Linux下Hadoop2.6的安装
linux:安装流程:
1、安装JDK,要求是jdk1.6及其以上的版本:
-
以jdk-8u40-linux-x64.gz为例,在你的java下载目录下
sudo tar -zxvf jdk-8u40-linux-x64.gz
sudo mv hadoop-2.6.0 /usr/local/jdk1.8.0_40
然后
sudo gedit /etc/profile
在最后面添加
export JAVA_HOME=/usr/local/jdk1.8.0_40
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
第一行代码目的是加环境变量,可以用JAVA_HOME代替/usr/local/jdk1.8.0_40这个地址,后面就可以少写一点。
第二行代码目的是,为了方便运行java程序,这样涉及到程序软件要调用java时,只需要用java -arg 就可以,而不用找java的路径。
第三行代码的目的是,当需要用到jar的包时,系统会自动从classpath的路径里寻找加载
然后
source /etc/profile重新编译一遍profile就安装好了java。可输入
java -version
来测试
2、安装sshsudo apt-get install ssh
ssh-keygen -t rsa
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):[回车] Enter passphrase (empty for no passphrase):[回车] Enter same passphrase again:[回车] Your identification has been saved in /home/test/.ssh/id_rsa. Your public key has been saved in /home/test/.ssh/id_rsa.pub. The key fingerprint is: e4:37:20:54:19:26:d0:39:34:b3:79:cb:00:6b:c9:e5 test@master The key's randomart image is: +--[ RSA 2048]----+ | o+Bo+o | | . B+B. | | = E.+ | | . B o | | S o | | . . | | | | | | | +-----------------+cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
安装ssh的主要目的是因为登陆远程主机会用ssh协议。
第一行代码是自己创建了一对密钥,分别为id_dsa和id_dsa.pub。存放公钥的文件名与私钥类是,但是以“.pub”作为后缀,例如~/.ssh/id_dsa.pub。
第二行代码是把公钥传递给自己的公钥目录。
3、配置hadoop2.6
sudo tar -zxvf hadoop-2.6.0.tar.gz
sudo mv hadoop-2.6.0 /usr/local/hadoop
sudo chmod -R 777 /usr/local/hadoop
然后
sudo gedit /etc/profile
在后面加入
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
4、修改Hadoop配置文件
1)、修改hadoop=env.sh
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
将JAVA_HOME的值改为/usr/local/jdk1.8.0_40
2)、core-site.xml(Hadoop Core的配置项,例如HDFS和MapReduce常用的I/O设置等)
hadoop.tmp.dir
/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
mapred.job.tracker
localhost:9001
mapreduce.framework.name
yarn
yarn.nodemanager.aux-services
mapreduce_shuffle
5、添加主节点和从节点dfs.replication 1 dfs.namenode.name.dir file:/usr/local/hadoop/dfs/name dfs.datanode.data.dir file:/usr/local/hadoop/dfs/data //这个属性节点是为了防止后面eclopse存在拒绝读写设置的 dfs.permissions false
sudo gedit /usr/local/hadoop/etc/hadoop/masters 添加:localhost
sudo gedit /usr/local/hadoop/etc/hadoop/slaves 添加:localhost
6、创建好临时目录和datanode与namenode的目录
cd /usr/local/hadoop mkdir tmp dfs dfs/name dfs/data7、 格式化namenode的namespace和dataspace
bin/hdfs namenode -formatbin/hdfs namenode -format成功的话,最后的提示如下,Exitting with status 0 表示成功,Exitting with status 1: 则是出错。
8、启动hadoop集群
sbin/start-dfs.sh
sbin/start-yarn.sh
尽量不要用start-all.sh,以为hadoop作者发现这个脚本可能有点问题。9、访问hadoop的web页面,验证hadoop集群是否成功搭建完成
http://ubuntu:50030 可以查看JobTracker的运行状态:
http://ubuntu:50070 可以查看NameNode及整个分布式文件系统的状态等:
http://localhost:8088 查看all application的信息
或者使用jps命令看相应进程
10、测试
然后输入以下代码可以来测试
bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/bin/hdfs dfs -put etc/hadoop input bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+' bin/hdfs dfs -cat output/*
正常情况下会有wordcount的输出结果
11、配置eclipse
- 把hadoop-eclipse-plugin-2.6.0.jar复制到eclipse插件目录,重启eclipse
- 配置 hadoop 安装目录
window ->preference -> hadoop Map/Reduce -> Hadoop installation directory
- 配置Map/Reduce 视图
window ->Open Perspective -> other->Map/Reduce -> 点击“OK”
windows → show view → other->Map/Reduce Locations-> 点击“OK”
- 控制台会多出一个“Map/Reduce Locations”的Tab页
在“Map/Reduce Locations” Tab页 点击图标<大象+>或者在空白的地方右键,选择“New Hadoop location…”,弹出对话框“New hadoop location…”,配置如下内容:将ha1改为自己的hadoop用户

注意:MR Master和DFS Master配置必须和mapred-site.xml和core-site.xml等配置文件一致。
打开Project Explorer,查看HDFS文件系统。
- 新建Map/Reduce任务
编写WordCount类:记得先把服务都起来File->New->project->Map/Reduce Project->Next
/**
*
*/
package com.zongtui;
/**
* ClassName: WordCount
* Function: TODO ADD FUNCTION.
* date: Jun 28, 2015 5:34:18 AM
*
* @author zhangfeng
* @version
* @since JDK 1.7
*/
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCount {
public static class Map extends MapReduceBase implements
Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector output, Reporter reporter)
throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements
Reducer {
public void reduce(Text key, Iterator values,
OutputCollector output, Reporter reporter)
throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
} 
将程序放在hadoop集群上运行:右键-->Runas -->Run on Hadoop,最终的输出结果会在HDFS相应的文件夹下显示。至此,ubuntu下hadoop-2.6.0 eclipse插件配置完成。
HDFS启动时如何使用SSH协议? 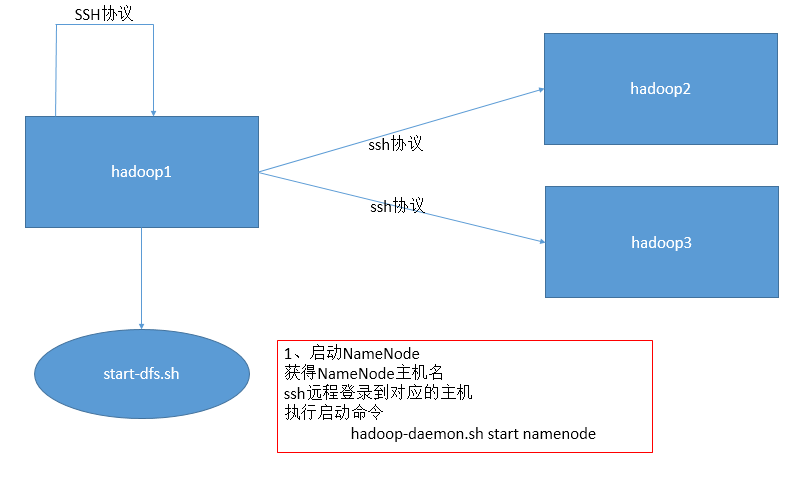
三种启动方式的关系 