核密度估计
假如知己n个点,我们想要知道整体的概率密度分布,则可以使用概率密度估计来求解。
一步步是解更加完美:
- 盒子模型
假如我们已经知道如下点,考虑一维情况。
X=[2, 22, 42, 62, 82, 102, 122, 142,162, 182, 202 , 222],最简单的我们可以直接使用直方图来进行概率估计。每一个点用一个盒子来替代,那么此时我们有3个参数需要人工确定:
盒子长我们分别设定0.5
盒子右边界设定为[0-0.5]和[0.25-0.75]两种情况分别讨论如下两个图所示。
盒子高度为1/n=1/12 ,n为数据的总数
那么我们,利用盒子累加的方式,画图如下所示,则方块的高地为密度的一直估计:
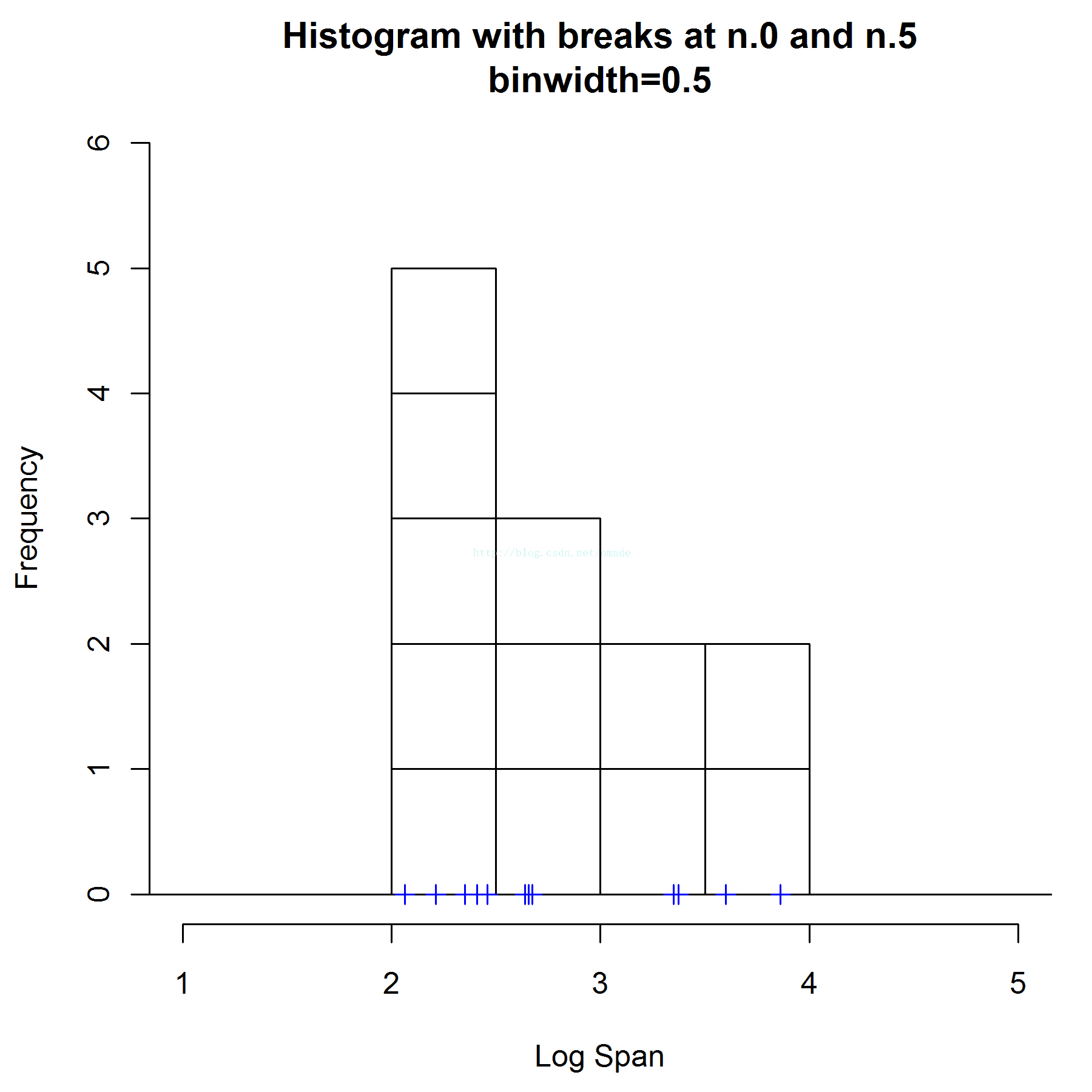
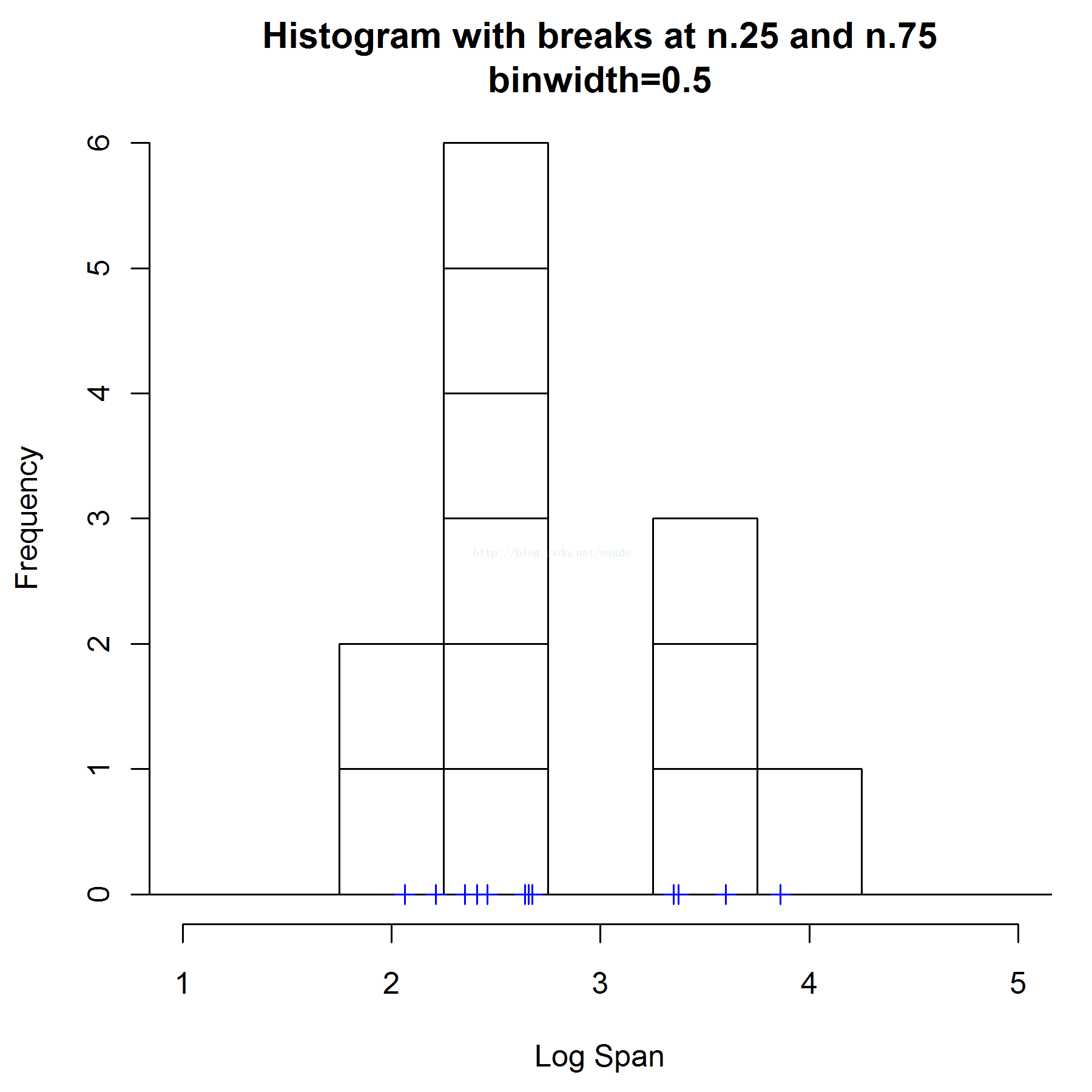
可以看出,当你的右边界设定不同的时候,产生的概率密度估计差异非常大,单峰和双峰的区别。
暴露了一下的一些不足:
1.盒子长度对结果影响太大
2.盒子的边界对结果影响太大
3.不平滑
所以我们就出现了核概率密度估计,可以有效解决2,3问题。
2.盒子核的概率密度估计
我们假定盒子的长度已经设定,我们将盒子的中心点和该盒子对应的点重合,这样进行,,盒子高度任然是1/12,进行盒子上的累加则可以得到如下的直方图。

这个我们则可以称为以盒子为核的核密度估计。但是任然存在以下问题:
- 不平滑
