Runtime源码剖析---图解引用计数与weak
文章目录
- Runtime源码剖析---图解引用计数与weak
- 前言
- 什么是引用计数?
- 什么是循环引用?
- 引用计数
- 引用计数的存储
- isa指针中的引用计数
- Side Table里的引用计数
- 引用计数的管理
- 管理引用计数的方法
- 获取引用计数
- 非ARC环境下
- ARC环境下
- retain的实现
- release的实现
- dealloc的实现
- weak
- SideTables
- SideTable
- spinlock_t:自旋锁
- RefcountMap:存放引用计数
- RefcountMap工作逻辑
- weak_table_t:维护weak指针
- weak_entry_t
- weak_table_t 的工作逻辑
- 初始化weak指针
- weak指针置nil
Runtime源码剖析—图解引用计数与weak
在iOS开发过程中,会经常使用到一个修饰词“weak”,使用场景大家都比较清晰,用于一些对象相互引用的时候,避免出现强引用,对象不能被释放,出现内存泄露的问题。
weak 关键字的作用弱引用,所引用对象的计数器不会加一,并在引用对象被释放的时候自动被设置为 nil。
前言
什么是引用计数?
Objective-C通过retainCount的机制来决定对象是否需要释放。 每次runloop迭代结束后,都会检查对象的retainCount,如果retainCount等于0,就说明该对象没有地方需要继续使用它,可以被释放掉了。无论是手动管理内存,还是ARC机制,都是通过对retainCount来进行内存管理的。- 内存中每一个对象都有一个属于自己的引用计数器。当某个对象A被另一个家伙引用时,A的引用计数器就+1,如果再有一个家伙引用到A,那么A的引用计数器就再+1。当其中某个家伙不再引用A了,A的引用计数器会-1。直到A的引用计数减到了0,那么就没有人再需要它了,就是时候把它释放掉了。
在引用计数中,每一个对象负责维护对象所有引用的计数值。当一个新的引用指向对象时,引用计数器就递增,当去掉一个引用时,引用计数就递减。当引用计数到零时,该对象就将释放占有的资源。
什么是循环引用?
-
循环引用发生的条件:
- 两个对象互相强引用对方
- 该对象持有其自身(自己引用自己)
-
这个时候就提出了
__weak修饰符,提供弱引用,不能持有对象实例,若该对象被废弃,则此弱引用将自动失效且处于nil被赋值的状态
对前面两个问题进行总结:
- 如何实现的引用计数管理,控制加一减一和释放?
- 如何维护weak指针防止野指针错误?
- 这也就是我们这篇文章要解决的主要问题,下面我们就会针对上面两个问题一一解释。
引用计数
引用计数的存储
有些对象如果支持使用
TaggedPointer,苹果会直接将其指针值作为引用计数返回;如果当前设备是 64 位环境并且使用Objective-C 2.0,那么‘一些’对象会使用其isa指针的一部分空间来存储它的引用计数;否则Runtime会使用一张散列表来管理引用计数。
-
我们知道,对于纯量类型的变量,是没有引用计数的,因为不是对象,其申请的变量存储在栈上,由系统来负责管理。
-
另外一种类型,是前面讲过的
Tagged Pointer小对象,包括NSNumber、NSString、NSDate等几个类的变量。它们也是存储在栈上,当然也没有引用计数。
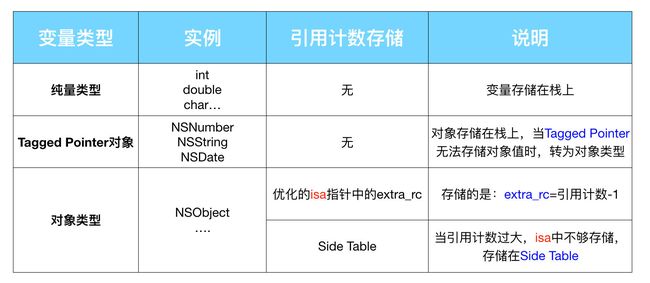
- 关于对象类型的引用计数,其存在的两种方式

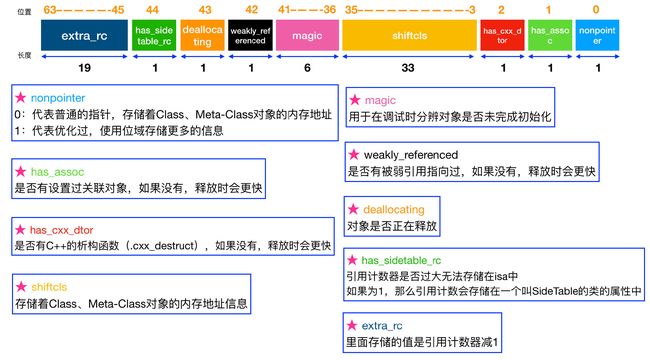
isa指针中的引用计数
- 如果你对isa不够熟悉的话,可以看看我这篇文章Runtime源码剖析—图解对象、类与isa
- 简单来说,就是isa再32位之前为指针,在64位操作系统之后就不仅仅是个指针,是个联合体,它一部分负责存储地址,另一部分可以存储其他的信息。这样做可以提高了内存的使用率、减少了不必要的开销。
- 下面我给出isa的源码
union isa_t {
isa_t() { }
isa_t(uintptr_t value) : bits(value) { }
Class cls;
// 相当于是unsigned long bits;
uintptr_t bits;
#if defined(ISA_BITFIELD)
// 这里的定义在isa.h中,如下(注意uintptr_t实际上就是unsigned long)
// uintptr_t nonpointer : 1; \
// uintptr_t has_assoc : 1; \
// uintptr_t has_cxx_dtor : 1; \
// uintptr_t shiftcls : 44; /*MACH_VM_MAX_ADDRESS 0x7fffffe00000*/ \
// uintptr_t magic : 6; \
// uintptr_t weakly_referenced : 1; \
// uintptr_t deallocating : 1; \
// uintptr_t has_sidetable_rc : 1; \
// uintptr_t extra_rc : 8
struct {
ISA_BITFIELD; // defined in isa.h
};
#endif
};
- 下面列出
isa指针中变量对应的含义
| 变量名 | 含义 |
|---|---|
| indexed | 0 表示普通的 isa 指针,1 表示使用优化,存储引用计数 |
| has_assoc | 表示该对象是否包含 associated object,如果没有,则析构时会更快 |
| has_cxx_dtor | 表示该对象是否有 C++ 或 ARC 的析构函数,如果没有,则析构时更快 |
| shiftcls | 类的指针 |
| magic | 固定值为 0xd2,用于在调试时分辨对象是否未完成初始化。 |
| weakly_referenced | 表示该对象是否有过 weak 对象,如果没有,则析构时更快 |
| deallocating | 表示该对象是否正在析构 |
| has_sidetable_rc | 表示该对象的引用计数值是否过大无法存储在 isa 指针 |
| extra_rc | 存储引用计数值减一后的结果 |
- 我们发现最后两个变量,就和我们引用计数相关。
- 最后我们用一张图来看看具体布局
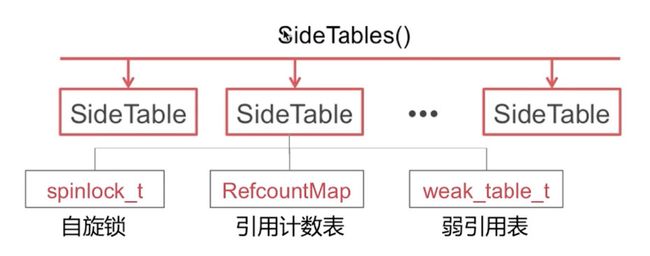
Side Table里的引用计数
- Side Table 在系统中的结构如下:
- 而每一个
Side Table中引用计数的结构
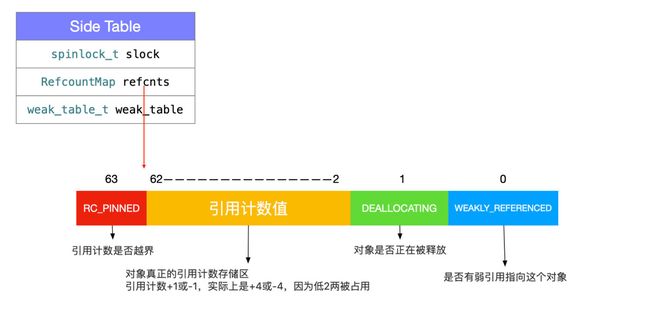
- 现在我们只需要了解一下有这个结构就够了,我会在后面仔细剖析如何存储和如何调用的。
