SCRDet:针对杂乱和旋转的小目标检测方法
目录
- 论文下载地址
- 代码下载地址
- 论文作者
- 模型讲解
- [背景介绍]
- [模型解读]
- [精细采样与特征融合网络]
- [SF-Net]
- [MDA-Net]
- [旋转分支]
- [损失函数]
- [结果分析]
- [数据集与训练细节]
- [消融研究]
- [DOTA数据集上与其他方法对比]
- [[NWPU VHR-10数据集上与其他方法对比]]()
论文下载地址
[论文地址]
代码下载地址
[GitHub-official]
论文作者
模型讲解
[背景介绍]
在遥感图像目标检测中感兴趣目标不再像COCO,VOC中那样在水平方向上垂直放置。对于场景文本检测,文本可以在任何方向和位置上进行检测。尤其是遥感图像面临以上三个挑战:
①小目标
遥感图像通常包含被复杂环境淹没的小目标场景。
②杂乱无章的排列
用于检测的对象通常是密集排列的,例如车辆和轮船。
③任意方向
遥感图像中的目标可以以不同的方向出现,大宽高比问题进一步增加难度。
[模型解读]
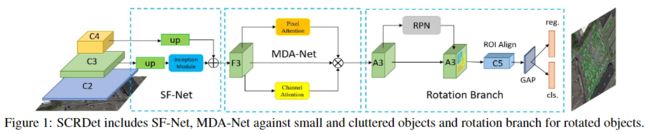
作者提出的是二步的目标检测网络,通过SF-Net和MDA-Net 提取特征,RPN生成水平框,在后面的回归再进行五参数回归,之后通过R-NMS进行非极大值抑制。下图是网络的总体结构。
[精细采样与特征融合网络]
检测小目标有两个障碍:物体特征信息不足和anchors不足。由于使用了池化层,小目标在深层网络中丢失了大部分特征信息。
①特征融合
通常认为低层特征图可以保留小目标的位置信息,而高层特征图可以包含更高层语义特征。特征金字塔网络(FPN)自上而下的信息流动是常见的特征融合方法,其中涉及不同特征的高层和低层特征图的组合。
②精细采样
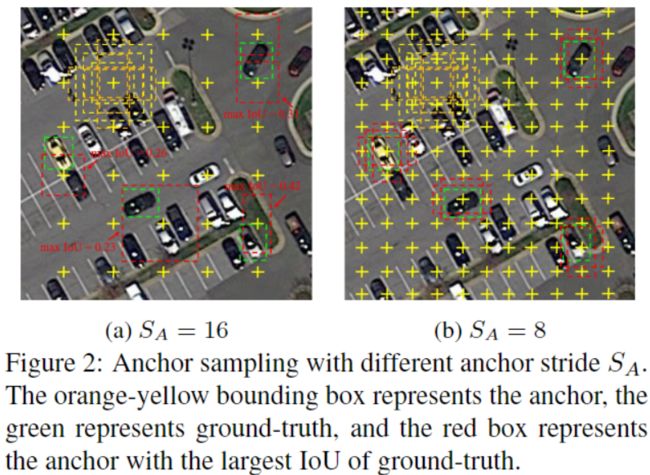
训练样本不足和不平衡会影响检测性能。通过引入预期的最大重叠(EMO)得分,作者计算了anchors与目标之间的IoU,发现anchors步长越小,则EMO得分越高。下图分别显示了步长16和8进行小目标采样的结果。可以看出,较小的anchors步长可以采样更多高质量的样本,从而很好地捕获了小物体,这对于模型训练和推理都具有帮助。
[SF-Net]
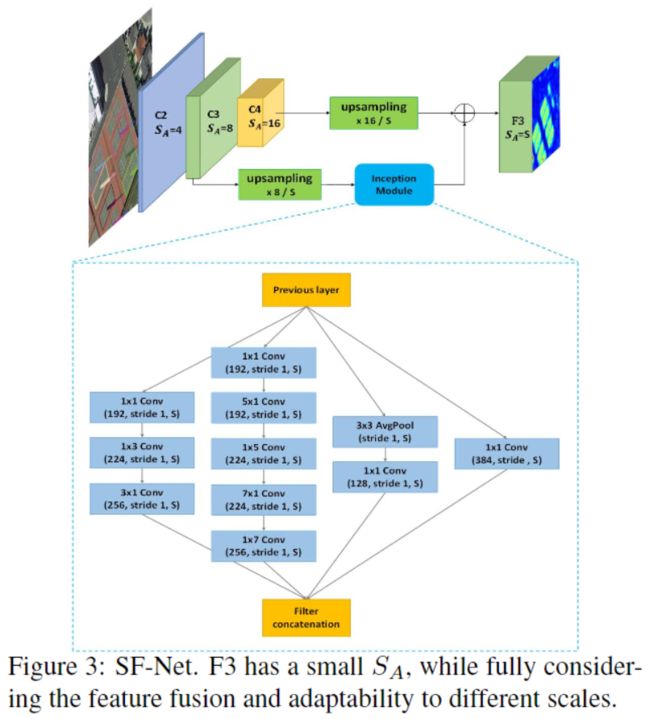
基于以上分析,作者设计了更精细采样和特征融合网络(SF-Net),如上图所示。在基于anchors的检测框架中,anchors的步长等于相对于原始图像的特征缩放倍数。anchors步长只能是2的指数倍。SF-Net通过更改特征图的大小来解决此问题,从而使anchors步长的设置更灵活以允许更自适应的采样。为了减少网络参数,SF-Net仅使用Resnet中的C3和C4进行融合,以平衡语义信息和位置信息,同时忽略其他不太相关的特征。SF-Net的第一个管道对C4进行上采样,使其 S A = S S_A = S SA=S,即期望的anchors步长;第二个管道也对C3进行上采样至相同大小,增加语义信息。Inception结构包含各种尺寸的卷积核,以捕获目标形状的多样性。最后,通过将两个通道逐个元素相加获得新的特征图 F 3 F_3 F3。下表展示了再DOTA数据集上采用不同的回归方式、anchors步长的精度与耗时的关系。本文作者选择anchors步长为6。

