最佳实践概述
应用场景
客户在IDC或者公有云环境自建Hadoop集群,数据集中保存在HDFS文件系统,同时借助Hive进行常见的ETL任务。客户在决策上云之后,会将自建Hadoop集群的数据迁移到阿里云自建Hadoop或者EMR。
技术架构
本实践方案基于如下图所示的技术架构和主要流程编写操作步骤。

方案优势
- 易用性
您可以简单选择所需ECS机型(CPU、内存)与磁盘,并选择所需的软件,进行自动化部署。 - 经济性
您可以按需创建集群,即离线作业运行结束就可以释放集群,还可以在需要时动态地增加节点。 - 深度整合
E-MapReduce与阿里云其它产品(例如,OSS、MNS、RDS 和 MaxCompute 等)进行了深度整合,支持以这些产品作为Hadoop/Spark计算引擎的输入源或者输出目的地。 - 安全
E-MapReduce整合了阿里云RAM资源权限管理系统,通过主子账号对服务权限进行隔离。 - 可靠性
使用阿里云数据库RDS保存Hive的元数据信息,可以提升数据可靠性和服务可用性,免除客户运维自建MySQL数据库的工作。
前置条件
在进行本文操作之前,您需要完成以下准备工作:
- 注册阿里云账号,并完成实名认证。您可以登录阿里云控制台,并前往实名认证页面查看是否已经完成实名认证。
- 阿里云账户余额大于100元。您可以登录阿里云控制台,并前往账户总览页面查看账户余额。
- 拥有已经通过备案的域名。
- 开通ECS、OSS、EMR、RDS、DTS和VPN网关等服务。
资源规划说明
- 本方案仅作为实践演练使用,在生产环境中执行时请结合业务系统实际架构进行
调整。 - 本方案购买的所有云产品规格均为演示需要,请根据实际业务需求购买对应规格
的产品和服务。 - 本方案重在展示迁移思路和方法,线下IDC的模拟环境以组件配置呈现。
1. 基础环境搭建
本实践方案中,将按照技术架构图搭建相对完整的实践环境,包括Apache日志发生
器、Kafka队列、Hadoop集群、Hive+MySQL元数据库。

1.1. 搭建Hadoop + Kafka + 日志发生器环境
请参考《自建Hadoop数据迁移到阿里云EMR》最佳实践
第1章:1. 自建Hadoop集群环境搭建,完成本实践方案的基础环境搭建。
1.2. 创建Hive元数据库
本实践方案将在ECS上安装MySQL数据库,用于保存Hive元数据信息。
步骤1登录云服务器控制台,地域:华东2(上海)。
步骤2在实例列表页面,单击右上角的创建实例。

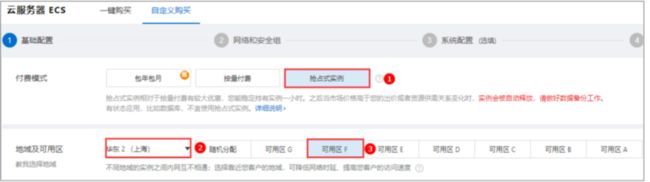
步骤3 在自定义购买模式下,完成各项配置。
基础配置:
- 付费模式:本实践方案选用抢占式实例。
说明:在方案演示过程中,我们选用抢占式实例来降低您的成本;在实际商用环境中,请选择适合业务场景的ECS实例付费模式。抢占式实例的具体信息, - 地域及可用区:华东2(上海) 可用区F
- 实例
ᅳ 实例规格:ecs.g6.large(2 vCPU 8 GiB,通用型g6)
ᅳ 单台实例规格上限价:创建抢占式实例,必须设置单台实例规格的价格上限。
a) 选择设置单台上限价。
b) 单击查看历史价格。
c) 在抢占式实例历史价格走势图中,可以看到华东2可用区F的实例当前市场价格为0.034 ¥/实例/小时,因此,我们设置单台上限价为0.04 ¥/实例/小时,要求略高于当前市场价格。使用者在进行实际操作时,请以界面显示的实时价格为准。
- 购买实例数量:1台



- 镜像:
a) 选择镜像市场。
b) 单击从镜像市场获取更多选择(含操作系统)。
c) 输入magento,并单击搜索。
d) 选择Magento开源电子商务系统(LAMP | 含演示数据),并单击使用,该镜像中包含了MySQL数据库,root用户的默认密码为123456



- 存储:系统盘
高效云盘 80GiB

步骤4 配置完成,单击下一步:网络和安全组。
步骤5 在网络和安全组页面,参考下表,配置相关参数。
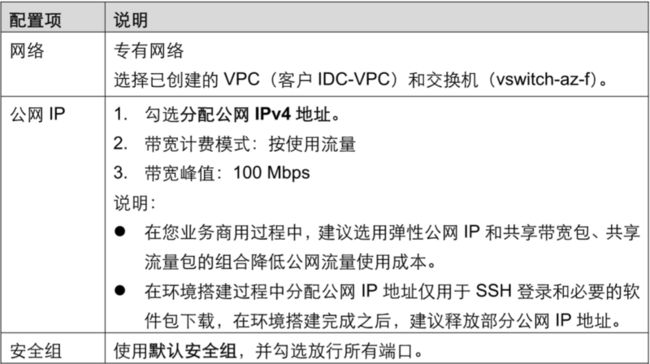
配置完成,单击下一步:系统配置。

步骤6 在系统配置页面,参考下表,配置相关参数。


配置完成,单击确认订单。
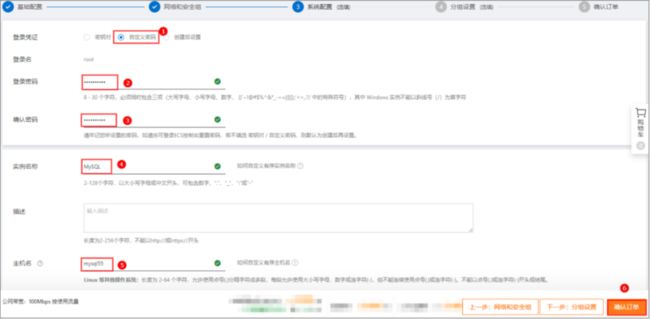
步骤7 在确认订单页面,确认各项参数信息。确认无误,阅读、同意并勾选《云服务器ECS服务条款》和《镜像商品使用条款》,并单击创建实例。

步骤8 创建任务提交成功后,单击管理控制台前往ECS实例列表页面查看详情。
至此,本实践方案中用于模拟客户自建Hadoop系统的ECS已经全部搭建完成,如下图所示:

步骤9 通过如下网址登录到MySQL控制台:
http://mysql所在ecs的公网ip地址/phpmyadmin

步骤10创建账号,该账号用于Hive进行连接。

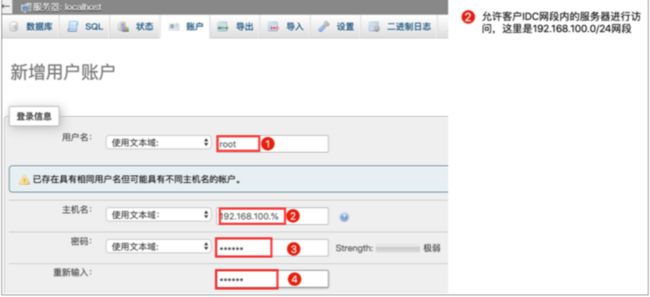

完成后界面显示如下图所示:
1.3. 安装并配置Hive
在本实践方案中,采用Hive 1.2.2版本作为源版本。
步骤1 通过SSH登录到hadoop-master节点,执行以下命令下载并解压Hive软件包。
cd ~
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-1.2.2\
/apache-hive-1.2.2-bin.tar.gz
tar -zxf apache-hive-1.2.2-bin.tar.gz -C /usr/local/步骤2配置环境变量。
vim /etc/profile
1、在文件末尾添加如下内容,保存并退出。
# Added for Hive
export HIVE_HOME=/usr/local/apache-hive-1.2.2-bin
export PATH=$PATH:$HIVE_HOME/bin
2、执行以下命令使文件生效。
source /etc/profile
3、查看Hive版本号。
hive --version
步骤3 生成hive-site.xml配置文件。
cd /usr/local/apache-hive-1.2.2-bin/conf
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
- 搜索javax.jdo.option.ConnectionUserName,将value修改为root。
- 搜索javax.jdo.option.ConnectionPassword,将value修改为123456,该密码为章节1.2使用的云市场镜像中数据库root用户的默认密码。
- 搜索javax.jdo.option.ConnectionURL,将value修改为
jdbc:mysql://192.168.100.140:3306/hive122db?createDatabaseIfNotExist=true
说明:
(1) 将红色字体的192.168.100.140替换为您环境中MySQL的VPC IP地址。
(2) hive122db为MySQL中的数据库,用于保存Hive的元数据。
- 搜索javax.jdo.option.ConnectionDriverName,将value修改为 com.mysql.jdbc.Driver
- 在下图所示的位置添加配置,即作为最靠前的
system:java.io.tmpdir
/usr/local/apache-hive-1.2.2-bin/tmp
system:user.name
root

步骤4生成并配置hive-env.sh启动文件。
cd /usr/local/apache-hive-1.2.2-bin/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh在文件末尾添加如下内容,保存后退出:
export HIVE_AUX_JARS_PATH=/usr/local/apache-hive-1.2.2-bin/lib步骤5 下载MySQL驱动程序。
cd /usr/local/apache-hive-1.2.2-bin/lib- 通过下面命令下载MySQL Connector库文件
wget
https://maven.aliyun.com/repository/central/mysql/\
mysql-connector-java/8.0.18/mysql-connector-java-8.0.18.jar步骤6 初始化源数据库。
cd /usr/local/apache-hive-1.2.2-bin/bin
./schematool -dbType mysql -initSchema -verbose当界面出现下图所示信息时表示初始化完成。

步骤7 启动Hive进入HQL命令行交互界面。
hive

说明:在hive命令行界面,使用quit退出。
因篇幅原因,余下内容请点击此处阅读
本文作者:开源大数据EMR
本文为阿里云内容,未经允许不得转载。