引用计数的管理
管理引用计数的方法
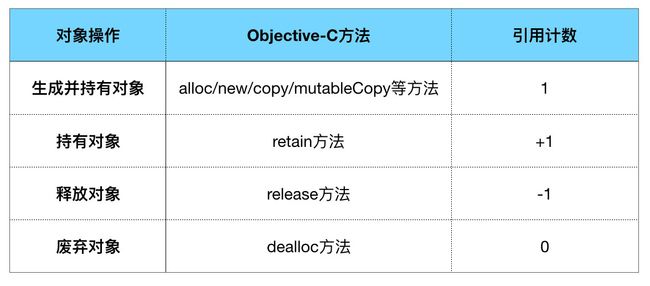
获取引用计数
非ARC环境下
- 在非ARC环境下通过
retainCount方法来获取引用计数
- (NSUInteger)retainCount {
return ((id)self)->rootRetainCount();
}
该方法内部调用了rootRetainCount函数
inline uintptr_t
objc_object::rootRetainCount()
{
//1.如果是Tagged Pointer,直接返回指针
if (isTaggedPointer()) return (uintptr_t)this;
sidetable_lock();
isa_t bits = LoadExclusive(&isa.bits);
ClearExclusive(&isa.bits);
//如果是优化后的isa
if (bits.nonpointer) {
//取出isa中的retainCount+1;
uintptr_t rc = 1 + bits.extra_rc;
if (bits.has_sidetable_rc) {
//如果Side Table还有存储,则取出累加返回
rc += sidetable_getExtraRC_nolock();
}
sidetable_unlock();
return rc;
}
sidetable_unlock();
return sidetable_retainCount();
}
- 如果它既不是
Tagged Point对象,isa指针中也没有存储引用计数,这个时候就会走sidetable_retainCount这个方法。
uintptr_t
objc_object::sidetable_retainCount()
{
//先从SideTables中取出对应的SideTable对象
SideTable& table = SideTables()[this];
size_t refcnt_result = 1;
table.lock();
//通过table对象中的refcnts,在通过传入的地址,找到对应的引用计数
RefcountMap::iterator it = table.refcnts.find(this);
if (it != table.refcnts.end()) {
// this is valid for SIDE_TABLE_RC_PINNED too
refcnt_result += it->second >> SIDE_TABLE_RC_SHIFT;
}
table.unlock();
return refcnt_result;
}
- 这里有个疑惑,为什么要把取出来的数据进行右移位操作呢?
- 因为在
refcnts中存储的并不是直接就是引用计数,而是可以理解为一个联合体,在他的低2位存储其他特殊信心,引用计数从第三位开始存储,所以取出来的时候需要右移操作。
- 因为在
ARC环境下
- 在
ARC时代除了使用Core Foundation库的CFGetRetainCount()方法,也可以使用Runtime的_objc_rootRetainCount(id obj)方法来获取引用计数,此时需要引入objc_object的rootRetainCount()方法:所以分析同上。


retain的实现
inline id
objc_object::retain()
{
assert(!isTaggedPointer());
if (fastpath(!ISA()->hasCustomRR())) {
return rootRetain();
}
return ((id(*)(objc_object *, SEL))objc_msgSend)(this, SEL_retain);
}
- 这个方法内部会调用
rootRetain()方法
ALWAYS_INLINE id
objc_object::rootRetain(bool tryRetain, bool handleOverflow)
{
//Tagged Pointer对象直接返回
if (isTaggedPointer()) return (id)this;
bool sideTableLocked = false;
//transcribeToSideTable用于表示extra_rc是否溢出,默认为false
bool transcribeToSideTable = false;
isa_t oldisa;
isa_t newisa;
do {
transcribeToSideTable = false;
oldisa = LoadExclusive(&isa.bits);//将isa提取出来
newisa = oldisa;
//如果isa没有优化,直接从sideTable中返回引用计数
if (slowpath(!newisa.nonpointer)) {
ClearExclusive(&isa.bits);
if (!tryRetain && sideTableLocked) sidetable_unlock();
if (tryRetain) return sidetable_tryRetain() ? (id)this : nil;
else return sidetable_retain();
}
//如果对象正在析构,则直接返回nil
if (slowpath(tryRetain && newisa.deallocating)) {
ClearExclusive(&isa.bits);
if (!tryRetain && sideTableLocked) sidetable_unlock();
return nil;
}
uintptr_t carry;
//isa指针中的extra_rc+1;
newisa.bits = addc(newisa.bits, RC_ONE, 0, &carry); // extra_rc++
if (slowpath(carry)) {
//有进位,表示溢出,extra_rc已经不能存储在isa指针中了
// newisa.extra_rc++ overflowed
if (!handleOverflow) {
//如果不处理溢出情况,则在这里会递归调用一次,再进来的时候
//handleOverflow会被rootRetain_overflow设置为true,从而直接进入到下面的溢出处理流程
ClearExclusive(&isa.bits);
return rootRetain_overflow(tryRetain);
}
// Leave half of the retain counts inline and
// prepare to copy the other half to the side table.
