性有关),最直观的例子可以是nlp中的word2vec,每个单词不再是割裂的而互相有了关联。类似的,不少网络中的参数共享就是分布式表示,不仅降低了参数量需求也提高对于数据的描述能力。仅看分类层的话,深度学习和其他的机器学习似乎没有天壤之别,但正因为有了种种良好的表示学习能力使其有了过人之处。下图直观的对比了我们上文提到的两种特征的学习方式,传统的机器学习方法主要依赖人工特征处理与提取,而深度学习依赖模型自身去学习数据的表示。
<img src="https://pic2.zhimg.com/v2-066a8ddfbe8c7c50b28353c15986fed9_b.jpg" data-size="normal" data-rawwidth="1776" data-rawheight="780" class="origin_image zh-lightbox-thumb" width="1776" data-original="https://pic2.zhimg.com/v2-066a8ddfbe8c7c50b28353c15986fed9_r.jpg">
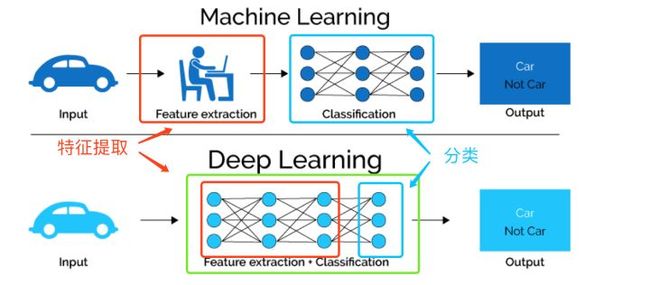
机器学习与深度学习对于特征抽取的不同之处,原图来源于[3]
综上,机器学习模型对于数据的处理可以被大致归类到两个方向:
表示学习:模型自动对输入数据进行学习,得到更有利于使用的特征(*可能同时做出了预测)。代表的算法大致包括:
深度学习,包括大部分常见的模型如cnn/rnn/dbn,也包括迁移学习等
某些无监督学习算法,如主成分分析(PCA)通过对数据转化而使得输入数据更有意义
某些树模型可以自动的学习到数据中的特征并同时作出预测
特征工程:模型依赖人为处理的数据特征,而模型的主要任务是预测,比如简单的线性回归期待良好的输入数据(如离散化后的数据)
需要注意的是,这种归类方法是不严谨的,仅为了直观目的而已。并没有一种划分说a算法是表示学习,而b算法不是,只是为了一种便于理解的划分。
因此,大部分的模型都处于纯粹的表示学习和纯粹的依赖人工特征之间,程度不同而已,很少有绝对的自动学习模型。详细的关于两种处理数据方法的对比和历史可以参考一篇最近的综述论文 [2],更早也更经典的关于特征学习的介绍可以参考论文 [1]。
那么好奇的读者会问:
1. 是不是自动的特征抽取(表示学习)总是更好?
答案是不一定的:1. 在数据量不够的时候,自动特征抽取的方法往往不如人为的特征工程 2. 当使用者对于数据和问题有深刻的理解时,人工的特征工程往往效果更好。
一个极端的例子是,在kaggle比赛中的特征工程总能带来一些提升,因此人工的特征抽取和处理依然有用武之地。
同时也值得注意,表示学习的另一好处是高度抽象化的特征往往可以被应用于相关的领域上,这也是我们常说的迁移学习(transfer learning)的思路。比如有了大量猫的图片以后,不仅可以用于预测一个物体是不是猫,也可以用于将抽取到的特征再运用于其他类似的领域从而节省数据开销。
2. 特征学习(表示学习),特征工程,特征选择,维度压缩之间有什么关系?
从某个角度来看,表示学习有“嵌入式的特征选择”(embedded feature selection)的特性,其表示学习嵌入到了模型中。举个简单的例子,决策树模型在训练过程中可以同时学习到不同特征的重要性,而这个过程是建模的一部分,是一种嵌入式的特征选择。巧合的看,表示学习也是一种嵌入表示(embedded representation)。如维度压缩方法PCA,也是一种将高维数据找到合适的低维嵌入的过程,前文提到的word2vec也是另一种“嵌入”。至于这种“嵌入”是否必须是高维到低维,不一定但往往是因为特征被抽象化了。以上提到的两种嵌入一种是对于模型的嵌入,一种是在维度上嵌入,主要是名字上的巧合。
3. 理解不同数据处理方法对于我们有什么帮助?
首先对于模型选择有一定的帮助:
当我们数据量不大,且对于数据非常理解时,人为的特征处理也就是特征工程是合适的。比如去掉无关数据、选择适合的数据、合并数据、对数据做离散化等。
当数据量较大或者我们的人为先验理解很有限时,可以尝试表示学习,如依赖一气呵成的深度学习,效果往往不错。
4. 为什么有的模型拥有表示学习的能力,而有的没有?
这个问题需要分模型讨论。以深度学习为例,特征学习是一种对于模型的理解,并不是唯一的理解,而为什么泛化效果好,还缺乏系统的理论研究。
5. 特征工程指的是对于数据的清理,和学习有什么关系?
此处我们想再次强调的是,这个不是一个严谨的科学划分,是一种直观的理解。如果所使用的模型拥有对于数据的简化、特征表示和抽取能力,我们都可以认为它是有表示学习的特性。至于哪个模型算,哪个模型不算,不必纠结这点。而狭义的特征工程指的是处理缺失值、特征选择、维度压缩等各种预处理手段,而从更大的角度看主要目的是提高数据的表示能力。对于数据的人为提炼使其有了更好的表达,这其实是人工的表示学习。
写在最后是,这篇回答仅仅是一种对于机器学习中数据处理方法的理解,并不是唯一正确的看法。有鉴于机器学习领域的知识更迭速度很快,个人的知识储备也有限,仅供参考。
[1]Representation Learning: A Review and New Perspectives
[2]An overview on data representation learning: From traditional feature learning to recent deep learning
[3]Log Analytics With Deep Learning and Machine Learning - XenonStack
[4] Adam Coates,Deep Learning for Vision