BBR, the new kid on the TCP block | APNIC Blog 这篇文章挺好的,下面很多内容也基于这篇文章而来。
拥塞避免用于避免因为发送者发送数据过快导致链路上因为拥塞而出现丢包。
TCP 连接建立后先经过 Slow Start 阶段,每收到一个 ACK,CWND 翻倍,数据发送率以指数形式增长,等出现丢包,或达到 ssthresh,或到达接收方 RWND 限制后进入 Congestion Avoidance 阶段。下面这个图挺好的,描述了好几个过程,找不到出处了,只是列一下图吧。
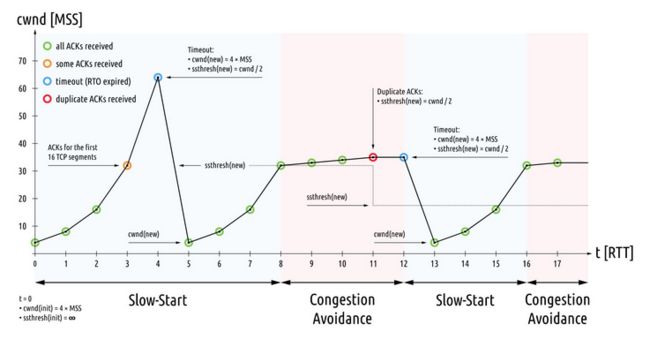
一些基础东西可以看:TCP congestion control - Wikipedia
BDP
BDP 是 Bandwidth and Delay Product. 就是带宽 (单位 bps) 和延迟 (单位 s) 的乘积,单位是 bit,也是 Source 和 Destination 之间允许处在 Flying 状态的最大数据量。Flying 也叫 Inflights,就是发送了但还未收到的 Ack 的数据。

来自[3]。
实际发送速率乘以延迟得到的值越接近 BDP 说明算法的效率越高。
Reno
Reno 这种叫做 ACK-Pacing,基于 Ack 来确认网络状况。如果能持续收到 ACK,表示网络能正常承载当前发送速率。
Reno maintains an estimate of the time to send a packet and receive the corresponding ACK (the “round trip time,” or RTT), and while the ACK stream is showing that no packets are being lost in transit, then Reno will increase the sending rate by one additional segment each RTT interval.
Reno 下,每收到一个 ACK,CWND 加一,等出现丢包之后发送者将发送速率减半。理想状况下,Reno 能走出如下曲线:

来自[1]
Reno 有如下假设:
- 丢包一定因为网络出现拥塞,但实际可能网络本身不好,可能有固有的丢包概率,所以假设并不严谨;
- 网络拥塞一定是因为网络上某个 buffer overflow 了;
- 网络的 RTT 和带宽稳定不容易变化;
- 将速率减半以后,网络上的 buffer 一定能够从 overflow 变为 drain。也即对网络上 Buffer 大小也有假设;
从上面假设能看出,Reno 下受链路上 Buffer 大小影响很大。当 Buffer 较小的时候,链路上实际处在发送状态的数据量还未达到 BDP (Bandwidth delay product) 时候可能就会出现丢包,导致 Reno 立刻减半发送速率,从而无法高效的利用网络带宽。如果 Buffer 很大,超过 BDP,可能会进入 “Buffer Bloat” 状态,即延迟畸高,因为即使 Reno 速度降为一半依然不能保证使链路 Buffer 清空,或者说可能大部分时间链路上 Buffer 都处在非空状态,且每次 Reno 因为丢包而降速时,会做数据重传,导致之前发送的可能还依旧在链路上排队的数据空占资源没起到作用最终白白丢掉,于是让整条链路上持续存在固有延迟。
Reno 的问题:
- 上面提到了,受链路 Buffer 影响很大;
- 对高带宽网络,比如带宽是 10Gbps,即使假设延迟非常低只有 30ms,每个 RTT 下 CWND 增加 1500 个八进制数,得好几个小时才能真的利用起这个带宽量,并且要求这几个小时内数据都不能有丢包,不然 Reno 会降速;
