爬虫
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
提取本地html中的数据
1.新建html文件
2.读取
3.使用 lxml 中的 xpath 语法进行提取
比如:使用lxml提取h1标签中的内容
from lxml import html
# 读取html文件
with open('./index.html', 'r', encoding='utf-8') as f:
html_data = f.read()
# print(html_data)
#解析html文件,获得selector对象
selector = html.fromstring(html_data)
# selector 中调用xpath方法
# 要获取标签中的内容,末尾要添加text()
h1 = selector.xpath('/html/body/h1/text()')
print(h1[0])
# // 可以代表从任意位置出发
# //标签1[@属性=属性值]/标签2[@属性=属性值]....
a = selector.xpath('//div[@id="container"]/a/text()')
print(a[0])
# 获取p标签的内容
p = selector.xpath('//div[@id="container"]/p1/text()')
print(p[0])
# 获取属性
link = selector.xpath('//div[@id="container"]/a/@href')
print(link[0])
执行结果如下
网络爬虫使用requests库
在使用python爬虫爬取数据的时候,经常会遇到一些网站的反爬虫措施,一般就是针对于headers中的User-Agent,如果没有对headers进行设置,User-Agent会声明自己是python脚本,而如果网站有反爬虫的想法的话,必然会拒绝这样的连接。而修改headers可以将自己的爬虫脚本伪装成浏览器的正常访问,来避免这一问题。
import requests
from lxml import html
url = 'http://www.dangdang.com'
response = requests.get(url)
print(response)
# 获取str类型的响应 根据http头部对响应的编码做出有根据的推测
print(response.text)
# 获取bytes类型的响应
print(response.content)
# 获取响应头
print(response.headers)
# 获取状态码
print(response.status_code)
print(response.encoding)
没有添加请求头
resp = requests.get('https://www.zhihu.com')
print(resp.status_code)
使用字典定义请求头
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get('http://www.dangdang.com', headers = header)
print(resp.status_code)
运行结果大致如下:
也可以将爬到的html页面写入本地
import requests
def spider_dangdang(isbn):
book_list = []
# 目标站点地址
url = 'http://search.dangdang.com/?key={}&act=input'.format(isbn)
# 获取站点str类型的响应
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get(url, headers=header)
html_data = resp.text
# 将html页面写入本地
with open('dangdnag.html', 'w', encoding='utf-8') as f:
f.write(html_data)
spider_dangdang(9787115428028)
$JOOAMX01JC)I({5ZQ1W}9F.jpg
我们还可以获取目标站点的详细信息
import requests
from lxml import html
import pandas as pd
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def spider_dangdang(isbn):
book_list = []
# 目标站点地址
url = 'http://search.dangdang.com/?key={}&act=input'.format(isbn)
