Prometheus 服务器监控高可用
一、Prometheus 各模块儿作用
| 模块儿名 | 含义 |
|---|---|
| Prometheus Server | 监控主体 |
| Node Exporter | 采集当前主机的系统资源使用情况,如 CPU、内存等 |
| Alertmanager | 处理告警信息,如发送邮件、短信、微信通知等 |
| Blackbox Exporter | 网络探测,如检测服务是否运行中等 |
二、安装 Prometheus Server
1、安装 Prometheus Server
https://prometheus.io/download/
选择适合自己系统的版本,这里以linux amd64 2.19.1版本为例进行演示
tar -zxvf prometheus-2.19.1.linux-amd64.tar.gz -C ~/prometheus/
cd ~/prometheus/prometheus-2.19.1.linux-amd64/
vim prometheus.yml
会看到默认的 Prometheus 配置文件 promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
Promtheus 作为一个时间序列数据库,其采集的数据会以文件的形似存储在本地中,默认的存储路径为 data/,在运行服务的时候会自行创建
$ ./prometheus
level=info ts=2020-06-22T07:28:06.466Z caller=main.go:302 msg="No time or size retention was set so using the default time retention" duration=15d
level=info ts=2020-06-22T07:28:06.466Z caller=main.go:337 msg="Starting Prometheus" version="(version=2.19.1, branch=HEAD, revision=eba3fdcbf0d378b66600281903e3aab515732b39)"
level=info ts=2020-06-22T07:28:06.466Z caller=main.go:338 build_context="(go=go1.14.4, user=root@62700b3d0ef9, date=20200618-16:35:26)"
level=info ts=2020-06-22T07:28:06.466Z caller=main.go:339 host_details="(Linux 5.4.44-1-MANJARO #1 SMP PREEMPT Wed Jun 3 14:48:07 UTC 2020 x86_64 jl-qtk5 (none))"
level=info ts=2020-06-22T07:28:06.466Z caller=main.go:340 fd_limits="(soft=1024, hard=524288)"
level=info ts=2020-06-22T07:28:06.466Z caller=main.go:341 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2020-06-22T07:28:06.468Z caller=web.go:524 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2020-06-22T07:28:06.468Z caller=main.go:678 msg="Starting TSDB ..."
level=info ts=2020-06-22T07:28:06.471Z caller=head.go:645 component=tsdb msg="Replaying WAL and on-disk memory mappable chunks if any, this may take a while"
level=info ts=2020-06-22T07:28:06.472Z caller=head.go:706 component=tsdb msg="WAL segment loaded" segment=0 maxSegment=1
level=info ts=2020-06-22T07:28:06.472Z caller=head.go:706 component=tsdb msg="WAL segment loaded" segment=1 maxSegment=1
level=info ts=2020-06-22T07:28:06.472Z caller=head.go:709 component=tsdb msg="WAL replay completed" duration=947.648µs
level=info ts=2020-06-22T07:28:06.473Z caller=main.go:694 fs_type=EXT4_SUPER_MAGIC
level=info ts=2020-06-22T07:28:06.473Z caller=main.go:695 msg="TSDB started"
level=info ts=2020-06-22T07:28:06.473Z caller=main.go:799 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2020-06-22T07:28:06.474Z caller=main.go:827 msg="Completed loading of configuration file" filename=prometheus.yml
level=info ts=2020-06-22T07:28:06.474Z caller=main.go:646 msg="Server is ready to receive web requests."