- Reno 每收到一个 Ack 就开始扩大 CWND,对链路上一起共享链路的其它 RTT 较大的连接不友好。比如一个连接 RTT 很低,它的 CWND 会比别的共享链路的连接大,不公平的占用更多带宽;
BIC
BIC 叫 Binary Increase Congestion Control,是在 Reno 基础上做改进,将 CWND 扩大过程分成三个阶段,第一阶段是在遇到丢包后将 CWND 降为 β × Wmax,(一般 β 是 0.5,Wmax 是丢包时 CWND)但记住之前 Wmax 最大值,之后以一个较快速度增加 CWND,在接近 Wmax 后 CWND 增加量是一个 Wmax 和 CWND 之间的二次函数,称为 Binary Increase,逐步去接近 Wmax,到达 Wmax 后又转换为二次曲线去探测下一个极限。具体内容可以看 Wiki,在这里:BIC TCP - Wikipedia
大概是这么个图,好处就是丢包后能快速恢复,并在稳定期尽力保持更长时间,并还能支持探测更高带宽值。

来自[3]
Cubic
Cubic 在 BIC 的基础上,一个是通过三次函数去平滑 CWND 增长曲线,让它在接近上一个 CWND 最大值时保持的时间更长一些,再有就是让 CWND 的增长和 RTT 长短无关,即不是每次 ACK 后就去增大 CWND,而是让 CWND 增长的三次函数跟时间相关,不管 RTT 多大,一定时间后 CWND 一定增长到某个值,从而让网络更公平,RTT 小的连接不能挤占 RTT 大的连接的资源。
平滑后的 CWND 和时间组成的曲线如下,可以看到三次曲线保留了 BIC 的优点,即在丢包后初期,CWND 能快速增长,减小丢包带来的影响;并且在接近上一个 CWND 最大值时 CWND 增长速度又会非常慢,要经历很长时间才能超越 Wmax,从而能尽力保持稳定,稳定在 Wmax 上;最后在超越 Wmax 后初期也是增长的非常慢,直到后来才快速的指数形式增长,用于探测下一个 Wmax。
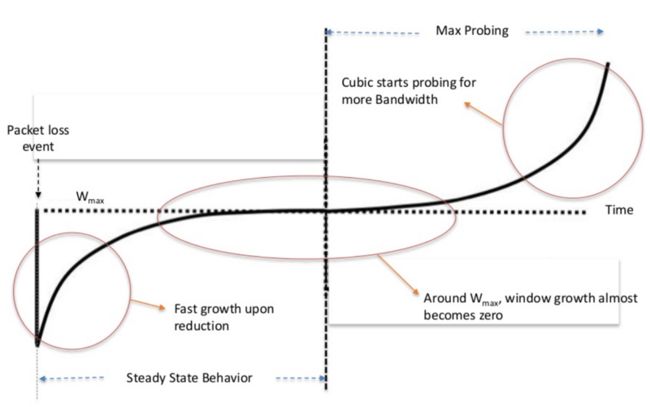
来自[3]
Cubic 最终出来的曲线如下。黄色是 CWND,蓝色线是网络上队列拥塞包数。蓝色箭头表示 queue fill,绿色箭头表示 queue drain。看到有两个浅绿色的线,高的是开始丢包,低的是队列开始排队。因为这里画的是说网络上 bandwidth 是固定的,buffer 也是固定的,所以 Cubic 下没有超越 Last Wmax 继续探测下一个 Wmax 的曲线,都是还未到达第一次的 Wmax 时候就因为丢包而被迫降低了 CWND。第一次个黄色尖峰能那么高是因为当时网络上 buffer 是空的,后来每次丢包后 Buffer 还没来得及完全清空 CWND 又涨上来导致数据排队了,所以后来的黄色尖峰都没有第一个高。
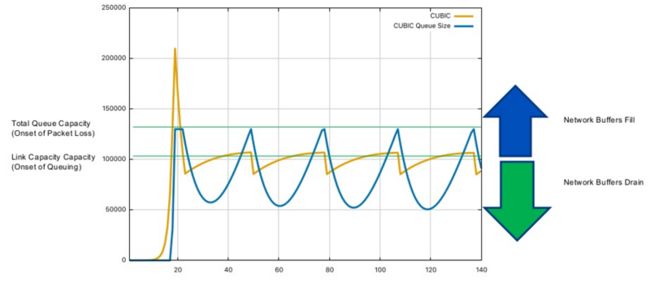
来自[3]
Cubic 的优势:
- 因为跟 RTT 无关所以更公平;
- 更适合 BDP 大的网络。Reno 不适合是因为它依赖 RTT,BDP 大的时候 RTT 如果很高,会很久才能将传输效率提上去;
Cubic 缺点:
- 当 Bandwidth 变化时候,Cubic 需要很长时间才能从稳定点进入探测下一个 Wmax 的阶段;
- 更易导致 Bufferbloat。Reno 下如果链路上 Buffer 很大出现拥塞后 RTT 也会很长,很久才会收到 ACK,才会增加 CWND;但 Cubic 的 CWND 增长跟 RTT 无关,到时间就增长,从而更容易加剧链路负担。Bufferbloat 可以看下节。
综合来看 Cubic 适合 BDP 大的高性能网络,性能意思是带宽或者说发送速率,发送速率足够大 Cubic 把 Buffer 占满后才能快速清空,才能有较低的延迟。
一个挺好的讲 Cubic 的 PPT:Cubic,还有论文。Linux 2.6 时候用的 CUBIC。