/*
溢出处理
1.先将extra_rc中引用计数减半,继续存储在isa中
2.同时把has_sidetable_rc设置为true,表明借用了sideTable存储
3.将另一半的引用计数,存放在sideTable中
*/
if (!tryRetain && !sideTableLocked) sidetable_lock();
sideTableLocked = true;
transcribeToSideTable = true;
newisa.extra_rc = RC_HALF;
newisa.has_sidetable_rc = true;
}
} while (slowpath(!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)));
if (slowpath(transcribeToSideTable)) {
// Copy the other half of the retain counts to the side table.
//isa的extra_rc溢出,将一半refer count值放到SideTable中
sidetable_addExtraRC_nolock(RC_HALF);
}
if (slowpath(!tryRetain && sideTableLocked)) sidetable_unlock();
return (id)this;
}
- 总结:
- Tagged Pointer 对象,没有 retain。
- isa 中 extra_rc 若未溢出,则累加 1。如果溢出,则将 isa 和 side table 对半存储。

release的实现
inline void
objc_object::release()
{
assert(!isTaggedPointer());
if (fastpath(!ISA()->hasCustomRR())) {
rootRelease();
return;
}
((void(*)(objc_object *, SEL))objc_msgSend)(this, SEL_release);
}
- 这个方法内部会调用
rootRelease
ALWAYS_INLINE bool
objc_object::rootRelease(bool performDealloc, bool handleUnderflow)
{
//如果是Tagged Pointer,直接返回false,不需要dealloc
if (isTaggedPointer()) return false;
bool sideTableLocked = false;
isa_t oldisa;
isa_t newisa;
retry:
do {
oldisa = LoadExclusive(&isa.bits);
newisa = oldisa;
//如果isa未优化,直接调用sideTable的release函数
if (slowpath(!newisa.nonpointer)) {
ClearExclusive(&isa.bits);
if (sideTableLocked) sidetable_unlock();
return sidetable_release(performDealloc);
}
//将当前isa指针中存储的引用计数减1,如果未溢出,返回false,不需要dealloc
uintptr_t carry;
newisa.bits = subc(newisa.bits, RC_ONE, 0, &carry); // extra_rc--
if (slowpath(carry)) {
//减1下导致溢出,则需要从side Table借位,跳转到溢出处理
goto underflow;
}
} while (slowpath(!StoreReleaseExclusive(&isa.bits,
oldisa.bits, newisa.bits)));
if (slowpath(sideTableLocked)) sidetable_unlock();
return false;
underflow:
newisa = oldisa;
if (slowpath(newisa.has_sidetable_rc)) {
//Side Table存在引用计数
if (!handleUnderflow) {
//如果不处理溢出,此处只会调用一次,handleUnderflow会被rootRelease_underflow设置为ture
//再次进入,则会直接进入溢出处理流程
ClearExclusive(&isa.bits);
return rootRelease_underflow(performDealloc);
}
if (!sideTableLocked) {
ClearExclusive(&isa.bits);
sidetable_lock();
sideTableLocked = true;
// Need to start over to avoid a race against
// the nonpointer -> raw pointer transition.
goto retry;
}
//尝试从SideTable中取出,当前isa能存储引用计数最大值的一半的引用计数
size_t borrowed = sidetable_subExtraRC_nolock(RC_HALF);
//如果取出引用计数大于0
if (borrowed > 0) {
//将取出的引用计数减一,并保存到isa中,保存成功返回false(未被销毁)
newisa.extra_rc = borrowed - 1; // redo the original decrement too
bool stored = StoreReleaseExclusive(&isa.bits,
oldisa.bits, newisa.bits);
if (!stored) {
//保存到isa中失败,再次尝试保存
isa_t oldisa2 = LoadExclusive(&isa.bits);
isa_t newisa2 = oldisa2;
if (newisa2.nonpointer) {
uintptr_t overflow;
newisa2.bits =
addc(newisa2.bits, RC_ONE * (borrowed-1), 0, &overflow);
if (!overflow) {
stored = StoreReleaseExclusive(&isa.bits, oldisa2.bits,
newisa2.bits);
}
}
}
if (!stored) {
//如果还是失败,则将借出来的一半retain count,重新返回给side Table
//并且重新从2开始尝试
sidetable_addExtraRC_nolock(borrowed);
goto retry;
}
// Decrement successful after borrowing from side table.
// This decrement cannot be the deallocating decrement - the side
// table lock and has_sidetable_rc bit ensure that if everyone
// else tried to -release while we worked, the last one would block.
sidetable_unlock();
return false;
}
else {
// Side table is empty after all. Fall-through to the dealloc path.
}
}
//以上流程执行完了,则需要销毁对象,调用dealloc
if (slowpath(newisa.deallocating)) {
//对象正在销毁
ClearExclusive(&isa.bits);
if (sideTableLocked) sidetable_unlock();
return overrelease_error();
// does not actually return
}
newisa.deallocating = true;
if (!StoreExclusive(&isa.bits, oldisa.bits, newisa.bits)) goto retry;
if (slowpath(sideTableLocked)) sidetable_unlock();
__sync_synchronize();
//销毁对象
if (performDealloc) {
((void(*)(objc_object *, SEL))objc_msgSend)(this, SEL_dealloc);
}
return true;
}
- release总结

dealloc的实现
- (void)dealloc {
_objc_rootDealloc(self);
}
- 进入
_objc_rootDealloc
void
_objc_rootDealloc(id obj)
{
assert(obj);
obj->rootDealloc();
}
- 进入
rootDealloc
inline void
objc_object::rootDealloc()
{
if (isTaggedPointer()) return; // fixme necessary?
//如果是优化的isa
//并且对应的没有关联对象、weak应用、以及c++析构函数和sideTable的引用计数,就直接free掉
if (fastpath(isa.nonpointer &&
!isa.weakly_referenced &&
!isa.has_assoc &&
!isa.has_cxx_dtor &&
!isa.has_sidetable_rc))
{
assert(!sidetable_present());
free(this);
}
else {
//进入销毁流程
object_dispose((id)this);
}
}
- 进入
object_dispose
id
object_dispose(id obj)
{
if (!obj) return nil;
objc_destructInstance(obj);
free(obj);
return nil;
}
- 接着进入
objc_destructInstance
void *objc_destructInstance(id obj)
{
if (obj) {
// Read all of the flags at once for performance.
bool cxx = obj->hasCxxDtor();
bool assoc = obj->hasAssociatedObjects();
// This order is important.
if (cxx) object_cxxDestruct(obj);//清除成员变量
if (assoc) _object_remove_assocations(obj);//移除关联对象
obj->clearDeallocating();//将指向当前的弱指针置为nil
}
return obj;
}
- 最后我们留下了一个悬念,如何把指向当前的弱指针置为nil?我会在weak指针置nil这一节给大家讲解
weak
在最开始我们说引用计数的存储方式,清楚说到有两种,一种是通过isa,另一种是通过Side Tables。那这个东西到底是什么,它又是怎么实现weak指针置nil的呢?接下来我们带大家慢慢分析
SideTables
- 我们先介绍几个知识点
HashMap(哈希表)
基于数组的一种数据结构, 通过一定的算法, 把 key 进行运算得出一个数字, 用这个数字做数组下标, 将 value 存入这个下标对应的内存中.
HashTon(哈希桶)
哈希算法中计算出的数字, 有可能会重复, 对于哈希值重复的数据, 如何存入哈希表呢? 常用方法有闭散列和开散列等方式, 其中采用开散列方式的哈希表, 就可以称为哈希桶. 开散列就是在哈希值对应的位置上, 使用链表或数组, 将哈希值冲突的数据存入这个链表或者数组中, 可以提高查找效率.
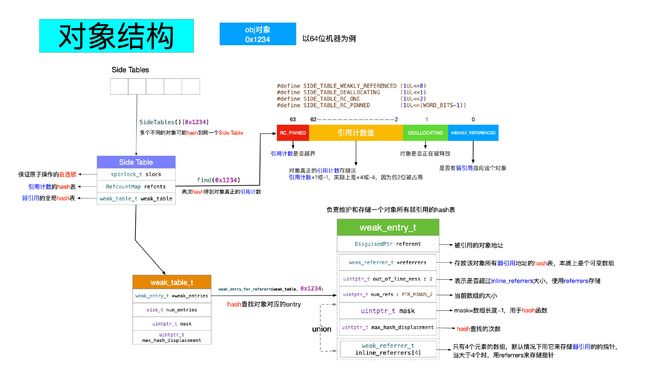
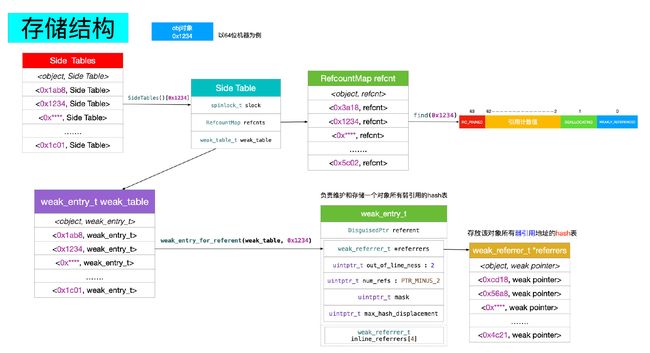
- 为了管理所有对象的引用计数和
weak指针,苹果创建了一个全局的SideTables,虽然名字后面有个"s"不过他其实是一个全局的Hash桶,里面的内容装的都是SideTable结构体而已。它使用对象的内存地址当它的key。管理引用计数和weak指针就靠它了。 - 因为对象引用计数相关操作应该是原子性的。不然如果多个线程同时去写一个对象的引用计数,那就会造成数据错乱,失去了内存管理的意义。同时又因为内存中对象的数量是非常非常庞大的需要非常频繁的操作SideTables,所以不能对整个Hash表加锁。苹果采用了分离锁技术。
分离锁和分拆锁的区别
降低锁竞争的另一种方法是降低线程请求锁的频率。分拆锁 (lock splitting) 和分离锁 (lock striping) 是达到此目的两种方式。相互独立的状态变量,应该使用独立的锁进行保护。有时开发人员会错误地使用一个锁保护所有的状态变量。这些技术减小了锁的粒度,实现了更好的可伸缩性。但是,这些锁需要仔细地分配,以降低发生死锁的危险。
如果一个锁守护多个相互独立的状态变量,你可能能够通过分拆锁,使每一个锁守护不同的变量,从而改进可伸缩性。通过这样的改变,使每一个锁被请求的频率都变小了。分拆锁对于中等竞争强度的锁,能够有效地把它们大部分转化为非竞争的锁,使性能和可伸缩性都得到提高。
分拆锁有时候可以被扩展,分成若干加锁块的集合,并且它们归属于相互独立的对象,这样的情况就是分离锁。
SideTables其实就是一个全局的哈希桶
static StripedMap& SideTables() {
return *reinterpret_cast*>(SideTableBuf);
}
SideTables() 方法返回的是一个 StripedMap 类型的引用:
template
class StripedMap {
#if TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
enum { StripeCount = 8 };
#else
enum { StripeCount = 64 };
#endif
struct PaddedT {
T value alignas(CacheLineSize);
};
PaddedT array[StripeCount];
static unsigned int indexForPointer(const void *p) {
uintptr_t addr = reinterpret_cast(p);
return ((addr >> 4) ^ (addr >> 9)) % StripeCount;
}
public:
T& operator[] (const void *p) {
return array[indexForPointer(p)].value;
}
const T& operator[] (const void *p) const {
return const_cast>(this)[p];
}
......
};
StripedMap是一个模板类, 内部维护一个大小为StripeCount的数组, 数组的成员为结构体PaddedT,PaddedT结构体只有一个成员value,value的类型是T.- 综上所述:
SideTables()返回的StripedMap, 是一个value为SideTable的哈希桶(由于SideTable内部又在维护数组, 所以这是一个哈希桶结构), 哈希值由对象的地址计算得出.
SideTable
当我们通过SideTables[key]来得到SideTable的时候,SideTable的结构如下:
struct SideTable {
spinlock_t slock;//自旋锁
RefcountMap refcnts;//存放引用计数
weak_table_t weak_table;//weak_table是一个哈希
......