启动成功,默认端口号为 9090,可以通过 http://localhost:9090 访问 Prometheus 的 UI 界面:
三、使用 Node Exporter 采集主机数据
1、安装 Node Exporter
在 Prometheus 的架构设计中,Prometheus Server 并不直接监控特定的目标,其主要任务是负责数据的收集,存储并且对外提供数据查询支持。因此为了能够监控到某些东西,如主机的 CPU 使用率、内存和硬盘等,我们需要使用到 Exporter。Prometheus 周期性的从 Exporter 暴露的 HTTP 服务地址拉取监控样本数据。这里我们采用 Node Exporter 采集主机信息。https://prometheus.io/download/#node_exporter
$ tar -zxvf node_exporter-1.0.1.linux-amd64.tar.gz -C ~/prometheus/
$ cd ~/prometheus/node_exporter-1.0.1.linux-amd64/
$ ./node_exporter
level=info ts=2020-06-22T08:21:09.796Z caller=node_exporter.go:177 msg="Starting node_exporter" version="(version=1.0.1, branch=HEAD, revision=3715be6ae899f2a9b9dbfd9c39f3e09a7bd4559f)"
level=info ts=2020-06-22T08:21:09.796Z caller=node_exporter.go:178 msg="Build context" build_context="(go=go1.14.4, user=root@1f76dbbcfa55, date=20200616-12:44:12)"
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:105 msg="Enabled collectors"
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=arp
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=bcache
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=bonding
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=btrfs
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=conntrack
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=cpu
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=cpufreq
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=diskstats
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=edac
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=entropy
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=filefd
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=filesystem
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=hwmon
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=infiniband
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=ipvs
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=loadavg
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=mdadm
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=meminfo
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=netclass
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=netdev
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=netstat
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=nfs
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=nfsd
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=powersupplyclass
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=pressure
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=rapl
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=schedstat
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=sockstat
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=softnet
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=stat
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=textfile
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=thermal_zone
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=time
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=timex
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=udp_queues