# 获取站点str类型的响应
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get(url, headers=header)
html_data = resp.text
# 将html页面写入本地
# with open('dangdnag.html', 'w', encoding='utf-8') as f:
# f.write(html_data)
# 提取目标站的信息
selector = html.fromstring(html_data)
ul_list = selector.xpath('//div[@id="search_nature_rg"]/ul/li')
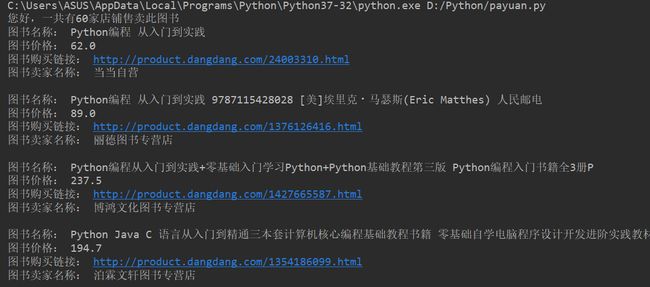
print('您好,一共有{}家店铺售卖此图书'.format(len(ul_list)))
# 遍历ul_list
for li in ul_list:
# 图书名称
title = li.xpath('./a/@title')[0].strip()
print('图书名称:', title)
# 图书价格
price = li.xpath('./p[@class="price"]/span[@class="search_now_price"]/text()')[0]
price = float(price.replace('¥', ''))
print('图书价格:', price)
# 图书购买链接
link = li.xpath('./a/@href')[0]
print('图书购买链接:', link)
# 图书卖家名称
store = li.xpath('./p[@class="search_shangjia"]/a[1]/text()')
# if len(store) == 0:
# store = "当当自营"
# else:
# store = store[0]
# price = price.replace('¥', '')
store = "当当自营" if len(store) == 0 else store[0]
print('图书卖家名称:', store)
print('')
spider_dangdang(9787115428028)
可以得到下面的结果
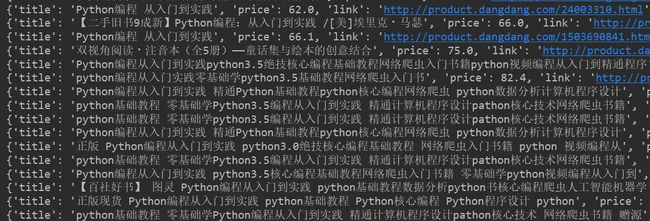
我们可以追加一下代码按照价格进行排序,并遍历图书信息
#按照价格进行排序
book_list.sort(key=lambda x: x['price'])
# 遍历book_list
for book in book_list:
print(book)
可以得到下面的结果
用下面的代码,我们可以将数据存储成csv文件
df = pd.DataFrame(book_list)
df.to_csv('dangdang.csv')
记得导入 pandas
import pandas as pd
执行程序,文件夹中就会生成相应的csv文件
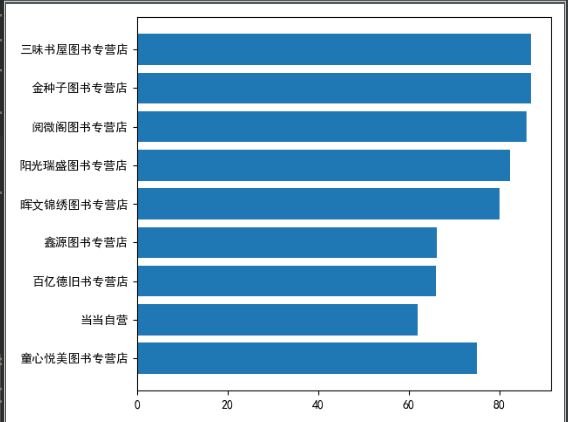
也能用柱状图展示价格最低的前十家
top10 = [book_list[i] for i in range(10)]
x = [x['store'] for x in top10]
print(x)
y = [x['price'] for x in top10]
print(y)
# plt.bar(x, y)
plt.barh(x, y)
plt.show()
记得导入包,否则会报错
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
练习
提取https://movie.douban.com/cinema/later/chongqing网站以下信息,并且根据信息完成3,4效果
1.电影名,上映日期,类型,上映国家,想看人数
2.根据想看人数进行排序
3.绘制即将上映电影国家的占比图
4.绘制top5最想看的电影
import requests
from lxml import html
from matplotlib import pyplot as plt
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def spider_douban():
movies_list = []
counts = {}
# 目标站点地址
url = 'https://movie.douban.com/cinema/later/chongqing/'
