2018-09-26-Python面试题(转)
个人博客地址——https://www.dogebug.cn/
GitHub地址——https://github.com/yanshigou/
layout: post
title: Python基础面试题(转)
date: 2018-09-26 21:44:00
comments: true
subtitle:
author: “dzt”
tags: python
Python开发工程师面试题 整合版
转载自知乎:狗尾草的小确幸 https://zhuanlan.zhihu.com/p/42865842
不同的编程语言,干同一个活,编写的代码量,差距也很大:比如,完成同一个任务,C语言要写1000行代码,Java只需要写100行,而Python可能只要20行。所以Python是一种相当高级的语言。不知道大家当时学Python是因为什么,但学完Python的你,一定很希望找到一些对自己面试有帮助的资料,Python开发工程师面试题值得一看~
1.Python中__new__与__init__方法的区别
__new__:
触发时机: 在实例化对时触发
参数:至少一个cls 接收当前类
返回值:必须返回一个对象实例
作用:实例化对象
注意:实例化对象是Object类底层实现,其他类继承了Object的__new__才能够实现实例化对象。
__init__:
触发时机:初始化对象时触发(不是实例化触发,但是和实例化在一个操作中)
参数:至少有一个self,接收对象
返回值:无
作用:初始化对象的成员
注意:使用该方式初始化的成员都是直接写入对象当中,类中无法具有。
2.什么是匿名函数?
Lambda函数,不用担心函数名冲突,不过python对匿名函数支持有限,只有一些简单的情况下可以用
#声明一个简单的lambda表达式
mylamb = lambda x,y:x+y
#调用函数
result = mylamb(8,9)
print(result)
3.简要概述一下python中生成器和迭代器?
(1)迭代器:
迭代器协议:对象需要提供next()方法,它要么返回迭代中的下一项,要么就引起一个StopIteration异常,以终止迭代。
可迭代对象:实现了迭代器协议对象。list、tuple、dict都是Iterable(可迭代对象),但不是Iterator(迭代器对象)。但可以使用内建函数iter(),把这些都变成Iterable(可迭代器对象)。
for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,遇到StopIteration的异常后循环结束。
(2)生成器:
将列表生成式中[]改变为()数据结构会改变,从列表变为生成器;
列表受内存限制,所以没有必要创建完整的列表(节省大量内存空间),在python中我们可以采用生成器:边循环边计算的机制;
生成器是只能遍历一次的。生成器是一类特殊的迭代器。还能使用 def 定义函数,但是,使用yield而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次从它离开的地方继续执行。
4.Python的垃圾回收机制(garbage collection)
(1)当gc模块的计数器达到阈值,垃圾自动回收
(2)当调用gc.collect(),垃圾收到回收
(3)程序退出的时候,python解释器来回收垃圾
5.函数装饰器的作用?
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
6.进程、线程的区别?
(1)定义的不同
进程是系统进行资源分配和调度的一个独立单位。
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
(2)区别
一个程序至少有一个进程,一个进程至少有一个线程。
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
线线程不能够独立执行,必须依存在进程中。
(3)优缺点
线程和进程在使用上各有优缺点:
线程执行开销小,但不利于资源的管理和保护;而进程正相反。
7.函数的闭包
闭包就是函数式编程的重要语法结构,提高了代码可重复实用性。使用特定或特殊的方式,将局部变量(内部函数)引入到全局环境中使用,这就是闭包操作。
8.Python里的拷贝
Copy浅拷贝,只拷贝父元素,deepcopy深拷贝,递归拷贝可变对象的所有元素
9.apache和nginx的区别
(1)nginx 相对 apache 的优点:
轻量级,同样起web 服务,比apache 占用更少的内存及资源
抗并发,nginx 处理请求是异步非阻塞的,支持更多的并发连接,而apache 则是阻塞型的,在高并发下nginx 能保持低资源低消耗高性能
配置简洁
高度模块化的设计,编写模块相对简单
社区活跃
(2)apache 相对nginx 的优点:
rewrite ,比nginx 的rewrite 强大;
模块超多,基本想到的都可以找到;
少bug ,nginx 的bug 相对较多;
超稳定。
10.什么是事务?
事务(Transaction)是并发控制的基本单位。所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。例如,银行转帐工作:
从一个帐号扣款并使另一个帐号增款,这两个操作要么都执行,要么都不执行。所以,应该把他们看成一个事务。事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性。
事务四大特性:
原子性:事务中的全部操作在数据库中是不可分割的,要么全部完成,要么均不执行;
一致性:几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致;
隔离性:事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的;
持久性:对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
11. 主键和外键的区别?
主键在本表中是唯一的、不可唯空的,外键可以重复可以唯空;外键和另一张表的主键关联,不能创建对应表中不存在的外键。
12. 在数据库中查询语句速度很慢,如何优化?
(1)建索引 ;
(2)减少表之间的关联 ;
(3)优化sql,尽量让sql很快定位数据,不要让sql做全表查询,应该走索引,把数据 量大的表排在前面 ;
(4)简化查询字段,没用的字段不要,已经对返回结果的控制,尽量返回少量数据 ;
(5)数据库做好读写分离。
13. Oracle和Mysql的区别?
1)库函数不同。
2)Oracle是用表空间来管理的,Mysql不是。
3)显示当前所有的表、用户、改变连接用户、显示当前连接用户、执行外部脚本的语句的不同。
4)分页查询时候时候不同 。
5)sql的语法的不同。
14.tcp和udp的区别?
tcp是一种面向连接的、可靠的、基于字节流的传输层通信协议。是专门为了在不可靠的互联网络上提供一个可靠的端到端字节流而设计的,面向字节流。
udp(用户数据报协议)是iso参考模型中一种无连接的传输层协议,提供面向操作的简单不可靠的非连接传输层服务,面向报文。
它们之间的区别:
1、tcp是基于连接的,安全性高;udp是基于无连接的,安全性较低;
2、由于tcp是连接的通信,需要有三次握手、重新确认等连接过程,会有延时,实时性差;同时过程复杂,也使其易于被攻击;而udp无连接,无建立连接的过程,因而实时性较强,也稍安全;
3、tcp连接是点到点的电话接通通信;udp支持一对一、一对多、多对一、多对多的广播通信。
15.对if __name__ == '__main__'的理解?
“ if __name__ == ‘__main__’:”
在Python中分为两类:一种是直接执行,另外一种是作为模块时才被调用。
__name__ 作为模块的内置属性,即".py"文件的调用方式。如果等于“__main__"就直接执行本文件,如果是别的就是作为模块被调用。
16. http协议与https协议的区别?
http是超文本传输协议在互联网上应用最为广泛的一种网络协议,所有www文件都必须遵守这个标准,基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)连接。
https是超文本传输安全协议,是一种网络安全传输协议。http协议传输的数据都没有加密,一些私密的信息不安全,https经由超文本传输协议(http)进行通信,利用SSL/TLS来加密数据包,https开发的主要目的就是为了保护数据传输的安全性。
HTTPS和HTTP的区别:
1) https协议要申请证书到ca,需要一定经济成本
2) http是明文传输,https是加密的安全传输
3) 连接的端口不一样,http是80,https是443
4)http连接很简单,没有状态;https是ssl加密的传输,身份认证的网络协议,相对http传输比较安全。
17. Python解释器
当我们编写好了的Python代码的时,一.py为扩展名的文件,运行代码的时候,需要python解释器。解释器在执行的程序时,一条一条的解释成机器语言给计算机来执行。因为计算机只能识别机器语言(以二进制的形式)
18. 字典推导式和列表推导式
列表推导式:
格式:[变量 for 变量 in 列表]
普通的字典内涵
变量= {key:value for key,value in 字典.items()}
19.Python2和python3在使用super时区别:

20.python 列表去重(数组)的几种方法
方法1:用if语句判断,用append函数追加

输出结果为:
![]()
方法二:
用set集合:

输出结果为:

21. 列举您使用过的python网络爬虫所用到的解析数据包
BeautifulSoup、pyquery、Xpath、lxml
22.python常用内置函数:
dir(对象名):返回一个列表,列出该对象所有的属性和方法;
help(函数名、方法名或对象):查看函数、方法或对象的帮助文档;
type(对象名):查看该对象的类型;
isinstance(对象, 类型):判断该对象是否是该类型,返回True或False;
range、input、print就不用多说了。
以上几个使用频率应当是最高的。更多函数,请导入模块”import builtins”,dir(builtins)查看。
23. python中的and、or、not逻辑运算符:
and、or、not两边的值会被放到布尔环境下,作比较
and运算如x and y:
x和y都为True时,那么返回最后一个值y
否则返回两个值中的第一个布尔值为假的值,从左往右运算
or运算如x or y:
只要有一个为真值,就返回第一个布尔值为真的值
如果都为假,返回最后一个布尔值为假的值,从左往右运算
not运算如not x:
当x的布尔值为True,返回False
当x的布尔值为False,返回True
24.参数按值传递和引用传递是怎样实现的?
Python中的一切都是类,所有的变量都是一个对象的引用。引用的值是由函数确定的,因此无法被改变。但是如果一个对象是可以被修改的,你可以改动对象。
25. python内置的数据类型有哪些?
list: 链表, 有序的项目, 通过索引进行查找, 使用方括号"[]"
dict: 字典, 字典是一组键(key)和值(value)的组合, 通过键(key)进行查找, 没有顺序, 使用大括号"{}"
str:字符串,用单或双引号括起来表示字符串
tuple: 元组, 元组将多样的对象集合到一起, 不能修改, 通过索引进行查找, 使用括号"()"
set: 集合,无序, 元素只出现一次, 使用"set([])",可实现列表快速去重,不过注意返回的是一个集合
int: 整数,如3
float:浮点数,如2.3
complex:复数,如complex(1,2) => 1+2j
可迭代(遍历)对象:list、dict、tuple、set、str
可变类型:list、dict、set,其余为不可变类型
list、tuple、str可通过索引获取当中的元素
set不支持索引查找,因为数据只出现一次, 它只关心数据是否出现, 不关心其位置。
26.python中search()和match()的区别
match从起始位置开始往后查找,返回第一个符合规则的
search任何位置开始往后查找,返回第一个符合规则的
27.redis中常用的5种数据类型?
Redis支持5种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
28.请描述一下try……except……else……finally执行的顺序?
try:
#尝试实现某个操作,
#如果没出现异常,任务就可以完成
#如果出现异常,将异常从当前代码块扔出去尝试解决异常
except 异常类型1:
#解决方案1:用于尝试在此处处理异常解决问题
except 异常类型2:
#解决方案2:用于尝试在此处处理异常解决问题
else:
#如果没有出现任何异常,将会执行此处代码
finally:
#管你有没有异常都要执行的代码
29.什么样的字段适合建立索引?
唯一、不为空、经常被查询的字段。
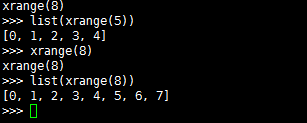
30. Xrange和range的区别是什么?
xrange用法与 range 完全相同。不同的是,xrange生成的不是一个list对象,而是一个生成器。

个人博客地址——https://www.dogebug.cn/
GitHub地址——https://github.com/yanshigou/
禁止不留原创地址、署名的转载
本人保留所有法定权利。违者必究