作为一个服务百万机器的日志采集 agent,Logtail 目前已经提供了包括日志切分、日志解析(完整正则、JSON、分隔符)、日志过滤在内的常见处理功能,能够应对绝大多数场景的处理需求。但有些时候,由于应用的历史原因或是本身业务日志的复杂性,单一功能可能无法满足所采集日志的处理需求,比如:
- 日志可能不再是单一格式,有可能同时由 JSON 或者分隔符日志组成。
- 日志格式可能也不固定,不同的业务逻辑所产生的日志具有不同的字段。
- ...
为此,Logtail 引入了 混合模式,一方面借助 Logtail 完善的事件机制来保证数据读取阶段的可靠性,另一方面,依赖于插件系统丰富的插件,来加强 Logtail 对复杂日志的处理能力。
Logtail 采集模式划分
从整体来看,Logtail 的采集模式可以划分为以下三种:
- 纯 Logtail 模式:提供文本日志的采集能力,比如 Nginx 日志、JSON 日志、分隔符日志等。
- 纯插件模式:作为文本日志采集的补充,提供对更丰富数据源的采集能力,包括 MySQL Binlog、JDBC Query、Syslog 等,同时还提供了一系列的插件来支撑采集后的数据处理。
- 混合模式:综合上述两者的能力,支持通过插件实现对文本日志的多样处理。
混合模式工作原理

如上图中间部分所示,纯 Logtail 的核心处理部分由日志切分(Splitter)和日志解析(Parser)组成,根据选择的日志采集模式,日志切分把读取的文件内容切割成为一条条日志(比如单行基于换行符、多行基于行首正则),然后交由日志解析从单条日志中提取字段。由此可见,日志的采集模式固定了处理行为,比如完整正则模式要求日志必须完全符合设置的正则表达式,否则会报错。这种基于采集模式的固定行为,拥有更好的性能,但牺牲了灵活性。
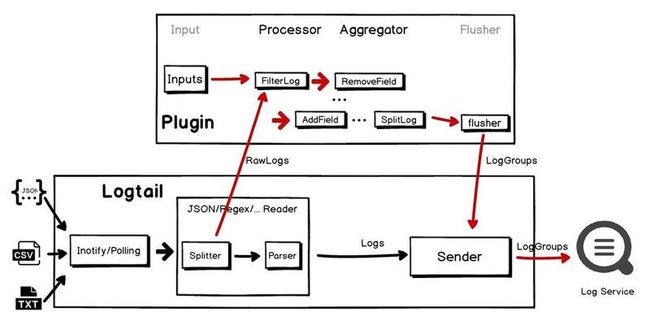
相比之下,混合模式则是牺牲一定的性能和计算资源来换取灵活性,以应对更为复杂的场景。如上图所示,在混合模式下,Logtail 会将日志切分的结果直接提交给插件进行处理,在后者中,我们可以组合多种处理插件,来满足我们的需求。
使用及限制说明
- 混合模式依旧依赖于 Logtail 完成日志切分,所以对于多行日志,依旧需要配置行首正则。
- 出于性能考虑,Logtail 提交给插件部分的数据并非是单条日志,而是日志的组合,因此插件处理配置的开始需要配置特定插件进行二次切分,具体下文将介绍。
- 性能开销:视配置而定,混合模式下 Logtail 会消耗更多的资源(主要是 CPU)来完成处理任务,因此需要根据实际情况调整 Logtail 的资源限制。如果采集节点的资源有限,但确实有处理需求,可以仍旧使用纯 Logtail 模式进行采集,之后使用数据加工来实现数据处理。
- Logtail 的版本需要在 0.16.28 及以上。
- 一些文本文件的功能在混合模式下无法使用,包括过滤器配置、上传原始日志、机器时区、丢弃解析失败日志、接受部分字段(分隔符模式)等,但其中部分功能可通过相关插件来实现。
插件处理配置语法
插件处理配置使用 JSON 对象进行表示,配置的 key 为 processors,value 是 JSON 对象的数组,数组内的每一个 JSON 对象表示一个处理插件的配置,处理时将按照数组内的定义顺序依次执行。数组内的每个 JSON 对象包含两个字段:type 和 detail,type 表示处理插件的类型(JSON string),detail 表示该插件的详细参数(JSON 对象,key 为参数名,value 为参数值)。
{
"processors": [
{
"type": "processor_regex",
"detail": {
"SourceKey": "content",
"Regex": "...",
"Keys": [
"time",
"short_msg",
"main_msg",
]
}
},
{
"type": "processor_regex",
"detail": {
"SourceKey": "main_msg",
"Regex": "...",
"Keys": [
...
