字符串作业(四)
「BJOI2020」封印
给出只包含小写字母 a a a, b b b的两个字符串 s s s, t t t, q q q次询问,每次询问 s [ l . . . r ] s[l...r] s[l...r]和 t t t的最长公共子串长度。
建出 t t t的后缀自动机后在自动机上跑 s s s串得到对于每个 s s s的前缀在 t t t中匹配的最长长度 p i p_i pi,然后对于 s [ l . . . r ] s[l...r] s[l...r],二分答案 m i d mid mid,检查是否有 max i = l + m i d − 1 r p i ≥ m i d \max_{i=l+mid-1}^rp_i \geq mid maxi=l+mid−1rpi≥mid即可。
A C C o d e \mathcal AC \ Code AC Code
#includeLOJ #6537. 毒瘤题加强版再加强版
三倍经验
具体来说就是利用异或的性质,所有数异或起来等于出现奇数次的数的异或和。
如果我们要得到单独一个数字,就 h a s h hash hash一下,具体来说我们只统计 m o d p = i \bmod p = i modp=i的数的异或和。
那么多用几个 p p p,统计出来出现次数多的数就很有可能是单独一个数字的异或和,反之多个数字的异或和很难在多个不同的 p p p下都一起满足条件。
A C C o d e \mathcal AC \ Code AC Code
#includeCF963D Frequency of String
给出 S S S, Q Q Q次询问 S S S中最短的子串 t t t的长度使得字符串 m m m在 t t t中出现了 k k k次。
所有询问m互不相同。
可以想到求出后缀自动机的 r i g h t right right集合 S S S后 O ( ∣ S ∣ ) O(|S|) O(∣S∣)回答一次询问。
然后就这样写,然后就可以过。
因为所有询问 m m m互不相同,又因为对于所有长度为 k k k的串他们的 r i g h t right right集合大小之和为 O ( n ) O(n) O(n)。
串不相同代表着只有 O ( n ) O(\sqrt n) O(n)种不同的长度,所以所有询问的复杂度为 O ( n n ) O(n\sqrt n) O(nn)
事实上因为我们只需要 m m m的 r i g h t right right集合,所以可以不用写后缀树上启发式合并,直接离线求出所有 m m m的 A C AC AC自动机,拿 s s s在自动机上跑,对于 s s s的前缀所在的节点我们需要更新所有它的后缀的 m m m的 r i g h t right right集合,新开一个数组 f a fa fa表示沿着 f a i l fail fail链跑下一个是 m m m中的一个的节点,因为 r i g h t right right集合大小是 O ( n n ) O(n \sqrt n) O(nn),每次暴力爬 f a fa fa也是 O ( n n ) O(n \sqrt n) O(nn)的。
来了来了,对于这种屑题,肯定是要写 b i t s e t bitset bitset的啦。
A C C o d e \mathcal AC \ Code AC Code
#includeCF356E Xenia and String Problem
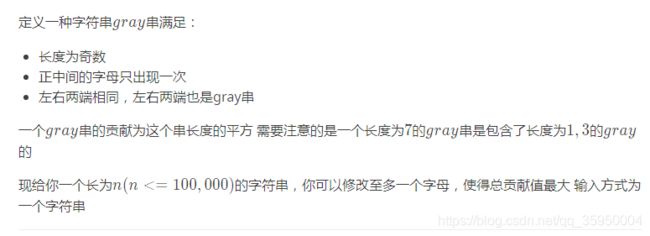
分类讨论屑题。
g r a y gray gray串的长度只有可能是 2 k − 1 2^k-1 2k−1,所以可以计算出所有 g r a y gray gray串。
改字符,
一.变为 g r a y gray gray的情况:
1.改中间字符原来在外面出现过现在没出现过,暴力哈希判断即可。
2.改两边字符,原来差一个字符匹配现在不差了,对于所有 g r a y gray gray串求出往左/右差一个字符的位置贡献上去。
二.变成不是 g r a y gray gray的情况:
1.改中间字符原来在外面没出现过现在出现过,暴力哈希判断即可。
2.改两边字符,原来就是 g r a y gray gray串,只要改了两边就一定不是,对于所有 g r a y gray gray串写区间加即可。
综上,每次就是先减去改字符是中间字符的贡献,再减去(二.2),然后枚举改成那个字符,加上(一.2),加上中间字符的贡献。
真的屑
A C C o d e \mathcal AC \ Code AC Code
#includeLOJ #517. 「LibreOJ β Round #2」计算几何瞎暴力

那就看代码吧。
#includeLOJ #2168. 「POI2011 R3 Day1」周期性 Periodicity
