TensorRT介绍、安装和测试
1. What is TensorRT ?
TensorRT的核心是一个C++库,能在NVIDIA的图像处理单元(GPU)上进行高性能的推断。它为与TensorFlow, Caffe, PyTorch, MXNet等主流训练框架进行互补工作而设计,专注于在GPU上高效地运行训练好的网络,生成预测结果。
有些训练框架,如TensorFlow,已经集成了TensorRT,所以能够直接在框架内部加速推断。除此之外,TensorRT可以用作应用程序中的库。它包含了一些用于导入TensorFlow, Caffe, PyTorch, MXNet等不同框架模型的解析器,提供了C++和Python 的API来构建模型。
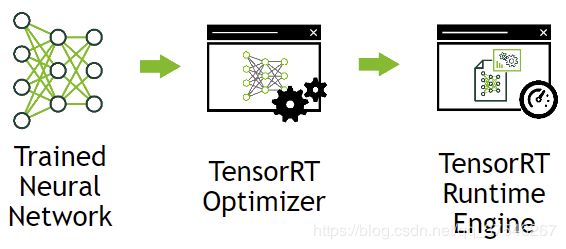
TensorRT通过组合层和优化内核选择来优化网络,从而能改善延迟、吞吐量、功效和内存消耗,如果需要的化,可以以较低精度的方式运行来进一步提升模型运算的性能。
TensorRT被定义为高性能推理优化器和部件运行引擎的一部分,它接受在一些主流框架上训练的模型,优化神经网络计算,生成轻量级运行引擎。

1.1 Benefits Of TensorRT
主要在以下几个方面:
吞吐量: 通过 推理量/每秒 或 样本量/每秒 来衡量;
效率:单位功率的吞吐量,通常表示为性能/瓦特
延迟:执行推理需要的时间,通常是毫秒级
准确率:训练的模型提供准确答案的能力
内存占用:模型推理需要的主机和设备内存取决于所用算法,这限制了哪些网络 可以再给定平台上运行
1.2 How Does TensorRT Work?
为了优化推理模型,TensorRT采用训练的网络定义,执行优化,包括特定平台的优化,并生成推理引擎。此过程称为构建阶段(build phase)。构建阶段可能需要较长时间,尤其是在嵌入式平台运行时。典型的应用可以构建一次引擎,将其序列化后保存文件供以后使用(注意此文件不能跨平台跨TensorRT版本使用)。
构建阶段在layer上的优化:
消除未使用的输出
消除等同于无操作的操作
融合卷积,偏置和ReLu操作
聚合足够相似的参数和相同的源张量的操作(如1*1卷积)
通过将层输出定向到正确的最终目标来合并连接层
如果有必要的话,构建器也能修改权值的精度
构建阶段还在虚拟数据上运行图层以从其内核目录中选择最快的内核,并在适当的情况下执行权重预格式化和内存优化。
1.3 What Capabilities Does TensorRT Provide?
TensorRT使开发人员能够导入、校准、生成和部署优化的网络。网络可以从caffe直接导入,也可以通过UFF或ONNX格式从其他框架导入。它们也可以通过实例化单个图层并直接设置参数和权重来以编程的方式创建。用户还可以使用Plugin界面通过TensorRT运行自定义图层,通过graphurgeon程序可以将TensorFlow节点映射到TensorRT中的自定义层,从而可以使TensorRT对许多TensorFlow网络进行推理。
TensorRT在所有的支持平台上提供C++实现,在X86,aarch64, 和 ppc64le上提供Python实现。
TensorRT核心库中的关键接口:
网络定义:网络定义接口为应用程序提供了指定网络定义的方法。 可以指定输入和输出张量,可以添加层,并且有一个用于配置每种支持的层类型的界面。 以及卷积层和循环层等层类型,以及Plugin层类型使应用程序可以实现TensorRT本身不支持的功能。
编译器:Builder接口允许根据网络定义创建优化的引擎。 它允许应用程序指定最大批处理和工作空间大小,最小可接受的精度水平,用于自动调整的定时迭代计数以及用于量化以8位精度运行的网络的接口。
引擎:Engine接口允许应用程序执行推理。 它支持同步和异步执行,概要分析以及枚举和查询引擎输入和输出的绑定。 单引擎可以具有多个执行上下文,从而允许将一组训练有素的参数用于同时执行多个批次。
TensorRT提供了几种解析器,用于导入经过训练的网络以构建网络定义:
Caffe解析器:该解析器可用于解析在BVLC Caffe或NVCaffe 0.16中创建的Caffe网络,它还提供了为自定义层注册插件工厂的功能。
UFF解析器:该解析器可用于解析UFF格式的网络,它还提供了注册插件工厂并为自定义层传递字段属性的功能。
ONNX解析器:用于解析onnx模型。
TensorRT提供了C ++ API和Python API。本质上,C ++ API和Python API在满足需求方面应该几乎相同。 C ++ API应该用于任何对性能至关重要的场景,以及在安全性很重要的情况下,例如在自动驾驶中。Python API的主要优点是易于进行数据预处理和后处理,因为可以使用NumPy和SciPy等各种库。
2.Installation
2.1 装前须知
windows zip安装包暂不支持Python,将来可能会支持;
如果你需要使用Python API,则需要安装PyCUDA(pip install ‘pycuda>=2017.1.1’)
目前最新的TensorRT Release为:TensorRT Release 7.0
确保你已经安装好CUDA,目前支持的CUDA版本:9.0, 10.0和10.2
最新的TensorRT支持 TensorFlow 1.14.0, PyTorch 1.3.0
保证训练和模型转换的环境一致性,如CUDA,cuDNN
提供了多种安装方式:Debian、RPM,Zip、Tar。
2.2 下载
下载地址:https://developer.nvidia.com/nvidia-tensorrt-download,需要注册nvidia的账号

根据自己的cuda和cudnn版本选择(亲测和ubuntu 16.04或18.04无关),这里推荐下载tar包安装方式。
2.3 安装
#在home下解压
tar xzvf TensorRT-XXXXXX.tar
#解压得到TensorRT-XXXXXX的文件夹,将里边的lib绝对路径添加到环境变量中
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/xxxx/TensorRT-XXXXXX/lib
#安装TensorRT,根据python版本选择
cd TensorRT-XXXXXX/python
pip install tensorrt-7.0.0.11-cp27-none-linux_x86_64.whl
#安装UFF
cd TensorRT-XXXXXX/uff
pip install uff-0.6.5-py2.py3-none-any.whl
#安装graphsurgeon
cd TensorRT-XXXXXX/graphsurgeon
pip install graphsurgeon-0.4.1-py2.py3-none-any.whl
至此,安装完成,测试一下:
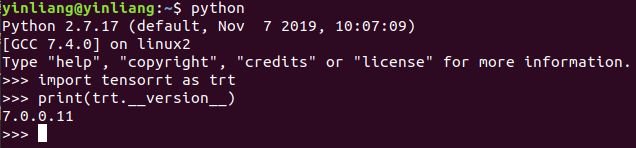
3 使用
这里测试一个使用Python API的demo,使用 /home/xx/TensorRT-xxx/samples/python目录下的’end_to_end_tensorflow_mnist’样例,这是一个简单的手写字符识别模型lenet,采用tensorflow网络训练。
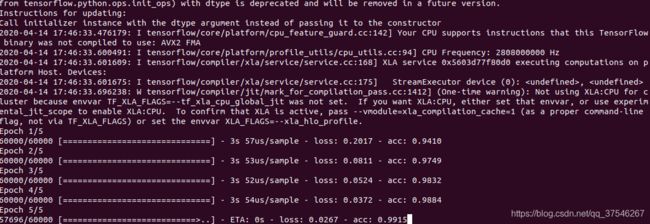
3.1 训练
运行"python model.py",开始训练模型,在"models"目录下生成"lenet5.pb"文件。
3.2 模型转换
convert-to-uff lenet5.pb
将pb文件转换为uff文件,打印出了模型转换的一些信息,生成了"lenet5.uff"文件
Loading lenet5.pb
WARNING:tensorflow:From /home/yinliang/.local/lib/python2.7/site-packages/uff/converters/tensorflow/conversion_helpers.py:227: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.
WARNING:tensorflow:From /home/yinliang/.local/lib/python2.7/site-packages/uff/bin/../../graphsurgeon/_utils.py:2: The name tf.NodeDef is deprecated. Please use tf.compat.v1.NodeDef instead.
UFF Version 0.6.5
=== Automatically deduced input nodes ===
[name: "input_1"
op: "Placeholder"
attr {
key: "dtype"
value {
type: DT_FLOAT
}
}
attr {
key: "shape"
value {
shape {
dim {
size: -1
}
dim {
size: 28
}
dim {
size: 28
}
dim {
size: 1
}
}
}
}
]
=========================================
=== Automatically deduced output nodes ===
[name: "dense_1/Softmax"
op: "Softmax"
input: "dense_1/BiasAdd"
attr {
key: "T"
value {
type: DT_FLOAT
}
}
]
==========================================
Using output node dense_1/Softmax
Converting to UFF graph
DEBUG: convert reshape to flatten node
DEBUG [/home/yinliang/.local/lib/python2.7/site-packages/uff/converters/tensorflow/converter.pyc:96] Marking [u'dense_1/Softmax'] as outputs
No. nodes: 13
UFF Output written to lenet5.uff
3.3测试
运行"python sample.py"
 这里报了一个关于cuDNN版本的警告,最好保持版本一致,如果报错找不到测试图像,可能是安装路径的问题(我就没有找到测试图像,自己另外在网上找的图测的),关键代码片段:
这里报了一个关于cuDNN版本的警告,最好保持版本一致,如果报错找不到测试图像,可能是安装路径的问题(我就没有找到测试图像,自己另外在网上找的图测的),关键代码片段:
构建引擎
def build_engine(model_file):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.UffParser() as parser:
builder.max_workspace_size = GiB(1) #最大工作空间大小
# 解析 Uff 网络
parser.register_input(ModelData.INPUT_NAME, ModelData.INPUT_SHAPE) #输入,输出节点的名字以及形状在前面模型转换的过程中可以看到
parser.register_output(ModelData.OUTPUT_NAME)
parser.parse(model_file, network)
# 构建引擎
return builder.build_cuda_engine(network)
两个特别重要的属性是最大批处理大小和最大工作空间大小,最大批次大小指定TensorRT将为其优化的批次大小,在运行时可以选择较小的批次大小。层算法通常需要临时工作空间存放中间值, 此参数限制网络中任何层可以使用的最大大小。 如果提供的空间不足,则TensorRT可能无法实现给定层的计算。
内存分配,为输入和输出分配一些主机和设备缓冲区
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
# 确定需要分配的内存大小
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# 给主机和GPU分配内存
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
执行推断,创建一些空间来存储中间激活值。 由于引擎保留了网络定义和训练好的的参数,因此需要额外的空间。 这些是在执行context中保存的::
with engine.create_execution_context() as context:
case_num = load_normalized_case(pagelocked_buffer=inputs[0].host)
# The common.do_inference function will return a list of outputs - we only have one in this case.
[output] = do_inference(context, bindings=bindings, inputs=inputs, outputs=outputs, stream=stream)
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# 以异步的方式将数据从主机传到GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# 将预测结果从GPU反传回主机.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]