]
}
}
]
}如上示例表示使用两个 processor_regex 插件进行日志处理,第一个插件根据配置的 Regex 参数对日志中的 content 字段进行正则提取,结果为 Keys 参数指定的三个字段,而第二个插件对上一步提取得到的 main_msg 字段再次进行正则提取,得到更多的字段。
支持的插件列表
以下是当前所支持的处理插件,关于具体插件如何使用可参考文档处理采集数据。
| 插件类型(type) | 功能 |
|---|---|
| processor_add_fields | 向日志中添加固定的一些字段 |
| processor_rename | 重命名指定字段名 |
| processor_drop | 根据字段名丢弃日志中的一些字段 |
| processor_drop_last_key | 当日志中存在指定的一些字段(名)时,丢弃特定字段,一般用于解析类型的处理插件后,当存在解析后的字段时,表示解析成功,可以丢弃原始字段 |
| processor_filter_key_regex | 判断字段名是否符合设置的正则表达式,进而决定是否保留该字段 |
| processor_filter_regex | 判断字段值是否符合设置的正则表达式,进而决定是否保留该字段 |
| processor_geoip | 对指定字段值(IP)进行地理位置分析,需要自行提供数据库 |
| processor_gotime | 对指定字段值使用 Go 语言的时间格式进行解析,可将解析结果设置为日志时间 |
| processor_strptime | 对指定字段值使用 strptime 的时间格式进行解析,可将解析结果设置为日志时间 |
| processor_md5 | 对指定字段值进行 MD5 |
| processor_base64_decoding | 对指定字段值进行 base64 解码 |
| processor_base64_encoding | 对指定字段值进行 base64 编码 |
| processor_anchor | 可以配置 anchor 指定 start/stop 子串,然后对指定字段值进行处理,提取 start/stop 子串之间的内容作为新字段 |
| processor_regex | 对指定字段值进行正则提取 |
| processor_json | 对指定字段值进行 JSON 解析,可将结果展开为日志内容 |
| processor_packjson | 将指定的多个字段以 JSON 对象的格式打包至一个目标字段 |
| processor_split_char | 对指定字段值进行单字符分隔符(支持设置引用符)解析 |
| processor_split_string | 对指定的字段值进行多字符分隔符解析 |
| processor_split_key_value | 对指定的字段值进行键值对解析,如飞天日志 |
| processor_split_log_regex | 对指定字段值使用行首正则表达式进行切分,结果将分裂为多条日志,一般用于混合模式下对接 Logtail 多行日志 |
| processor_split_log_string | 对指定字段值使用多字符进行切分,结果将分裂为多条日志,一般用于混合模式下对接 Logtail 单行日志(使用换行符作为分隔) |
使用特定插件完成日志的二次切分
前文的说明中曾经提到,出于性能考虑,Logtail 提交给插件部分的数据并非是单条日志,而是日志的组合,需要在插件处理配置的开始增加特定插件进行二次切分。
总的来说,切分时所需要考虑的情况有单行日志和多行日志两种,以下将分别介绍。
注意:此配置仅在混合模式下需要,如果使用的纯自定义插件的采集配置,可以忽略。
单行日志
假设单行日志的内容是 2019-09-23 14:08:16.952 [INFO] hello world,则 Logtail 提交给插件部分的数据内容可能是:
"content": "2019-09-23 14:08:16.952 [INFO] hello world\n2019-09-23 14:08:16.952 [INFO] hello world1\n2019-09-23 14:08:16.952 [INFO] hello world2"可以看到,多条单行日志被一次性输入到插件处理中,因此,我们需要配置一个针对单行日志的切分插件,即先前列表中最后的 processor_split_log_string。对于单行日志,可以直接复用如下配置:
{
"type": "processor_split_log_string",
"detail": {
"SplitKey": "content",
"SplitSep": "\n"
}
}多行日志
类似地,多行日志在提交给插件部分时也需要使用 processor_split_log_regex 进行基于行首正则的切分,配置如下(假设日志开头为常见的 [] 包裹时间):
{
"type": "processor_split_log_regex",
"detail": {
"SplitKey": "content",
"SplitRegex": "\\[\\d+-\\d+\\d+\\s\\d+:\\d+:\\d+\\].*"
}
}参考此配置时需要根据实际情况调整行首正则表达式(SplitRegex)。
混合模式使用步骤
- 根据日志是单行还是多行,确定插件处理配置中需要引入的切分插件及其配置,如果是多行,确认行首正则表达式。
- 根据日志的格式组合之前提及的处理插件,完善插件处理配置。
- 应用插件处理配置:两种途径,API/SDK 或控制台。
创建混合模式采集配置
从先前的介绍中可以看出,混合模式的采集配置实质上是文本模式的采集配置附加上额外的插件处理配置,因此,配置它的入口依旧是创建文本模式的采集配置:如果是单行日志,创建 极简模式 的采集配置,如果是多行日志,创建 完整正则模式 的采集配置,并切换至多行模式,设置行首正则表达式。
API/SDK
在完成文本模式的采集配置创建后,我们可以通过 API/SDK 的方式添加构建好的插件处理配置。此处,我们借助 CLI 来实现这个过程,代码如下:
# add_plugin_config.py
# -*- coding:utf-8 -*-
import commands
import json
import os