社论
设字符串 s s s的最短周期为 L L L, L L L的计算可以简单通过 k m p kmp kmp得到。
那么对 L L L分类讨论,
L = 1 L=1 L=1则应该对于一个全为 0 0 0的字符串。
L = ∣ s ∣ L=|s| L=∣s∣则应该对应一个前 L − 1 L-1 L−1位全为 0 0 0,最后一位为 1 1 1的字符串。
2 L ≤ ∣ s ∣ 2L \leq |s| 2L≤∣s∣,则将字符串分解为 t t t t . . . t ′ tttt...t' tttt...t′的形式,递归求 t t ′ tt' tt′的答案,然后根据最短周期倒推出 s s s所对应的字符串,之所以可以这样做,是因为可以通过有两个周期 p , q p,q p,q并且 p + q ≤ ∣ s ∣ p+q \leq |s| p+q≤∣s∣那么他们的 gcd \gcd gcd也是周期来证明,最短周期是 l l l的情况下长度大于 l + ( ∣ s ∣ m o d l ) l+(|s|\bmod l) l+(∣s∣modl)的所有周期其实都是 l l l的倍数。
因为我们递归求出的答案是一定会满足所有 ≤ l + ( ∣ s ∣ m o d l ) \leq l+(|s|\bmod l) ≤l+(∣s∣modl)的周期,所以 t t t t . . t ′ tttt..t' tttt..t′是可以满足题意的。
2 L > ∣ s ∣ 2L\gt |s| 2L>∣s∣,将字符串分解为 t a t tat tat的形式,其中 ∣ t ∣ = ∣ s ∣ m o d L |t| = |s| \bmod L ∣t∣=∣s∣modL,递归求 t t t的答案,发现 a a a要么是全为 0 0 0,要么是只有最后一个为 1 1 1,简单 k m p kmp kmp判断一下即可。

A C C o d e \mathcal AC \ Code AC Code
#include#2278. 「HAOI2017」字符串
如果从前往后第一次失配和从后往前第一次失配的位置之差 ≤ K − 1 \leq K-1 ≤K−1则匹配,求 p i p_i pi在 s s s中出现次数,那么我们建出 p i p_i pi的 A C AC AC自动机,对于 p i p_i pi的前 x x x个字符,在 A C AC AC自动机上有个位置 a a a,对于 p i [ x + K + 1.... ∣ p i ∣ ] p_i[x+K+1....|p_i|] pi[x+K+1....∣pi∣],我们求出 p i p_i pi的反串的 A C AC AC自动机,那么这个 p i [ x + K + 1.... ∣ p i ∣ ] p_i[x+K+1....|p_i|] pi[x+K+1....∣pi∣]反过来进入自动机也有一个位置 b b b。
对于 s s s的前 y y y个字符在正串自动机上有个位置 c c c,后 ∣ s ∣ − y − K |s|-y-K ∣s∣−y−K个字符在反串自动机上也有个位置 d d d。
s s s和 p i p_i pi同时删去中间的 K K K个字符后 p i p_i pi在 s s s中出现,可以看做在 A C AC AC自动机的后缀树上 c c c在 a a a的子树中, d d d在 b b b的子树中。
但是可能会有多种删去连续 K K K个字符的方案使得他们相等,会算重,我们发现这些删去的 K K K个字符的所有方案是连续的(比如删去区间是 [ x , x + K + 1 ] , [ x + 1 , x + K + 2 ] , [ x + 2 , x + K + 3 ] [x,x+K+1],[x+1,x+K+2],[x+2,x+K+3] [x,x+K+1],[x+1,x+K+2],[x+2,x+K+3]),所以相邻两个方案( [ x , x + K + 1 ] , [ x + 1 , x + K + 2 ] [x,x+K+1],[x+1,x+K+2] [x,x+K+1],[x+1,x+K+2])对应了一个删去 K − 1 K-1 K−1个字符的方案( x + 1 , x + K + 1 x+1,x+K+1 x+1,x+K+1),所以直接减去删去 K − 1 K-1 K−1个字符的方案即可,但是因为 [ 0.... K − 1 ] [0....K-1] [0....K−1]不能对应相邻两个方案,所以不能计算形如这类的贡献。
那么就是两棵树,求在两棵树中点都在当前点对的点的子树内的数量,这可以看做二维平面上的数点问题,但是还有更简单的做法,用天天爱跑步的方法树上差分后即可用 d f s dfs dfs解决一棵树的限制。
A C C o d e \mathcal AC \ Code AC Code
#include