开头注释:针对这些问题,都是在tensorflow框架下,去寻找代码解决问题的。所以非tensorflow框架下编程的,可以看看出现该类问题的原因,以及解决问题的方向,具体的解决问题的代码需要自行查阅资料。
情况1:训练速度慢
针对实体链接任务,搭建了Bi-LSTM+CNN的模型,目前训练速度很慢,半个小时才出一个批次的预测结果。
类比于手写数字识别,无论是使用LSTM,还是CNN,都不会很慢,最慢的至少在10分钟内能出每一个批次的预测结果。
情况2:测试集准确率低
测试集准确率低,训练集准确率低----欠拟合
测试集准确率低,训练集准确率高----过拟合
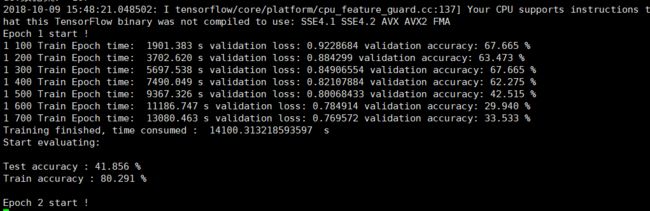
训练数据集很小,就导致了过拟合:测试集准确率远远跟不上训练集测试集 严重跟不上
过拟合解决方法:
1)早点停止梯度更新 2)给训练集增加更多的数据 3)正则化(l1正则和l2正则) 4)使用dropout方法
欠拟合解决方法:
1)改变激活函数{sigmoid易导致梯度消失,换用reul试试} 2)改变梯度下降策略
训练速度慢:
1.深度网络训练困难的原因:在深度网络中,不同的层学习的速度差异很大。尤其是,在网络中后面的层学习的情况很好的时候,先前的层次常常会在训练时停滞不变,基本上学不到东西。这种停滞并不是因为运气不好。而是,有着更加【@@!根本的原因是学习的速度下降了!@@】,这些原因【@@!与梯度的学习技术相关!@@】。实际上,我们发现在深度神经网络中使用基于梯度下降的学习方法本身存在着内在不稳定性。这种不稳定性使得先前或者后面的层的学习过程阻滞。【参考文章:原文】
不稳定的梯度问题:根本的问题其实并非是消失的梯度问题或者爆炸的梯度问题,而是在前面的层上的梯度是来自后面的层上项的乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景。唯一让所有层都接近相同的学习速度的方式是所有这些项的乘积都能得到一种平衡。如果没有某种机制或者更加本质的保证来达成平衡,那网络就很容易不稳定了。简而言之,真实的问题就是神经网络受限于不稳定梯度的问题。所以,如果我们使用标准的基于梯度的学习算法,在网络中的不同层会出现按照不同学习速度学习的情况。【参考文章:原文】
消失的梯度问题普遍存在:我们已经看到了在神经网络的前面的层中梯度可能会消失也可能会爆炸。实际上,在使用 sigmoid 神经元时,梯度通常会消失。为什么?【原文】
2.Batch Normalization---加速神经网络收敛
Batch Normalization 提出自《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》。其效果主要是加速网络收敛速度,并简化超参数的调节。【参考文章:原文】
Batch Normalization主要是为了解决internal covariate shift的问题。
什么是internal covariate shift问题呢?简单的说就是后一层要去处理前一层给的数据,而由于前一层的参数变化,后一层的输入分布会跟着变化,后一层的训练也要跟着分布的变化而变化。在深度神经网络中,往往有多层神经元,而前一层参数的变化会造成后层的剧烈变化。
可以想象,后一层好不容易把前一层给的数据训练的差不多了,前一层的参数一调,后面的神经元又得从头学习。这个过程很浪费时间,特别是在早期训练过程中。【参考文章:原文】
所以【@@!基本思想就是,能不能让每一层输入的分布不要剧烈变动?最好它是同分布的!@@】。如何让他们同分布呢?可以很容易想到利用normalization、白化这些方法来进行处理,就像我们对数据进行预处理一样。【参考文章:原文】
tensorflow中提供了三种BN方法: 理解起来和使用起来都比较复杂
· tf.nn.batch_normalization
·tf.layers.batch_normalization
·tf.contrib.layers.batch_norm
import tensorflow as tf
help(tf.layers.batch_normalization) # help中添加函数名
3. L1_regularizer与L2_regularizer正则化
通常,会将正则化的结果当作Loss函数的一部分,而正则计算的一般是权重w与偏置值b
例:Loss = cross_entropy + L(w)+L(b)
优化Loss函数,即是优化w,b张量中各元素的绝对值之和或者平方和。
而为什么要优化w,b的绝对值之和或者平方和呢。
简而言之,就是要降低模型的复杂度,防止过拟合。
可以这么简单理解模型复杂度,对于n维的张量,其中为零元素越多,或者元素值越小,那么其模型复杂度越小。反之亦然。【参考文章:原文】

怎么添加正则处理,参考文章:TensorFlow从0到1 - 16 - L2正则化对抗“过拟合”
主要语句:
W_2 = tf.Variable(tf.random_normal([784, 100]) / tf.sqrt(784.0))
W_3 = tf.Variable(tf.random_normal([100, 10]) / tf.sqrt(100.0))
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W_2)
tf.add_to_collection(tf.GraphKeys.WEIGHTS, W_3)
regularizer = tf.contrib.layers.l2_regularizer(scale=5.0/50000)
reg_term = tf.contrib.layers.apply_regularization(regularizer)
loss = (tf.reduce_mean( tf.nn.sigmoid_cross_entropy_with_logits(labels=y_, logits=z_3)) + reg_term)

前面是没有L2,在训练集上准确率非常高;后面是添加了L2,在训练集上准确率略有下降。