};
spinlock_t:自旋锁
- 自旋锁
自旋锁比较适用于锁使用者保持锁时间比较短的情况。正是由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用,而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。
- 作用:在操作引用计数的时候对
SideTable加锁,避免数据错误
RefcountMap:存放引用计数
typedef objc::DenseMap,size_t,true> RefcountMap;
- DenseMap又是一个模版类
template >
class DenseMap
: public DenseMapBase,
KeyT, ValueT, KeyInfoT, ZeroValuesArePurgeable> {
typedef DenseMapBase BaseT;
typedef typename BaseT::BucketT BucketT;
friend class DenseMapBase;
BucketT *Buckets;
unsigned NumEntries;
unsigned NumTombstones;
unsigned NumBuckets;
};
列举几个比较重要的成员变量:
ZeroValuesArePurgeable默认值是false,但RefcountMap指定其初始化为true. 这个成员标记是否可以使用值为 0 (引用计数为 1) 的桶. 因为空桶存的初始值就是 0, 所以值为 0 的桶和空桶没什么区别. 如果允许使用值为 0 的桶, 查找桶时如果没有找到对象对应的桶, 也没有找到墓碑桶, 就会优先使用值为 0 的桶.Buckets指针管理一段连续内存空间, 也就是数组, 数组成员是BucketT类型的对象, 我们这里将BucketT对象称为桶(实际上这个数组才应该叫桶, 苹果把数组中的元素称为桶应该是为了形象一些, 而不是哈希桶中的桶的意思). 桶数组在申请空间后, 会进行初始化, 在所有位置上都放上空桶(桶的key为EmptyKey时是空桶), 之后对引用计数的操作, 都要依赖于桶.umEntries记录数组中已使用的非空的桶的个数.NumTombstones,Tombstone直译为墓碑, 当一个对象的引用计数为0, 要从桶中取出时, 其所处的位置会被标记为Tombstone.NumTombstones就是数组中的墓碑的个数. 后面会介绍到墓碑的作用.NumBuckets桶的数量, 因为数组中始终都充满桶, 所以可以理解为数组大小
为什么Hash以后还需要个Map?其实苹果采用的是分块化的方法。
举个例子
假设现在内存中有16个对象。
0x0000、0x0001、… 0x000e、0x000f
咱们创建一个SideTables[8]来存放这16个对象,那么查找的时候发生Hash冲突的概率就是八分之一。
假设SideTables[0x0000]和SideTables[0x0x000f]冲突,映射到相同的结果。SideTables[0x0000] == SideTables[0x0x000f] ==> 都指向同一个SideTable苹果把两个对象的内存管理都放到里同一个SideTable中。你在这个SideTable中需要再次调用table.refcnts.find(0x0000)或者*table.refcnts.find(0x000f)*来找到他们真正的引用计数器。
这里是一个分流。内存中对象的数量实在是太庞大了我们通过第一个Hash表只是过滤了第一次,然后我们还需要再通过这个Map才能精确的定位到我们要找的对象的引用计数器。
-
引用计数结构
bucketT实际上是std::pair,类似于isa,使用其中几个bit来保存引用计数,留出几个bit用来做其他标记位-
(1UL<<0) WEAKLY_REFERENCED
表示是否有弱引用指向这个对象,如果有的话(值为1)在对象释放的时候需要把所有指向它的弱引用都变成nil(相当于其他语言的NULL),避免野指针错误。
-
(1UL<<1) DEALLOCATING
表示对象是否正在被释放。1正在释放,0没有。
-
REAL COUNT
REAL COUNT的部分才是对象真正的引用计数存储区。所以咱们说的引用计数加一或者减一,实际上是对整个unsigned long加四或者减四,因为真正的计数是从2^2位开始的。
-
(1UL<<(WORD_BITS-1)) SIDE_TABLE其中WORD_BITS
在32位和64位系统的时候分别等于32和64。随着对象的引用计数不断变大。如果这一位都变成1了,就表示引用计数已经最大了不能再增加了。_RC_PINNED
-
RefcountMap工作逻辑
- 过计算对象地址的哈希值, 来从
SideTables中获取对应的SideTable. 哈希值重复的对象的引用计数存储在同一个SideTable里. SideTable使用find()方法和重载 [] 运算符的方式, 通过对象地址来确定对象对应的桶. 最终执行到的查找算法是LookupBucketFor().
template
bool LookupBucketFor(const LookupKeyT &Val,
const BucketT *&FoundBucket) const {
const BucketT *BucketsPtr = getBuckets();
const unsigned NumBuckets = getNumBuckets();
//如果桶的个数是0
if (NumBuckets == 0) {
FoundBucket = 0;
return false;//返回false,回上层调用添加函数
}
// FoundTombstone - Keep track of whether we find a tombstone or zero value while probing.
const BucketT *FoundTombstone = 0;
const KeyT EmptyKey = getEmptyKey();
const KeyT TombstoneKey = getTombstoneKey();
assert(!KeyInfoT::isEqual(Val, EmptyKey) &&
!KeyInfoT::isEqual(Val, TombstoneKey) &&
"Empty/Tombstone value shouldn't be inserted into map!");
unsigned BucketNo = getHashValue(Val) & (NumBuckets-1);//将哈希值与数组最大下标按位与
unsigned ProbeAmt = 1;//哈希值重复的对象需要靠它来重新寻找位置
while (1) {
const BucketT *ThisBucket = BucketsPtr + BucketNo;//头指针+下标,类似于数组取值
//找到桶中的key和对象地址相等,则是找到了
if (KeyInfoT::isEqual(Val, ThisBucket->first)) {
FoundBucket = ThisBucket;
return true;
}
//找到的桶中的key是空桶占位符,则表示可插入
if (KeyInfoT::isEqual(ThisBucket->first, EmptyKey)) {
if (FoundTombstone) ThisBucket = FoundTombstone;//如果曾遇到墓碑,则使用墓碑的位置
FoundBucket = FoundTombstone ? FoundTombstone : ThisBucket;//找到空占位符,则表明表中没有已经插入了该对象的桶
return false;
}
//如果找到了墓碑
if (KeyInfoT::isEqual(ThisBucket->first, TombstoneKey) && !FoundTombstone)
FoundTombstone = ThisBucket; //记录下墓碑
//这里涉及到最初定义 typedef objc::DenseMap,size_t,true> RefcountMap, 传入的第三个参数 true
//这个参数代表是否可以清除 0 值, 也就是说这个参数为 true 并且没有墓碑的时候, 会记录下找到的 value 为 0 的桶
if (ZeroValuesArePurgeable &&
ThisBucket->second == 0 && !FoundTombstone)
FoundTombstone = ThisBucket;
//用于计数的ProbeAmt如果大于数组容量,就会抛出异常
if (ProbeAmt > NumBuckets) {
_objc_fatal("Hash table corrupted. This is probably a memory error "
"somewhere. (table at %p, buckets at %p (%zu bytes), "
"%u buckets, %u entries, %u tombstones, "
"data %p %p %p %p)",
this, BucketsPtr, malloc_size(BucketsPtr),
NumBuckets, getNumEntries(), getNumTombstones(),
((void**)BucketsPtr)[0], ((void**)BucketsPtr)[1],
((void**)BucketsPtr)[2], ((void**)BucketsPtr)[3]);
}
BucketNo += ProbeAmt++;//本次哈希计算得出的下标不符合,则利用ProbeAmt寻找下一个下标
BucketNo&= (NumBuckets-1);//得到新的数字和数组下标按最大值按位与
}
}
- 下面我们通过画图的方式来展示上述代码的流程:这里引用小新0541的神作

首先我们有一个初始化好的, 大小为 9 的桶数组, 同时有 a b c d e 五个对象要使用桶数组, 这里我们假设五个对象都被哈希算法分配到下标 0 的位置里. a 第一个进入, 但 b c d e 由于下标 0 处已经不是空桶, 则需要进行下一步哈希算法来查找合适的位置, 假设这 4 个对象又恰巧都被分配到了下标为 1 的位置, 但只有 b 可以存入. 假设每一次哈希计算都只给下标增加了 1, 以此类推我们能得到:

假设这个时候 c 对象被释放了, 之前提到过这个时候会把对应的位置的 key 设置为 TombstoneKey:

接下来就体现了墓碑的作用:
- 如果 c 对象销毁后将下标 2 的桶设置为空桶, 此时为 e 对象增加引用计数, 根据哈希算法查找到下标为 2 的桶时, 就会直接插入, 无法为已经在下标为 4 的桶中的 e 增加引用计数.
- 如果此时初始化了一个新的对象 f, 根据哈希算法查找到下标为 2 的桶时发现桶中放置了墓碑, 此时会记录下来下标 2. 接下来继续哈希算法查找位置, 查找到空桶时, 就证明表中没有对象 f, 此时 f 使用记录好的下标 2 的桶而不是查找到的空桶, 就可以利用到已经释放的位置.
- 插入对象引用计数流程
BucketT *InsertIntoBucketImpl(const KeyT &Key, BucketT *TheBucket) {
//如果哈希表的负载大于3/4,则扩展该表。
//如果只有不到1/8的桶是空的(这意味着许多桶都是由tombstone填充的),则重新哈希表而不增加。
//后一种情况比较棘手。例如,如果我们有一个空桶,有大量的tombstone,失败的查找(例如插入)将不得不探查几乎整个表,直到它找到空桶为止。如果表中完全填满了tombstone,则不会成功进行任何查找,从而导致无限循环的查找。
unsigned NewNumEntries = getNumEntries() + 1;//桶的使用量+1
unsigned NumBuckets = getNumBuckets();//桶的总数
if (NewNumEntries*4 >= NumBuckets*3) {//使用量超过3/4
this->grow(NumBuckets * 2);//数组大小*2做参数,grow中会决定具体数值
//grow中会重新布置所有桶的位置,所以将要插入的对象也要重新定位
LookupBucketFor(Key, TheBucket);
NumBuckets = getNumBuckets();//获取最新数组的大小
}
//如果空桶数量小于1/8,哈希查找会很难定位到空桶的位置
if (NumBuckets-(NewNumEntries+getNumTombstones()) <= NumBuckets/8) {
//grow以原大小重新开辟空间,重新安排桶的位置并能清楚墓碑
this->grow(NumBuckets);
LookupBucketFor(Key, TheBucket);//重新布局后将要插入的对象也要重新确定位置
}
assert(TheBucket);
//找到的BucketT标记了EmptyKey,可以直接使用
if (KeyInfoT::isEqual(TheBucket->first, getEmptyKey())) {
//桶数量+1
incrementNumEntries();
}
//如果找的是墓碑
else if (KeyInfoT::isEqual(TheBucket->first, getTombstoneKey())) {
incrementNumEntries();//桶的使用量+1
decrementNumTombstones();//墓碑数量-1
}
//如果找到的位置是value为0的位置
else if (ZeroValuesArePurgeable && TheBucket->second == 0) {
// Purging a zero. No accounting changes.
TheBucket->second.~ValueT();
} else {
// Updating an existing entry. No accounting changes.
}
return TheBucket;
}
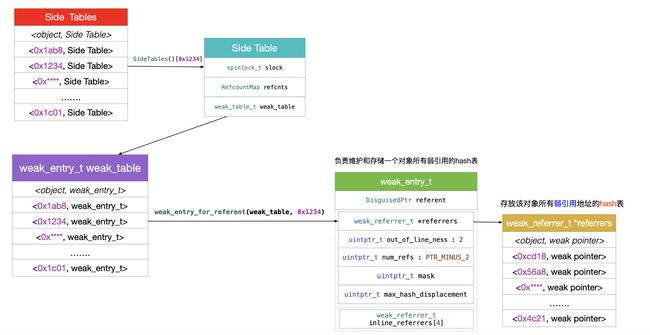
weak_table_t:维护weak指针
weak_table是一个哈希表的结构, 根据weak指针指向的对象的地址计算哈希值, 哈希值相同的对象按照下标 +1 的形式向后查找可用位置, 是典型的闭散列算法
struct weak_table_t {
weak_entry_t *weak_entries;//连续地址空间的头指针,数组
size_t num_entries;//数组中已经占用位置的个数
uintptr_t mask;//数组下标最大值(即数组大小-1)
uintptr_t max_hash_displacement;//最大哈希偏移值
};
weak_entry_t
struct weak_entry_t {
DisguisedPtr referent;//对象的地址
union {//这里是一个联合体
struct {
//因为这里要存储的又是一个weak指针数组,所以采用哈希算法
weak_referrer_t *referrers;//指向referent对象的weak指针数组
uintptr_t out_of_line_ness : 2;//这里标记是否超过内联边界
uintptr_t num_refs : PTR_MINUS_2;//数组中已占用的大小
uintptr_t mask;//数组下标最大值(数组大小-1)
uintptr_t max_hash_displacement;//最大哈希偏移值
};
struct {
//这是一个取名急哦啊内联引用的数组
weak_referrer_t inline_referrers[WEAK_INLINE_COUNT];//宏定义的值是4
};
};
bool out_of_line() {
return (out_of_line_ness == REFERRERS_OUT_OF_LINE);
}
weak_entry_t& operator=(const weak_entry_t& other) {
memcpy(this, &other, sizeof(other));
return *this;
}
weak_entry_t(objc_object *newReferent, objc_object **newReferrer)
: referent(newReferent)
{
inline_referrers[0] = newReferrer;
for (int i = 1; i < WEAK_INLINE_COUNT; i++) {
inline_referrers[i] = nil;
}
}
};
- 我们通过对象的地址, 可以在
weak_table_t中找到对应的weak_entry_t,weak_entry_t中保存了所有指向这个对象的weak指针. - 当指向这个对象的
weak指针不超过 4 个, 则直接使用数组inline_referrers, 省去了哈希操作的步骤, 如果weak指针个数超过了 4 个, 就要使用第一个结构体中的哈希表. - 下面我们用一张图来看看,
weak_table表是什么样的结构
- 接着我们再来看看SideTables整体结构
weak_table_t 的工作逻辑
初始化weak指针
- 在
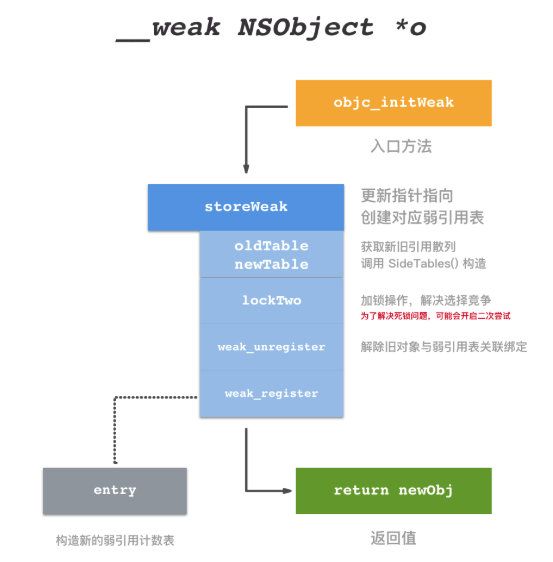
ARC下, 编译器会自动添加管理引用计数的代码,weak指针赋值的时候, 编译器会调用storeWeak来赋值, 若weak指针有指向的对象, 那么会先调用weak_unregister_no_lock()方法来从原有的表中先删除这个weak指针, 然后再调用weak_register_no_lock()来向对应的表中插入这个weak指针.