[MDA-Net]
由于遥感图像的数据复杂性,RPN提供的建议区域可能会引入大量的噪声信息,如下图图b所示。过多的噪声会淹没目标信息,对象之间的边界将变得模糊如下图a,导致漏检或者虚警。有必要增强目标提示并削弱非目标信息。很多论文使用注意力机制来解决遮挡,噪声和模糊的问题。
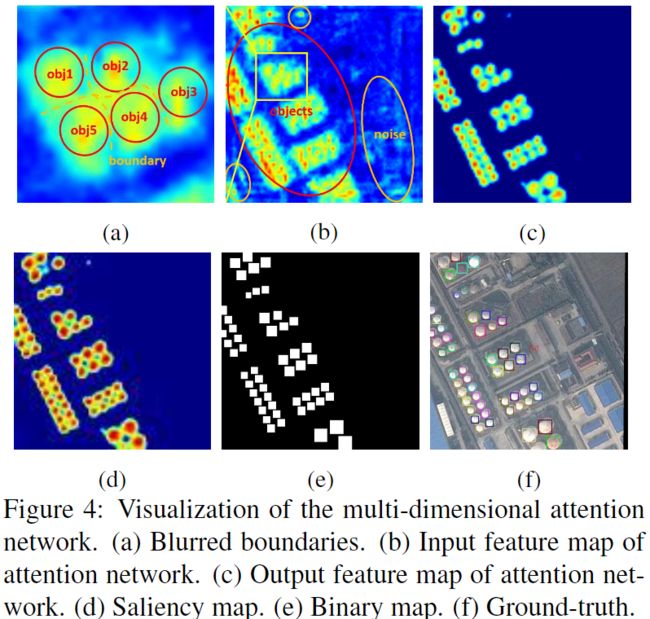
为了更有效地捕获复杂背景下的小目标的特征,作者设计了一个有监督的多维注意力网络(MDA-Net),如下图所示。在像素注意力网络中,特征图 F 3 F_3 F3通过一个初始具有不同尺寸的卷积核的结构,然后通过卷积学习两通道的Mask上图d,Mask分别表示前景和背景的得分。然后,在Mask上进行SoftMax运算,并选择一个通道与F3相乘。如上图c所示,获得了一个新的特征图 A 3 A_3 A3。Softmax函数之后的Mask的值在 [ 0 , 1 ] [0,1] [0,1]之间。像素注意力可以减少噪声并相对增强目标信息。为了网络学习此过程,作者采用了有监督学习方法,可以很容易地根据真实标签获得一个二值掩码Mask作为标签上图e所示,然后将二值掩码和Mask的交叉熵损失作为注意力损失。使用SENet作为辅助的通道注意力。

[旋转分支]
作者使用五参数回归模型进行旋转目标检测: ( x , y , w , h , θ ) (x,y,w,h,\theta) (x,y,w,h,θ)表示任意方向的矩形框。 θ \theta θ的取值范围为 [ − π / 2 , 0 ) [-\pi/2,0) [−π/2,0),为矩形的某一个边与 x x x正向的夹角,这条边为 w w w,此定义与OpenCV一致。由于旋转框的IoU计算比较困难,所以作者采用偏斜IoU解决此问题,用于正负样本的筛选和作为R-NMS的参考。R-NMS可以针对不通过类别的旋转框进行抑制。旋转边界框的回归为:
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t w = log ( w / w a ) , t h = log ( h / h a ) , t θ = θ − θ a t x ′ = ( x ′ − x a ) / w a , t y ′ = ( y ′ − y a ) / h a t w ′ = log ( w ′ / w a ) , t h ′ = log ( h ′ / h a ) , t θ ′ = θ ′ − θ a \begin{array}{c} t_{x}=\left(x-x_{a}\right) / w_{a}, t_{y}=\left(y-y_{a}\right) / h_{a} \\ t_{w}=\log \left(w / w_{a}\right), t_{h}=\log \left(h / h_{a}\right), t_{\theta}=\theta-\theta_{a} \\\\\\ t_{x}^{\prime}=\left(x^{\prime}-x_{a}\right) / w_{a}, t_{y}^{\prime}=\left(y^{\prime}-y_{a}\right) / h_{a} \\ t_{w}^{\prime}=\log \left(w^{\prime} / w_{a}\right), t_{h}^{\prime}=\log \left(h^{\prime} / h_{a}\right), t_{\theta}^{\prime}=\theta^{\prime}-\theta_{a} \end{array} tx=(x−xa)/wa,ty=(y−ya)/hatw=log(w/wa),th=log(h/ha),tθ=θ−θatx′=(x′−xa)/wa,ty′=(y′−ya)/hatw′=log(w′/wa),th′=log(h′/ha),tθ′=θ′−θa
其中 x , y , w , h , θ x,y,w,h,\theta x,y,w,h,θ为一个旋转框的坐标。 x , x a , x ′ x,x_a,x^\prime x,xa,x′分别是真实框、预选框、预测框的结果。
[损失函数]
使用多任务丢失,其定义如下:
L = λ 1 N ∑ n = 1 N t n ′ ∑ j ∈ { x , y , w , h , θ } L r e g ( v n j ′ , v n j ) ∣ L r e g ( v n j ′ , v n j ) ∣ ∣ − log ( I o U ) ∣ + λ 2 h × w ∑ i ∑ j n L a t t ( u i j ′ , u i j ) + λ 3 N ∑ n = 1 N L c l s ( p n , t n ) \begin{aligned} L=& \frac{\lambda_{1}}{N} \sum_{n=1}^{N} t_{n}^{\prime} \sum_{j \in\{x, y, w, h, \theta\}} \frac{L_{r e g}\left(v_{n j}^{\prime}, v_{n j}\right)}{\left|L_{r e g}\left(v_{n j}^{\prime}, v_{n j}\right)\right|}|-\log (I o U)| \\ &+\frac{\lambda_{2}}{h \times w} \sum_{i} \sum_{j}^{n} L_{a t t}\left(u_{i j}^{\prime}, u_{i j}\right)+\frac{\lambda_{3}}{N} \sum_{n=1}^{N} L_{c l s}\left(p_{n}, t_{n}\right) \end{aligned} L=Nλ1n=1∑Ntn′j∈{x,y,w,h,θ}∑∣∣Lreg(vnj′,vnj)∣∣Lreg(vnj′,vnj)∣−log(IoU)∣+h×wλ2i∑j∑nLatt(uij′,uij)+Nλ3n=1∑NLcls(pn,tn)
其中, N N N表示预选区域数量, t n t_n tn表示目标的类别标签, p n p_n pn是由Softmax函数计算的各种类别的概率分布, t n ′ t^\prime_n tn′是一个二进制值(对于目标 t n ′ = 1 t^\prime_n=1 tn′=1;对于背景 t n ′ = 0 t^\prime_n=0 tn′=0 背景不进行回归)。 v ∗ j ′ v^\prime_{*j} v∗j′表示预测的偏移量, v ∗ j v_{*j} v∗j表示真实偏移量。 