# 获取站点str类型的响应
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"}
resp = requests.get(url, headers=header)
html_data = resp.text
# 将html页面写入本地
# with open('douban.html', 'w', encoding='utf-8') as f:
# f.write(html_data)
# 提取目标站的信息
selector = html.fromstring(html_data)
ul_list = selector.xpath('//div[@id="showing-soon"]/div')
print('您好,一共有{}部电影即将上映'.format(len(ul_list)))
# 遍历ul_list
for li in ul_list:
# 电影名
title = li.xpath('./div[@class="intro"]/h3/a/text()')[0]
print('电影名:', title)
#
#
# 上映日期
date = li.xpath('./div[@class="intro"]/ul/li[1]/text()')[0]
# price = float(price.replace('¥', ''))
print('上映日期:', date)
#
# 类型
type = li.xpath('./div[@class="intro"]/ul/li[2]/text()')[0]
types = str(type.replace('/', ','))
print('类型:', types)
# 上映国家
nation = li.xpath('./div[@class="intro"]/ul/li[3]/text()')[0]
print('上映国家:', nation)
# 想看人数
want_num = li.xpath('./div[@class="intro"]/ul/li[4]/span/text()')[0]
want_num = int(want_num.replace('人想看', ''))
print('想看人数:', want_num)
# 添加每一部电影的信息
movies_list.append({
'title': title,
'date': date,
'types': types,
'nation': nation,
'want_num': want_num
})
for nation in movies_list:
counts[nation['nation']] = counts.get(nation['nation'], 0) + 1
print(counts)
# 4.排序 [(), ()]
items = list(counts.items())
items.sort(key=lambda x: x, reverse=True)
print(items)
nations = []
cishu = []
for i in range(4):
#序列解包
na, count = items[i]
# print(role, count)
nations.append(na)
cishu.append(count)
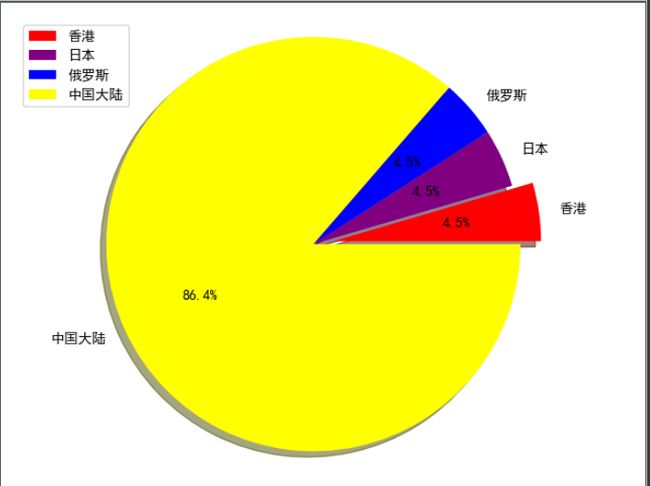
explode = [0.1, 0, 0, 0]
colors = ['red', 'purple', 'blue', 'yellow']
plt.pie(cishu, explode=explode, colors=colors, shadow=True, labels=nations, autopct='%1.1f%%')
plt.legend(loc=2) # 图例位置
plt.axis('equal')
plt.show()
# 按照价格进行排序
movies_list.sort(key=lambda x: x['want_num'], reverse=True)
# 遍历book_list
for movie in movies_list:
print(movie)
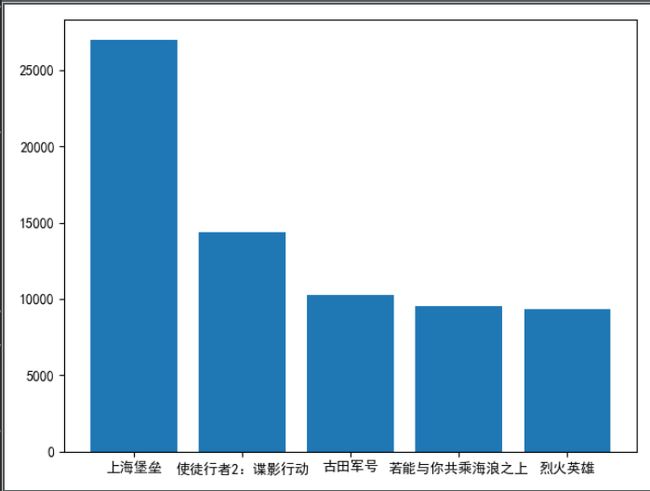
# 展示最想看的top5
top5 = [movies_list[i] for i in range(5)]
x = [x['title'] for x in top5]
print(x)
y = [x['want_num'] for x in top5]
print(y)
plt.bar(x, y)
# plt.barh(x, y)
plt.show()
spider_douban()
可以得到下面的结果: