基于kNN的文本分类原理以及实现
前两天写了 基于libsvm中文文本分类 ,只是做到了会用的,要做到知其然知其所以然还是很难的。不过SVM的应用很广泛,除了文本分类,比如人脸识别,手写识别,甚至验证码识别都可以搞定。
kNN(k最邻近)算法相对而言,就简单得多了。
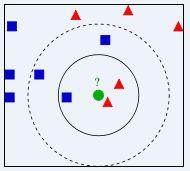
1,kNN算法就是找到k个最相似的样本,这些样本所在的类,就是当前文档的所属的类。如下图:绿色圆圈表示你想分类的文本,其他是已知类别的样本。图中其他形状和绿色圆圈的距离代表了相似度。如果k = 3,就是取3个最相似的文本,那么1个蓝色框,2红色三角被选中,因为红色三角多,则绿色圆圈所属的类就是红色三角所在的类。如果k = 5,3个蓝色框和2个红色三角选中,那么就属于蓝色框所属于的类。kNN你也可以取多个类别,就是绿色圆圈既属于蓝色框,也属于红色三角所属的类别。
2,如何计算文章的相似度?建议先看看《数学之美-余弦定理和新闻分类 》。首先必须对文档分词,对于所有出现的词叫做特征。每个特征必须有一定的值,这个值是根据某些公式计算出来的比如TF/IDF。比如文档x表示为(f1:x1,f2:x2,......,fn:xn)文档y表示为(f1:y1,f2:y2,......,fn:yn)。
x1...xn以及y1...yn都是通过比如TF/IDF公式计算出来的(你也可以用别的公式)。f1...fn就是特征,如果特征从0....n已经选择好了,那么fn可以省略,写作x (x1,x2,......,xn),y写作(y1,y2,......,yn)。
如上图,如果x和y的夹角小,则相似度高,夹角大,则相似度小,那么计算余弦cos(xy)就可以,越接近1,越相似,还有一种方法时计算内积,就是夹角间的面积,有兴趣的同学可以试试。计算cos的公式为:
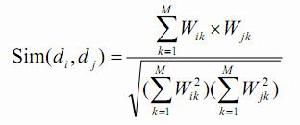
上面公式很好理解,把数据的代入,就等同下面的公式:
3,第2步是计算两个文本之间的相似度,剩下的计算很简单,计算和所有样本的相似度。然后根据sim的值按照从高到低排序。k 等于几,就取前几个。下面有是一个公式,看起来很麻烦,理解很容易:就是k个邻居中,属于哪个类别的多,x就属于哪个类。
![]()
4,实现。实现请参考基于libsvm中文文本分类 中的,分词部分,特征提取部分,向量值计算部分,训练样本和测试样本部分。kNN的实现代码如下:
def sim(feature,di1,di2): b = 0.0 c1 = 0.0 c2 = 0.0 for index,term in feature: #feature保存所有特征字典 x = di1.get(index) #获取对应特征的值,可能没有,如果没有x=0 if not x: x = 0 y = di2.get(index) if not y: y = 0 b += x * y c1 += math.pow(x,2) c2 += math.pow(y,2) sim = b / math.sqrt(c1* c2) #cos值 return sim def classify(k,feature,trainli,di,cls): ''' k:k的值 feature:特征字典 trainli:样本的列表 di:分类文档的特征列表 cls:分类文档的类别 ''' li = list() i = 0 for cls,traindi in trainli: s = sim(feature,traindi,di) li.append((s,cls)) li.sort(reverse = True) #排序 tmpli = li[0:k] #取前k个 print tmpli di = dict() for l in tmpli: s,cls = l times = di.get(cls) if not times: times = 0 di[cls] = times + 1 #统计属于类别的文档数 sortli = sorted(di.iteritems(),None,lambda d:d[1],True) #排序取文档数最多的类 print cls,sortli tocls = sortli[0][0] #分出来的类别 return cls == tocls
5,总结。kNN的分类方法因为没有训练过程,所以,分类时特别慢,因为需要和所有样本进行比较,同时特征维数很多,也要影响效率。分类准确度还可以,基本和没有优化过的svm差不多,70%多。kNN的准确度和样本数量还是蛮相关的,我用每个类下的100个样本和200个样本,准确度差了9%左右。kNN因为效率的问题,所以在实际中应用还需要慎重。