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=uname
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=vmstat
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=xfs
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:112 collector=zfs
level=info ts=2020-06-22T08:21:09.797Z caller=node_exporter.go:191 msg="Listening on" address=:9100
level=info ts=2020-06-22T08:21:09.797Z caller=tls_config.go:170 msg="TLS is disabled and it cannot be enabled on the fly." http2=false
2、从 Node Exporter 收集监控数据
为了能够让 Prometheus Server 能够从当前 Node Exporter 获取到监控数据,这里需要修改 Prometheus 的配置文件。编辑 prometheus.yml 并在 scrape_configs 节点下添加以下内容:
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
labels:
namespace: 'server1' # 实例名
参数:
- job_name:指定服务名
- targets:指定服务地址和端口
- labels:自定义标签,如指定服务器名为 server1,方便后面发送告警信息时标记服务器。
用 prometheus 自带的 promtool 工具检查配置文件的有效性:
$ cd ~/prometheus/prometheus-2.19.1.linux-amd64
$ ./promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: 0 rule files found
正确显示如上,如果提示有错,请根据错误提示修改配置文件。
后台启动 Node Exporter 和 Prometheus Server
nohup ~/prometheus/node_exporter-1.0.1.linux-amd64/node_exporter &
nohup ~/prometheus/prometheus-2.19.1.linux-amd64/prometheus &
启动 http://localhost:9090 访问 Prometheus 的 UI 界面,输入 up 执行:
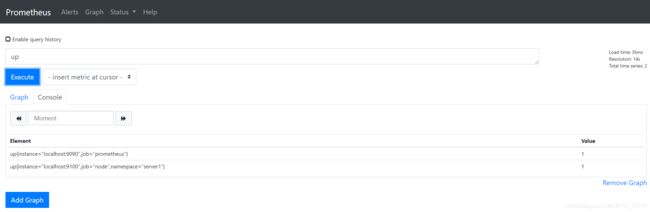
可以看到服务 prometheus 和 node 均已启动,1 表示正常,0 为异常。
3、使用 PromQL 查询监控数据
关于 PromQL 详细用法请参考:
https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/quickstart/prometheus-quick-start/promql_quickstart
https://prometheus.io/docs/prometheus/latest/querying/basics/
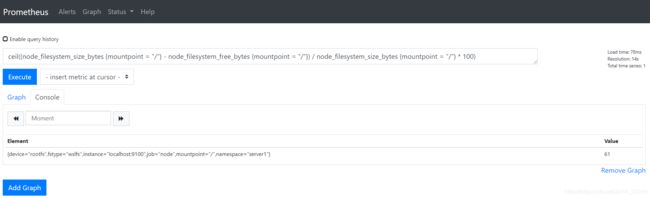
这里我们演示 CPU、内存和磁盘的查询,结果四舍五入:
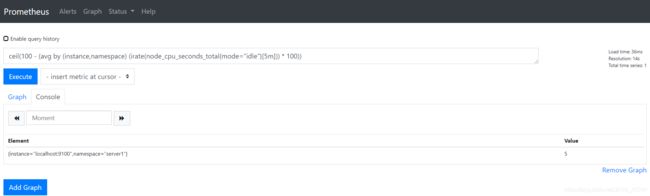
(1)CPU 5分钟的平均使用率
ceil((1-((sum(increase(node_cpu_seconds_total{mode="idle"}[5m])) by(instance,namespace)) / (sum(increase(node_cpu_seconds_total[5m])) by(instance,namespace))))*100)
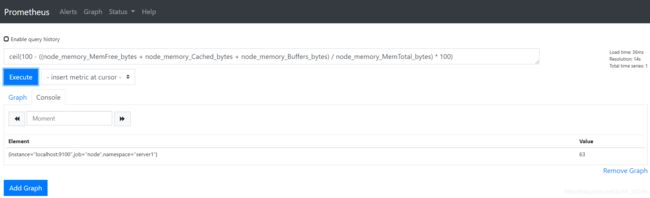
(2)内存使用率
ceil(100 - ((node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes) * 100)
(3)磁盘使用率
ceil((node_filesystem_size_bytes {mountpoint = "/"} - node_filesystem_free_bytes {mountpoint = "/"}) / node_filesystem_size_bytes {mountpoint = "/"} * 100)
四、使用 Alertmanager 发送警报
Prometheus Server 通过 Node Exporter 采集主机数据,当使用率超过阈值后,Prometheus Server 发送警告信息给 Alertmanager,Alertmanager 通过邮件、微信、钉钉、企业微信等通知管理员处理警报。
1、定义发送警报模板
$ cd ~/prometheus/alertmanager-0.21.0.linux-amd64
$ mkdir config
$ vim alarm.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
========告警详情========
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
========参考信息========
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例 ip: {{ $alert.Labels.instance }};{{- end -}}
{{- if gt (len $alert.Labels.namespace) 0 -}}<br>故障实例所在 namespace: {{ $alert.Labels.namespace }};{{- end -}}
{{- if gt (len $alert.Labels.node) 0 -}}故障物理机 ip: {{ $alert.Labels.node }};{{- end -}}
{{- if gt (len $alert.Labels.pod_name) 0 -}}故障 pod 名称: {{ $alert.Labels.pod_name }}{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
告警解除: {{ $alert.Labels.alertname }}
{{- end }}
========告警详情========
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
恢复时间: {{ $alert.EndsAt.Format "2006-01-02 15:04:05" }}
========参考信息========
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例 ip: {{ $alert.Labels.instance }};{{- end -}}
{{- if gt (len $alert.Labels.namespace) 0 -}}<br>故障实例所在 namespace: {{ $alert.Labels.namespace }};{{- end -}}
{{- if gt (len $alert.Labels.node) 0 -}}故障物理机 ip: {{ $alert.Labels.node }};{{- end -}}
{{- if gt (len $alert.Labels.pod_name) 0 -}}故障 pod 名称: {{ $alert.Labels.pod_name }};{{- end }}
{{- end }}
{{- end }}
{{- end }}
消息提示如下:

2、定义发送警报到企业微信
参考 企业微信API说明
$ vim ~/prometheus/alertmanager-0.21.0.linux-amd64/alertmanager.yml
global:
resolve_timeout: 10m
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
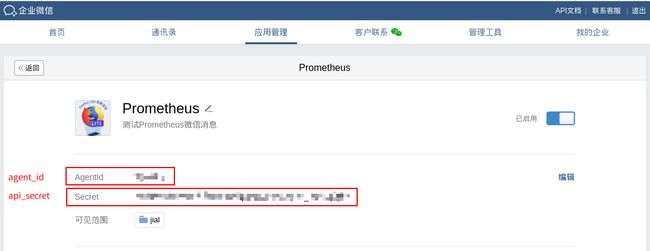
wechat_api_secret: '应用的secret,在应用的配置页面可以看到'
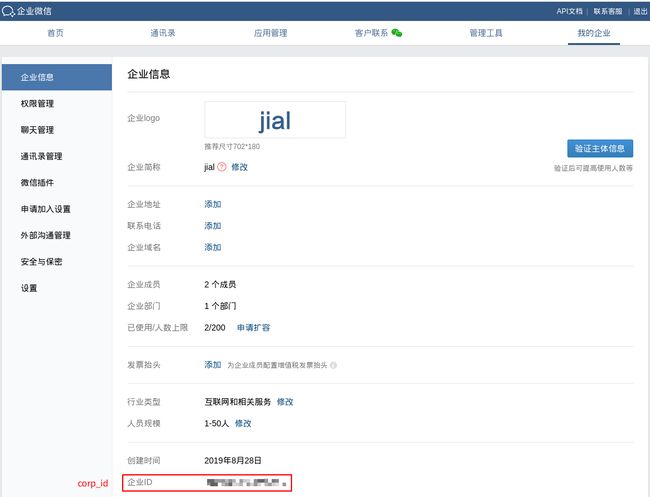
wechat_api_corp_id: '企业id,在企业的配置页面可以看到'
templates:
- '/etc/alertmanager/config/*.tmpl'
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'wechat'
inhibit_rules:
- source_match:
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: false
corp_id: '企业id,在企业的配置页面可以看到'
to_user: '@all'
to_party: ' PartyID1 | PartyID2 '
message: '{{ template "wechat.default.message" . }}'
agent_id: '应用的AgentId,在应用的配置页面可以看到'
api_secret: '应用的secret,在应用的配置页面可以看到'
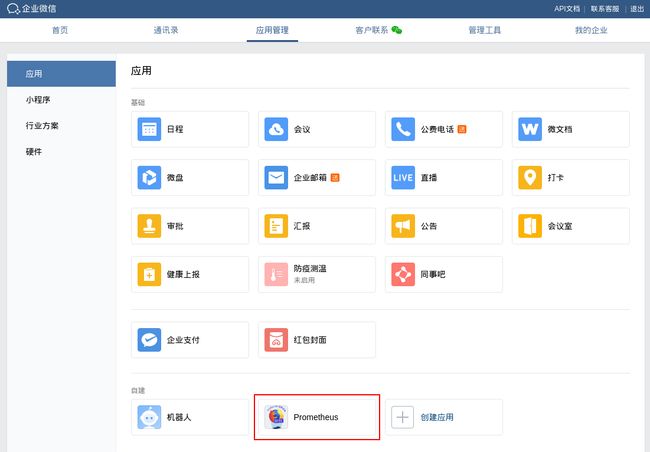
首先登录企业微信并创建应用:
其余对应信息如下所示:
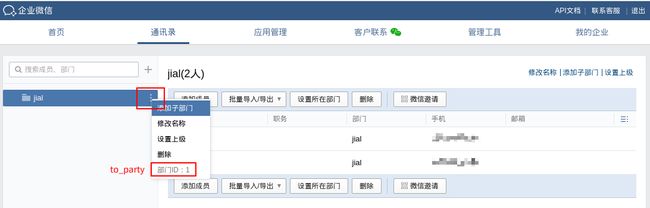
3、自定义 Prometheus 告警规则
cd ~/prometheus/prometheus-2.19.1.linux-amd64
mkdir rules
cd rules
vim hoststats-alert.rules
创建主机 CPU、内存和硬盘使用率报警
groups:
- name: hostStatsAlert
rules:
- alert: CPU 使用率
expr: ceil((1-((sum(increase(node_cpu_seconds_total{mode="idle"}[5m])) by(instance,namespace)) / (sum(increase(node_cpu_seconds_total[5m])) by(instance,namespace))))*100) > 90
for: 5m
labels:
severity: 严重警告
annotations:
summary: "{{ $labels.instance }} CPU 使用率过高!"
description: "{{ $labels.namespace }} CPU 使用率大于 80% (目前使用: {{ $value }}%)"
- alert: 内存使用率
expr: ceil(100 - ((node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes) / node_memory_MemTotal_bytes) * 100) > 80
for: 5m
labels:
severity: 严重警告
annotations:
summary: "{{ $labels.instance }} 内存使用率过高!"
description: "{{ $labels.namespace }} 内存使用率大于 80% (目前使用: {{ $value }}%)"
- alert: 磁盘使用率
expr: ceil((node_filesystem_size_bytes {mountpoint = "/"} - node_filesystem_free_bytes {mountpoint = "/"}) / node_filesystem_size_bytes {mountpoint = "/"} * 100) > 80
for: 5m
labels:
severity: 严重警告
annotations:
summary: "{{ $labels.instance }} 磁盘使用率过高!"
description: "{{ $labels.namespace }} 磁盘使用率大于 80% (目前使用: {{ $value }}%)"
- alert:告警规则的名称。
- expr:基于 PromQL 表达式告警触发条件,用于计算是否有时间序列满足该条件。
- for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为 pending。
- labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。
- annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations 的内容在告警产生时会一同作为参数发送到 Alertmanager。
- $labels:变量保存警报实例的标签键/值对
- $value:变量保存警报实例的评估值
4、配置 prometheus 启用 alertmanager 报警
$ vim ~/prometheus/prometheus-2.19.1.linux-amd64/prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*.rules"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']
labels:
namespace: 'server1' # 实例名