id
objc_initWeak(id *location, id newObj)
{
//查看对象实例是否有效
//无效对象直接导致指针释放
if (!newObj) {
*location = nil;
return nil;
}
return storeWeak
(location, (objc_object*)newObj);
}
- 通过上面方法进行给
weak指针赋值,最终会调用storeWeak
// HaveOld: true - 变量有值
// false - 需要被及时清理,当前值可能为 nil
// HaveNew: true - 需要被分配的新值,当前值可能为 nil
// false - 不需要分配新值
// CrashIfDeallocating: true - 说明 newObj 已经释放或者 newObj 不支持弱引用,该过程需要暂停
// false - 用 nil 替代存储
template
static id
storeWeak(id *location, objc_object *newObj)
{
assert(haveOld || haveNew);
if (!haveNew) assert(newObj == nil);
// 该过程用来更新弱引用指针的指向
// 初始化 previouslyInitializedClass 指针
Class previouslyInitializedClass = nil;
id oldObj;
SideTable *oldTable;
SideTable *newTable;
//模板函数, haveOld 和 haveNew 由编译器决定传入的值, location 是 weak 指针, newObj 是 weak 指针将要指向的对象
retry:
if (haveOld) {
//更改指针,获得以oldObj 为索引所存储的值地址
oldObj = *location;
oldTable = &SideTables()[oldObj];
} else {
oldTable = nil;
}
if (haveNew) {
// 更改新值指针,获得以 newObj 为索引所存储的值地址
newTable = &SideTables()[newObj];
} else {
newTable = nil;
}
// 加锁操作,防止多线程中竞争冲突
SideTable::lockTwo(oldTable, newTable);
// 避免线程冲突重处理
// location 应该与 oldObj 保持一致,如果不同,说明当前的 location 已经处理过 oldObj 可是又被其他线程所修改
if (haveOld && *location != oldObj) {
SideTable::unlockTwo(oldTable, newTable);
goto retry;
}
// 防止弱引用间死锁
// 并且通过 +initialize 初始化构造器保证所有弱引用的 isa 非空指向
if (haveNew && newObj)
// 获得新对象的 isa 指针
Class cls = newObj->getIsa();
// 判断 isa 非空且已经初始化
if (cls != previouslyInitializedClass &&
!((objc_class *)cls)->isInitialized())
{
SideTable::unlockTwo(oldTable, newTable);
// 对其 isa 指针进行初始化
_class_initialize(_class_getNonMetaClass(cls, (id)newObj));
// 如果该类已经完成执行 +initialize 方法是最理想情况
// 如果该类 +initialize 在线程中
// 例如 +initialize 正在调用 storeWeak 方法
// 需要手动对其增加保护策略,并设置 previouslyInitializedClass 指针进行标记
previouslyInitializedClass = cls;
// 重新尝试
goto retry;
}
}
if (haveOld) {
//如果weak指针有旧值,则需要在weak_table中处理掉旧值
weak_unregister_no_lock(&oldTable->weak_table, oldObj, location);
}
if (haveNew) {
//如果weak指针将要指向新值,在weak_table中处理赋值操作
newObj = (objc_object *)
weak_register_no_lock(&newTable->weak_table, (id)newObj, location,
crashIfDeallocating);
// 如果弱引用被释放 weak_register_no_lock 方法返回 nil
// 在引用计数表中设置若引用标记位
if (newObj && !newObj->isTaggedPointer()) {
// 弱引用位初始化操作
// 引用计数那张散列表的weak引用对象的引用计数中标识为weak引用
newObj->setWeaklyReferenced_nolock();
}
// 之前不要设置 location 对象,这里需要更改指针指向
*location = (id)newObj;
}
else {
// 没有新值,则无需更改
}
SideTable::unlockTwo(oldTable, newTable);
return (id)newObj;
}
- 如果weak指针有旧值,则需要在weak_table中处理掉旧值,就需要用到
weak_unregister_no_lock方法
void
weak_unregister_no_lock(weak_table_t *weak_table, id referent_id, id *referrer_id)
{
objc_object *referent = (objc_object *)referent_id;//weak指针指向的对象
objc_object **referrer = (objc_object **)referrer_id;//referrer_id是weak指针,操作时需要用到这个指针
weak_entry_t *entry;
if (!referent) return;
if ((entry = weak_entry_for_referent(weak_table, referent))) {//查找referent对象对应的entry
remove_referrer(entry, referrer);//从referent 对应的 entry 中删除地址为 referrer 的 weak 指针
bool empty = true;
if (entry->out_of_line() && entry->num_refs != 0) {//如果 entry 中的数组容量大于 4 并且数组中还有元素
empty = false;//entry 非空
} else {
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i]) {//否则循环查找 entry 数组, 如果 4 个位置中有一个非空
empty = false; //entry 非空
break;
}
}
}
if (empty) {//如果没有通过之前的查找逻辑, 则说明 entry 为空
weak_entry_remove(weak_table, entry);//从 weak_table 中移除该条 entry
}
}
}
//接着会调用weak_entry_remove方法
static void weak_entry_remove(weak_table_t *weak_table, weak_entry_t *entry)
{
if (entry->out_of_line()) free(entry->referrers); //如果 out_of_line(), 则需要 free 掉为 referrers alloc 的空间
bzero(entry, sizeof(*entry));//entry 所属空间清空
weak_table->num_entries--;//weak_table 中 entries 元素个数 -1
weak_compact_maybe(weak_table);//根据需要重新调整 weak_table 的空间
}
//如何重新调整weak_table空间
static void weak_compact_maybe(weak_table_t *weak_table) {
size_t old_size = TABLE_SIZE(weak_table);
//如果数组大小大于 1024, 但使用量小于 1/16 的话, 将数组进行收缩, 节省空间
if (old_size >= 1024 && old_size / 16 >= weak_table->num_entries) {
weak_resize(weak_table, old_size / 8); //收缩至原有大小的 1/8
//使用量小于 1/16, 收缩至 1/8 后, 使用量小于 1/2
}
}
- 如果
weak指针将要指向新值,在weak_table中处理赋值操作,需要运用weak_register_no_lock方法
id
weak_register_no_lock(weak_table_t *weak_table, id referent_id,
id *referrer_id, bool crashIfDeallocating)
{
objc_object *referent = (objc_object *)referent_id;
objc_object **referrer = (objc_object **)referrer_id;
if (!referent || referent->isTaggedPointer()) return referent_id;
// ensure that the referenced object is viable
bool deallocating;
if (!referent->ISA()->hasCustomRR()) {
deallocating = referent->rootIsDeallocating();