u i j , u i j ′ u_{ij},u^\prime_{ij} uij,uij′分别表示二值标签和Mask像素的预测。 I o U IoU IoU表示预测框和真实框的IoU。超参数 λ 1 = 4 , λ 2 = 1 , λ 3 = 2 \lambda_1=4,\lambda_2=1,\lambda_3=2 λ1=4,λ2=1,λ3=2控制损失平衡。另外,分类损失还包括Softmax交叉熵。回归损失 L r e g L_{reg} Lreg为Smooth
L1 loss,而注意力损失 L a t t L_{att} Latt为像素级Softmax交叉熵。
针对PoE问题,也就是旋转角度周期导致的损失不连续问题,作者在传统的Smooth L1损失中引入了 I o U IoU IoU常数因子 ∣ − log ( I o U ) ∣ ∣ L r e g ( v j ′ , v j ) ∣ \frac{|-\log(IoU)|}{| L_{reg}(v^\prime_j,v_j)|} ∣Lreg(vj′,vj)∣∣−log(IoU)∣。在边界情况下 ∣ − log ( I o U ) ∣ ≈ 0 | -\log(IoU)|≈0 ∣−log(IoU)∣≈0,损失函数近似等于0,消除了损失的突然增加。新的回归损失可以分为两部分, L r e g ( v j ′ , v j ) ∣ L r e g ( v j ′ , v j ) ∣ \frac{L_{reg}(v^\prime_j,v_j)}{| L_{reg}(v^\prime_j,v_j)|} ∣Lreg(vj′,vj)∣Lreg(vj′,vj)确定梯度传播的方向,和 ∣ − log ( I o U ) ∣ | -\log(IoU)| ∣−log(IoU)∣表示梯度的大小。
[结果分析]
[数据集与训练细节]
作者使用预训练的ResNet-101模型进行初始化。使用DOTA、NWPU VHR-10数据集进行训练与测试对于,除了训练过程中的随机图像翻转外,不执行任何数据增强。
对于参数设置,预选的anchors步长为6,anchors基本面积设置为256,anchors_scales设置为 2 − 4 2^{-4} 2−4至 2 1 2^1 21。由于DOTA和NWPU VHR-10中的多类别对象具有不同的形状,因此作者将anchors_ratio设置为 [ 1 / 1 , 1 / 2 , 1 / 3 , 1 / 4 , 1 / 5 , 1 / 6 , 1 / 7 , 1 / 9 ] [1/1,1/2,1 / 3,1 / 4,1 / 5,1 / 6,1 / 7,1 / 9] [1/1,1/2,1/3,1/4,1/5,1/6,1/7,1/9]。当 I o U > 0.7 IoU> 0.7 IoU>0.7时,将anchors定为正样本,如果 I o U < 0.3 IoU <0.3 IoU<0.3,则将锚定为负样本。
[消融研究]
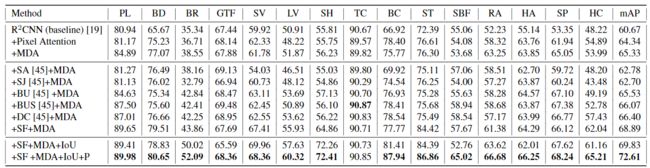

效果差的是MDA-Net不进行有监督训练。
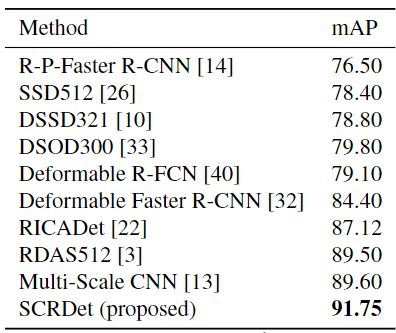
[DOTA数据集上与其他方法对比]

[NWPU VHR-10数据集上与其他方法对比]