Bufferbloat
Bufferbloat 在 Bufferbloat - Wikipedia 讲的挺好了。简单说就是随着内存越来越便宜,链路上有些设备的 Buffer 倾向于配置的特别大,而流行的 TCP Congestion Avoidance 算法又是基于丢包的。数据在队列排队说明链路已经出现拥塞,本来应该立即反馈给发送端让发送端减小发送速度的,但因为 Buffer 很大,数据都在排队,发送端根本不知道自己发出去的数据已经开始排队,还在以某个速度 (Reno)甚至更高速度(Cubic,到时间就增加 CWND) 发送。等真的出现丢包时候,发送端依然不知道出现了丢包,还会快速发消息,直到丢的这个包被接收端感知到,回复 ACK 后发送端才终于知道要降低发送速度。而重传的包放在链路上还得等之前的数据包都送达接收端后才能被处理。如果接收端的 Buffer 不足够大,很多数据送达接收端后都会丢弃,得等重传的包到达(Head Of Line 问题)后才能送给上游,大大增加延迟。
Bufferbloat 一方面是会导致网络上超长的延迟,再有就是导致网络传输不稳定,有时候延迟很小,有的时候延迟又很大等。
可以参考:Bufferbloat: Dark Buffers in the Internet - ACM Queue
PRR
在 CUBIC 之上又有个优化,叫做 Proportional Rate Reduction (PRR),用以让 CUBIC 这种算法在遇到丢包时候能更快的恢复到当前 CWND 正常值,而不过分的降低到过低的水平。
参考:draft-mathis-tcpm-proportional-rate-reduction-01 - Proportional Rate Reduction for TCP。不进一步记录了。Linux 3.X 的某个版本引入的,配合 CUBIC 一起工作。
链路上的队列模型
为了进一步优化 Cubic,可以先看看链路上队列的模型。
- 当链路上数据较少时,所有数据都在发送链路上进行发送,没有排队的数据。这种情况下延迟最低;
- 当传输的数据更多时候,数据开始排队,延迟开始增大;
- 当队列满的时候进入第三个状态,队列满了出现丢包;
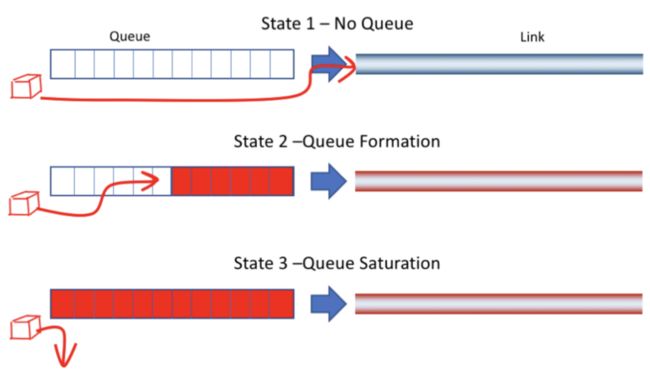
来自[1]
最优状态是 State 1 和 State 2 之间,即没有出现排队导致延迟升高,又能完全占满链路带宽发送数据,又高效延迟又低。
而基于丢包的 Congestion Avoidance 策略都是保持在 State 2 的状态。而 Cubic 是让 CWND 尽可能保持在上一个 Wmax 的状态,也即 State 2 末尾和即将切换到 State 3 的状态。所以 Cubic 相当于尽可能去占用链路资源,使劲发数据把下游链路占满但牺牲了延迟。
于是可以看到,为了保持在 State 1 和 State 2 状态,我们可以监控每个数据包的 RTT,先尽力增大 CWND 提高发送率如果发现发送速率提高后 RTT 没有升高则可以继续提高发送速率,直到对 RTT 有影响时就减速,说明从 State 1 切换到了 State 2。
我们希望让 CWND 尽力保持在下面图中标记为 optimum operating point的点上,即 RTT 又小,链路上带宽又被占满。在这个图上,RTprop 叫做 round-trip propagation time,BtlBw 叫做 bottleneck bandwidth。横轴是 inflights 数据量,纵轴有两个一个是 RTT 一个是送达速度。看到图中间有个很淡很淡的黄色的线把图分成了上下两部分,上半部分是 Inflights 数据量和 Round trip time 的关系。下半部分是 Inflights 和 Delivery Rate 的关系。