- 盒子长度不好确定
基于此,我们可以选择出更加平滑的核进行密度估计,则可以有效解决问题1。
3.高斯核概率密度估计
我们使用高斯核来进行密度估计,则唯一需要确定的参数就是带宽,即盒子长度,同样也是正态分布的标准差。我们设为0.1,则高斯核密度估计可以如下进行:
对每一个点都产生一个高斯分布,u=点坐标,σ=0.1,则可以得到如下的核密度估计,总体的密度估计则为每一个点的密度估计总和,注意的是因为所有的密度概率函数积分等1,所有我们得到的子正态分布的概率即覆盖的面积为1/12才行。
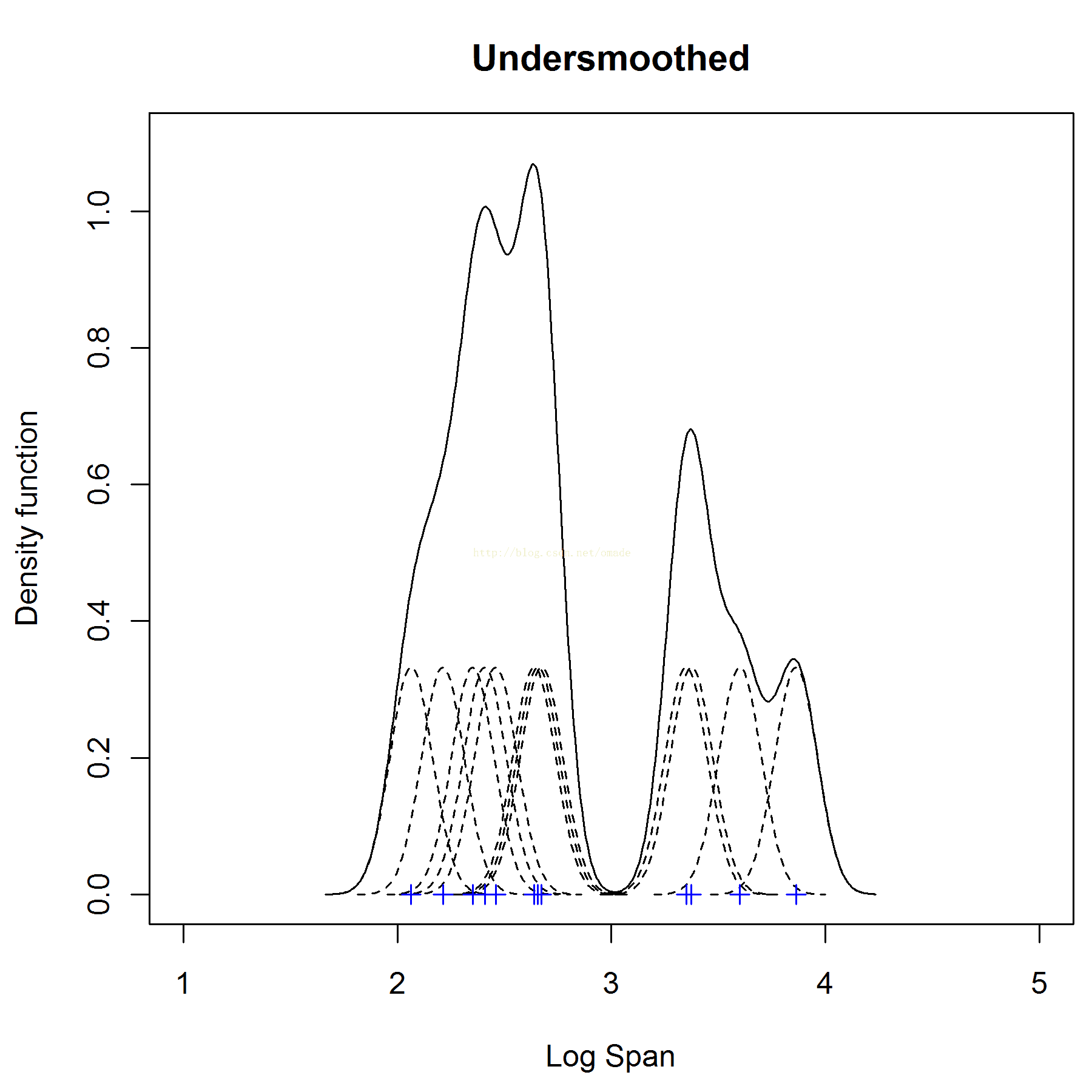
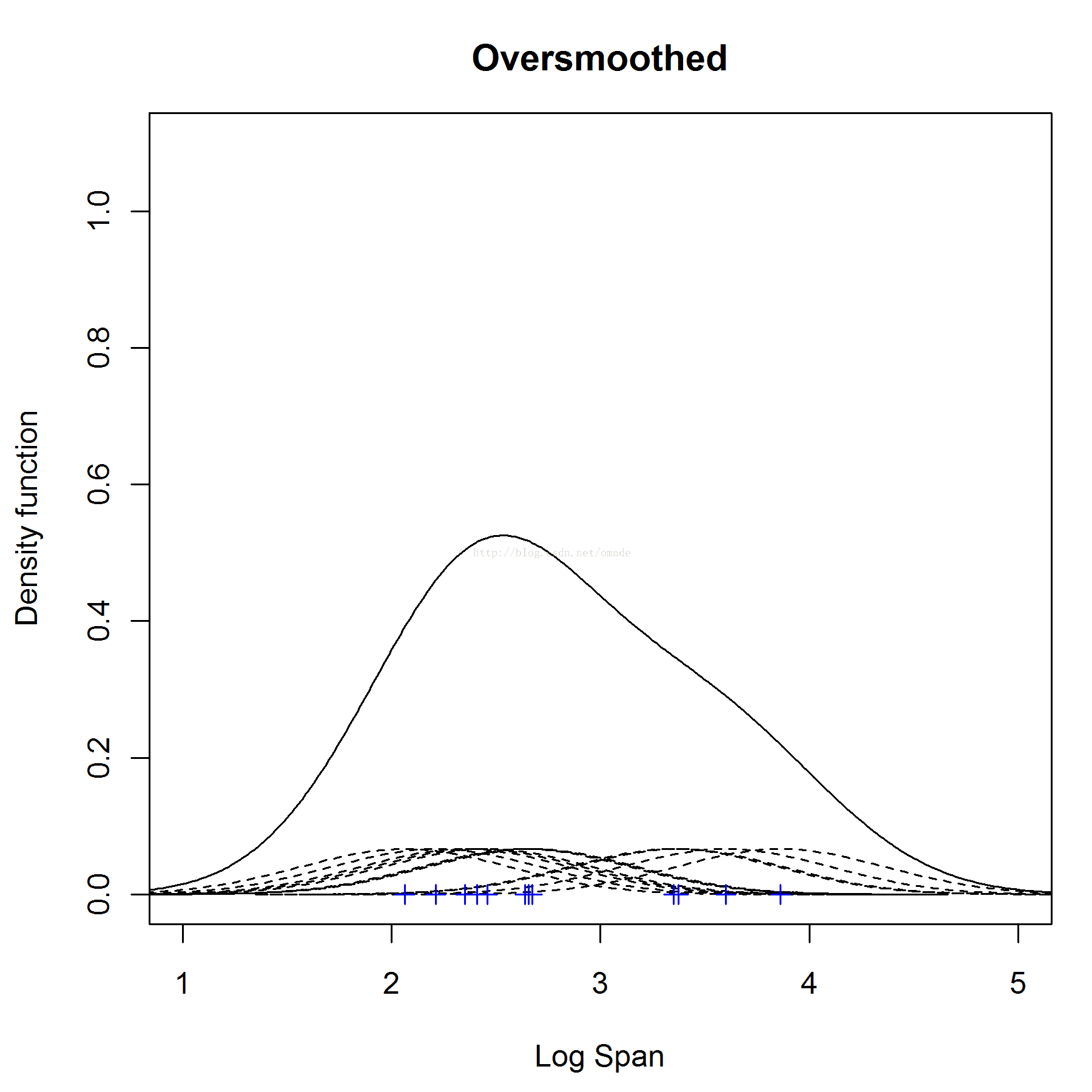
但是,在此我们也注意到了,因为h=0.1导致不平滑,所以我们用h=0.5来替代,但是有导致另外一问题,即远离了真实的最优值,我们需要一些方法去确认最优h,则可以使用最小化MASE。
综述:核密度估计其实就是,确定一个核函数,然后对每一个点都拟合一个核函数,这样最终的密度曲线就是每一个点上核函数的积累。
sklearn核函数形式
- Gaussian kernel (kernel
![]()
- Tophat kernel (kernel
![]() if
if ![]()
- Epanechnikov kernel (kernel
![]()
- Exponential kernel (kernel
![]()