import sys
if len(sys.argv) != 4:
print 'Usage: add_plugin_config.py '
sys.exit(1)
your_project_name = sys.argv[1]
your_config_name = sys.argv[2]
your_plugin_config_file = sys.argv[3]
status, output = commands.getstatusoutput(
'aliyunlog log get_logtail_config --project_name={} --config_name={}'.format(your_project_name, your_config_name))
if status != 0:
print '[ERR] can not find specified config, please check your CLI configuration'
print 'ErrMsg:', output
sys.exit(1)
config = json.loads(output)
print config
plugin = json.load(open(your_plugin_config_file, 'r'))
config["inputDetail"]["plugin"] = plugin
with open('logtail_config.json', 'wb') as f:
f.write(json.dumps(config))
update_cmd = 'aliyunlog log update_logtail_config --project_name="{}" --config_detail="$(cat logtail_config.json)"'.format(your_project_name)
print update_cmd
print os.system(update_cmd) 确定你需要修改的配置所属的 project_name、config_name,把插件处理配置保存到任意文件(比如 plugin_config.json)后,调用脚本传入这三个参数即可。
控制台
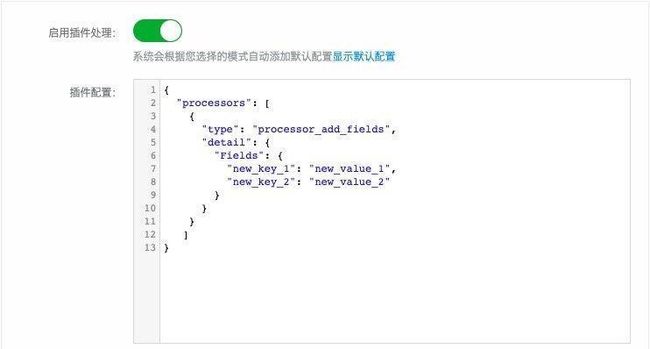
在 SLS 控制台上,我们可以通过 高级选项-启用插件处理 来启用混合模式。

在 API/SDK 的方式下,我们需要根据所选模式(JSON、分隔符等)来对二次切分的插件进行配置。而在控制台上使用混合模式时,页面将会根据所选的模式,自动地生成相应的默认配置,我们只需要配置针对单条日志的处理即可。通过 显示/隐藏默认配置,我们可以查看插件配置的完整内容。
以下示例在极简模式下使用 processor_add_fields 插件为每条日志增加两个固定的字段。从两张截图的区别可以发现,页面在默认配置中自动地填充了 processor_split_log_string 来实现按行二次切分。

示例
原始日志
假设我们所采集的是单行文本日志,原始日志内容如下:
"content": "2019-09-23 14:08:16.952 cip>->1.1.1.1_'_sip>->2.2.2.2_'_scheme>->http:POST_'_uri>->/v1/a/b/c_'_rt.all>->21_'_rt.p0>->19_'_\t{\"errcode\":10000,\"errmsg\":\"OK\",\"errdetail\":null,\"data\":{}}"该日志由 时间、多组键值对、JSON 对象 三部分组成,分别使用 空格 和 制表符 进行分隔,其中多组键值对部分使用 _'_ 分隔键值对,>-> 分隔键和值。
预期结果
为了方便分析,我们希望将日志的内容提取成如下的字段:
"time": "2019-09-23 14:08:16.952"
"cip": "1.1.1.1"
"sip": "2.2.2.2"
"scheme": "http:POST"
"uri": "/v1/a/b/c"
"rt.all": "21"
"rt.p0": "19"
"errcode": "10000"
"errmsg": "OK"
"errdetail": "null"插件处理配置
{
"processors": [
{
"type": "processor_split_log_string",
"detail": {
"SplitKey": "content"
}
},
{
"type": "processor_regex",
"detail": {
"SourceKey": "content",
"Regex": "(\\d+-\\d+-\\d+\\s\\d+:\\d+:\\d+\\.\\d+)\\s(.*)_'_\t(.*)",
"Keys": [
"time",
"main_msg",
"json_msg"
],
"NoKeyError": true,
"NoMatchError": true,
"KeepSource": true
}
},
{
"type": "processor_json",
"detail": {
"SourceKey": "json_msg",
"KeepSource": true
}
},
{
"type": "processor_split_key_value",
"detail": {
"SourceKey": "main_msg",
"Delimiter": "_'_",
"Separator": ">->",
"KeepSource": true
}
}
]
}如上是我们所创建的混合模式采集配置中的插件处理配置部分,由 4 个处理插件组成:
- processor_split_log_string:用于完成之前【使用特定插件完成日志的二次切分】提及的日志切分。
- processor_regex:将日志内容切分为三部分,三个字段分别为
time、main_msg、json_msg。 - processor_json:对上一步提取得到的
json_msg进行解析,将其中的内容展开为日志字段。 - processor_split_key_value:对
main_msg字段进行进一步的解析,将其中的各个键值对展开为日志字段。
更多阅读
本文作者:抱泽
本文为云栖社区原创内容,未经允许不得转载。