这里有四个东西需要说一下 CWND、发送速度、inflights,发送者带宽。inflights 就是发送者发到链路中还未收到 ACK 的数据量,发送速度是发送者发送数据的速度,发送者带宽是发送者能达到的最大发送速度,CWND 是根据拥塞算法得到的当前允许的 inflights 最大数据量,它也影响着发送速度。比如即使有足够大的带宽,甚至有足够多的数据要发,但 CWND 不够,于是只能降低发送速度。这么几个东西会纠缠在一起,有很多文章在描述拥塞算法的时候为了方便可能会将这几个东西中的某几个混淆在一起描述,看的时候需要尽力心里有数。
回到图蓝色的线表示 CWND 受制于 RTprop,绿色的线表示受制于 BltBw。灰色区域表示不可能出现的区域,至少会受到这两个限制中的一个影响。白色区域正常来说也不会出现,只是说理论上有可能出现,比如在链路上还有其它发送者一起在发送数据相互干扰等。灰色区域是无论如何不会出现。
先看上半部分,Inflights 和 Round-Trip Time 的关系,一开始 Inflights 数据量小,RTT 受制于链路固有的 RTprop 时间影响,即使链路上 Buffer 是空的 RTT 也至少是 RTprop。后来随着 Inflights 增大到达 BDP 之后,RTT 开始逐步增大,斜率是 1/BtlBw,因为 BDP 点右侧蓝色虚线就是 Buffer 大小,每个蓝点对应的纵轴点就是消耗完这么大 Buffer 需要的时间。消耗 Buffer 的时间 / Buffer 大小 就是 1/BltBw,因为消耗 Buffer 的时间乘以 BltBw 就是 Buffer 大小。感觉不好描述,反正就这么理解一下吧。主要是看到不可能到灰色部分,因为发送速率不可能比 BltBw 大。等到 Inflights 把 Buffer 占满后到达红色区域开始丢包。
下半部分,Inflights 比较小,随着 Inflights 增大 Delivery Rate 越大,因为此时还未达到带宽上限,发的数据越多到达率也就越高。等 Inflights 超过 BDP 后,Delivery Rate 受制于 BtlBw 大小不会继续增大,到达速度达到上限,Buffer 开始积累。当 Buffer 达到最大限度后,进入红色区域开始丢包。
之前基于丢包的拥塞算法实际上就是和链路 Buffer 一起配合控制 Inflights 数据量在 BDP 那条线后面与 BDP 线的距离。以前内存很贵,可能只比 BDP 大一点,基于丢包的算法延迟就不会很高,可能比最优 RTT 高一点。但后来 Buffer 越来越便宜,链路上 Buffer 就倾向于做的很大,此时基于丢包的拥塞算法就容易导致实际占用的 Buffer 很大,就容易出现 BufferBloat。
为了达到最优点,发送速率必须达到 BltBw,从而占满链路带宽,最高效的利用带宽;再有需要控制 Inflight 数据量不能超过链路的 BDP = BtlBw * RTprop,从而有最优的延迟。发送速率可以超过 BltBw,可以有队列暂时产生,但数据发送总量不能超 BDP,从而让平均下来延迟还是能在最优点附近。

来自[4]
TCP Vegas
Vegas 就如上面说的理想中算法一样,它会监控 RTT,在尝试增加发送速率时如果发现丢包或者 RTT 增加就降低发送速率,认为网络中出现拥塞。但它有这些问题:
- CWND 增长是线性的,跟 Reno 一样需要很久才能很好的利用网络传输速率;
- 最致命的是它不能很好的跟基于丢包的 Congestion Avoidance 共存,因为这些算法是让队列处在 State 2 和 3 之间,即尽可能让队列排队,也相当于尽可能的增大延迟,但 Vegas 是尽可能不排队,一发现排队就立即降低发送速率,所以 Vegas 和其它基于丢包算法共存时会逐步被挤出去;
参考文献在下一篇统一提供。
其他分享内容:
更多内容欢迎关注 LeanCloud 官方微信号:「LeanCloud 通讯」