}
else {
BOOL (*allowsWeakReference)(objc_object *, SEL) =
(BOOL(*)(objc_object *, SEL))
object_getMethodImplementation((id)referent,
SEL_allowsWeakReference);
if ((IMP)allowsWeakReference == _objc_msgForward) {
return nil;
}
deallocating =
! (*allowsWeakReference)(referent, SEL_allowsWeakReference);
}
if (deallocating) {
if (crashIfDeallocating) {
_objc_fatal("Cannot form weak reference to instance (%p) of "
"class %s. It is possible that this object was "
"over-released, or is in the process of deallocation.",
(void*)referent, object_getClassName((id)referent));
} else {
return nil;
}
}
weak_entry_t *entry;
if ((entry = weak_entry_for_referent(weak_table, referent))) {//如果 weak_table 有对应的 entry
append_referrer(entry, referrer);//将 weak 指针存入对应的 entry 中
}
else {
weak_entry_t new_entry(referent, referrer);//创建新的 entry
weak_grow_maybe(weak_table);//查看是否需要调整 weak_table 中 weak_entries 数组大小
weak_entry_insert(weak_table, &new_entry);//将新的 entry 插入到 weak_table 中
}
return referent_id;
}
//通过调用append_referrer()方法将weak存入entry
static void append_referrer(weak_entry_t *entry, objc_object **new_referrer)
{
if (! entry->out_of_line()) {//如果数组大小没超过 4
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
if (entry->inline_referrers[i] == nil) {//循环查找数组成员
entry->inline_referrers[i] = new_referrer;//把新的 weak 指针插入到空位置
return;
}
}
//数组中的 4 个位置都非空, 就要调整策略使用 referrers 了
//从这里开始, 这一段是把 inline_referrers 数组调整为使用 referrers 的形式
weak_referrer_t *new_referrers = (weak_referrer_t *)
calloc(WEAK_INLINE_COUNT, sizeof(weak_referrer_t));//还是开辟 4 个 weak_referrer_t 大小的空间
for (size_t i = 0; i < WEAK_INLINE_COUNT; i++) {
new_referrers[i] = entry->inline_referrers[i];//将 inline_referrers 中的值赋值给 referrers
}
//配置 entry 结构
entry->referrers = new_referrers;
entry->num_refs = WEAK_INLINE_COUNT;
entry->out_of_line_ness = REFERRERS_OUT_OF_LINE;
entry->mask = WEAK_INLINE_COUNT-1;
entry->max_hash_displacement = 0;
}
assert(entry->out_of_line());
if (entry->num_refs >= TABLE_SIZE(entry) * 3/4) {//数组使用量超过 3/4
return grow_refs_and_insert(entry, new_referrer);//需要扩展数组并进行插入
}
//开始哈希算法
size_t begin = w_hash_pointer(new_referrer) & (entry->mask);
size_t index = begin;//使用哈希算法计算到一个起始下标
size_t hash_displacement = 0;//哈希偏移次数
while (entry->referrers[index] != nil) {//循环找空位置
hash_displacement++;//移位一次 +1
index = (index+1) & entry->mask;//从起始位置开始遍历, 对数组大小取模
if (index == begin) bad_weak_table(entry);//如果找了一圈, 证明算法出了点问题
}
//这里记录下移位的最大值, 那么数组里的任何一个数据, 存储时的移位次数都不大于这个值
//可以提升查找时的效率, 如果移位次数超过了这个值都没有找到, 就证明要查找的项不在数组中
if (hash_displacement > entry->max_hash_displacement) {
entry->max_hash_displacement = hash_displacement;
}
weak_referrer_t &ref = entry->referrers[index];
ref = new_referrer;
entry->num_refs++;//数组使用量 +1
}
- 下面我们用一张图来总结初始化weak指针的流程
weak指针置nil
当weak引用指向的对象被释放时,我们需要把指针置为nil
- 我们在前面已经讲解了,当一个对象释放时,需要调用
objc_release方法,如果引用计数为0时,会执行dealloc方法,在把weak指针置nil的过程会调用clearDeallocating
void
objc_clear_deallocating(id obj)
{
assert(obj);
if (obj->isTaggedPointer()) return;
obj->clearDeallocating();
}
- 在函数内部调用了
clearDeallocating函数
inline void
objc_object::clearDeallocating()
{
//如果是没有优化过的isa指针
if (slowpath(!isa.nonpointer)) {
// Slow path for raw pointer isa.
sidetable_clearDeallocating();
}
//是优化过的isa指针,并且是否有弱引用过,或者引用计数是否存在sideTable中
else if (slowpath(isa.weakly_referenced || isa.has_sidetable_rc)) {
// Slow path for non-pointer isa with weak refs and/or side table data.
clearDeallocating_slow();
}
assert(!sidetable_present());
}
- 不论我们是哪种方式,我们都会调用
weak_clear_no_lock方法
void
weak_clear_no_lock(weak_table_t *weak_table, id referent_id)
{
//1、拿到被销毁对象的指针
objc_object *referent = (objc_object *)referent_id;
//2、通过 指针 在weak_table中查找出对应的entry
weak_entry_t *entry = weak_entry_for_referent(weak_table, referent);
if (entry == nil) {
return;
}
//3、将所有的引用设置成nil
weak_referrer_t *referrers;
size_t count;
if (entry->out_of_line()) {
//3.1、如果弱引用超过4个则将referrers数组内的弱引用都置成nil。
referrers = entry->referrers;
count = TABLE_SIZE(entry);
}
else {
//3.2、不超过4个则将inline_referrers数组内的弱引用都置成nil
referrers = entry->inline_referrers;
count = WEAK_INLINE_COUNT;
}
//循环设置所有的引用为nil
for (size_t i = 0; i < count; ++i) {
objc_object **referrer = referrers[i];
if (referrer) {
if (*referrer == referent) {
*referrer = nil;
}
else if (*referrer) {
_objc_inform("__weak variable at %p holds %p instead of %p. "
"This is probably incorrect use of "
"objc_storeWeak() and objc_loadWeak(). "
"Break on objc_weak_error to debug.\n",
referrer, (void*)*referrer, (void*)referent);
objc_weak_error();
}
}
}
//4、从weak_table中移除entry
weak_entry_remove(weak_table, entry);
}