人脸识别模块RetinaFace
RetinaFace,人脸检测用这个。论文地址:
https://arxiv.org/pdf/1905.00641.pdf
代码地址:
mxnet框架:
https://github.com/deepinsight/insightface/tree/master/RetinaFace
pytorch框架
https://github.com/biubug6/Face-Detector-1MB-with-landmark
框架: mxnet
专业词语:
facial attribute 面部特征
facial identity recognition面部识别
face alignment 人脸对齐
pixel-wise face parsing 逐像素人脸分析
3D dense correspondence regression 三维密集对应回归
occluded face detection 遮挡人脸检测
quite coarse and does not contain semantic information相当粗糙,不包含语义信息
morphable models 变形模型
mesh decoder 网格解码器
Context Modelling:上下文建模
deformable convolution network 可变形卷积网络
model geometric transformations模型几何变换
fast localised spectral filtering 快速局域谱滤波
VGA(640X480)大小图像
介绍:
retinaface是insightface团队提出的one-stage人脸检测算法,并开源代码和数据集,在widerface上有非常好的表现.它利用联合监督和自我监督(这是啥?)的多任务学习,在各种人脸尺度上执行像素方面(这是?)的人脸定位.
论文主要贡献:
1)在one-stage目标检测网络设计的基础上,增加两条平行分支,一支预测五个关键点,一支预测每个人脸像素的三维位置和对应关系,这样网络总共就是4条平行分支,见图1;
2)在widerface上,retinaface性能优于现有技术水平预测AP1.1%(AP=91.4%)
3)在IJB-C数据集上,retinaface有助于改进ArcFace验证精度,这表明更好的人脸定位可以显著提高人脸识别.
4)通过采用轻量级骨干网络,retinaface可以在单cpu核上实时运行,以实现vga分辨率的图像
5)代码开源并且将自己在widerface上手动标注的5个关键面部点数据开源,在这个额外的监督信号的帮助下观察面部检测的重要改进,
创新点:
1.整合:人脸检测,人脸对齐,像素级的人脸分析,3D密集通信回归
2.通过利用强监督和自监督(这是什么?代码中体现在哪里)多任务损失函数来实现上述功能.
网络与常规one-stage检测网络比较(例如yolo,retinanet)
主要相同点:
都是在不同下采样层进行预测,且都采用固定的anchors,预测都是相对anchors的偏移量
主要不同点:
retinaface多了关键点检测
训练数据集已经转成了MXNet binary format,网络骨干层包含resnet, mobilefacenet, mobilenet, inceptionresnet_v2,densent,dpn
损失函数包含:softmax, sphereface, cosineface, arcface and euclidean/angular loss
网络大致结构
Lcls:人脸分类loss,
Lbox:人脸框回归loss,
Lpts:人脸关键点回归loss,5点,
Lpixel:自监督3D Mesh Renderer 稠密人脸回归
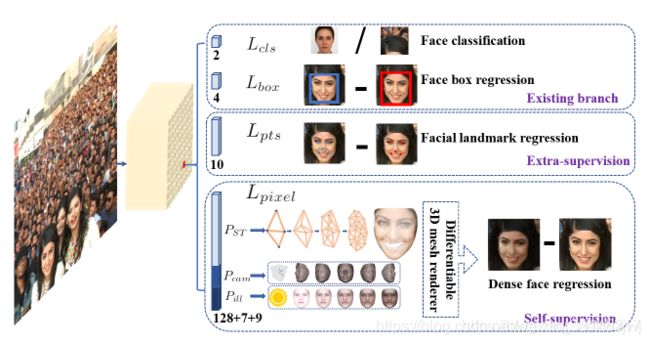
图1
从该图可以看出RetinaFace是4条平行的分支,
(1)第一条预测是否是人脸
(2)第二条预测人脸框的偏移量
(3)第三条预测人脸关键点的偏移量
(4)没看懂
另外,类似于YOLO3,采用了多阶段预测,就是在网络不同的下采样层做预测,论文里,最开始是5种下采样,这种多阶段预测本质上就是retinanet中同样采用的特征金字塔网络结构,单阶稠密人脸定位,多任务loss学习
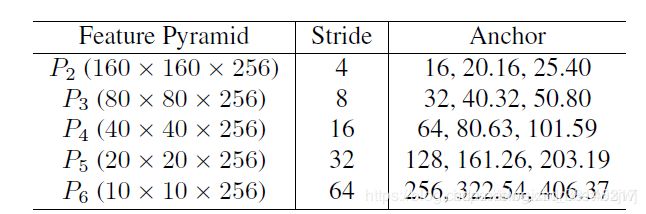
网络输入图片尺寸为(640,640,3),
第一个下采样,stride=4, 采样后得到的特征图尺寸:640/4=160
第2个下采样,stride=8, 采样后得到的特征图尺寸:640/8=80
....
第5个下采样,stride=64, 采样后得到的特征图尺寸:640/64=10
上述过程可以看成是构造了5层特征金字塔
每层特征图中的每个点预测3种anchors,则总的anchors数量就是(160*160+80*80+40*40+20*20+10*10)*3=102300,
但是在代码中,只有stride为(32,16,8)的输出,且每个点只有两个anchors
优点:
1.加入了关键点的分支,这样可以确保检测到的人脸质量,而且在损失函数中也只是将其作为一个比较小的约束项,不怎么会影响分类以及人脸框的判断,但是一旦关键点太过偏离就会使loss相对变大,就会产生约束