- Linear kernel (kernel
![]() if
if ![]()
- Cosine kernel (kernel
![]() if
if ![]()
最小化MASE:
不同的带宽得到的估计结果差别很大,那么如何选择h?显然是选择可以使误差最小的。下面用平均积分平方误差(mean intergrated squared error)的大小来衡量h的优劣。
最小和估计密度和实际密度的均方误差:
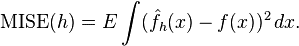
在weak assumptions下,MISE (h) =AMISE(h) + o(1/(nh) + h4) ,其中AMISE为渐进的MISE。而AMISE有:
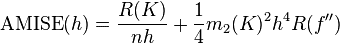
其中

为了使MISE(h)最小,则转化为求极点问题
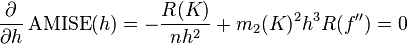
使用最后得到了:

当核函数确定之后,h公式里的R、m、f''都可以确定下来,有
(hAMISE ~ n−1/5),AMISE(h) = O(n−4/5)。
如果带宽不是固定的,其变化取决于估计的位置(balloon estimator)或样本点(逐点估计pointwise estimator),由此可以产产生一个非常强大的方法称为自适应或可变带宽核密度估计。
对于公式的理解:
同样我们需要进行密度估计,先用直方图:

如果你还记得导数的定义,密度函数可以写为:

我们把分布函数用上面的经验分布函数替代,那么上式分子上就是落在[x-h,x+h]区间的点的个数。我们可以把f(x)的估计写成:

这里注意:
#代表个数,即![]() 代表xi在区间中的数目,
代表xi在区间中的数目,
![]() 这里“1”后面的部分,符合条件则返回true不然返回false。所以其就是符合条件的点的数目。其实这个可以看成是用盒子作为密度函数的密度估计方式。
这里“1”后面的部分,符合条件则返回true不然返回false。所以其就是符合条件的点的数目。其实这个可以看成是用盒子作为密度函数的密度估计方式。

其中可以知道K0(t)=1/2*1(t<1)代表的是符合条件的这一个点去构建K0这种核函数,得到的是分布。
 则代表x出的概率密度等于,
则代表x出的概率密度等于,
遍历每一个点,
符合条件的每一个点(x-xih![]() )都去去构建了核函数K0的分布。
)都去去构建了核函数K0的分布。
除以h得到的是每一个点构建的概率密度函数,
累加得出所有点对于x出密度估计的总值
为了使总和为1,所以需要除以n。
 的解释也一样
的解释也一样
只是每个点用来构建的核函数编程的ϴ代表的高斯函数。
所以理论上存在一个最小化mean square error的一个h。h的选取应该取决于N,当N越大的时候,我们可以用一个比较小的h,因为较大的N保证了即使比较小的h也足以保证区间内有足够多的点用于计算概率密度。因而,我们通常要求当N→∞,h→0。比如,在这里可以推导出,最优的h应该是N的-1/5次方乘以一个常数,也就是![]() 。对于正态分布而言,可以计算出c=1.05×标准差。
。对于正态分布而言,可以计算出c=1.05×标准差。
关于h的确定可以查看这篇博客
http://blog.csdn.net/chixuezhihun/article/details/73928749
python的实现:
http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KDTree.html#sklearn.neighbors.KDTree.kernel_density
参考文档:
https://www.zhihu.com/question/27301358/answer/105267357?from=profile_answer_card
http://www.cnblogs.com/wt869054461/p/5935992.html
http://blog.csdn.net/yuanxing14/article/details/41948485
http://blog.csdn.net/pipisorry/article/details/53635895
matlab 下面的核密度估计
http://blog.csdn.net/matlab_matlab/article/details/56286868