zookeeper详解
定义:
zookeeper开源,他是一个分布式协调服务
数据模型:
1.每一个节点都称之为 znode,它可以有子节点,也可以有数据;
2.每个节点分为临时节点和永久节点,临时节点在客户端断开后消失;
3.每个 zk 节点都有各自的版本号,可以通过命令(get path)来显示节点信息;
4.每当节点数据发生变化,那么该节点的版本号会累加(乐观锁);
5.删除/修改过时的节点,版本号不匹配则会报错;
6.每个 zk 节点存储的数据不宜过大,几 kb 即可;
7.节点可以设置权限 acl(权限控制列表),可以通过权限来限制用户的访问;
疑惑:
我们在配置zookeeper时候,曾经都会有一个这样的问题,2888:3888到底是什么,
1.2888:提供zookeeper对外通信的接口
2.3888:当主节点挂掉之后,重新选择的leader对外通信的接口
zookeeper特性
| zookeerper的基本特性 | 我的理解 |
|---|---|
| 最终一致性 | 及时在写入的过程中有节点连接不上,当恢复的时候还会把节点上写入数据 |
| 原子性 | 事务要么成功要么失败,不会局部化 |
| 单一视图 | 客户端连接集群中任意一个节点,数据都是一样的 |
| 可靠性 | 每次对集群的操作状态都会保存在服务端 |
| 实时性 | 客户端可以读取到服务端的最新数据 |
zookeeper各种角色
| 角色 | 状态 |
|---|---|
| leader | leading 继承人,准备继承 |
| follower | following 追随者,但是有当国王的想法 |
| observer | observering–监视leader |
| looking–观望(leader挂掉了或者集群刚启动) |
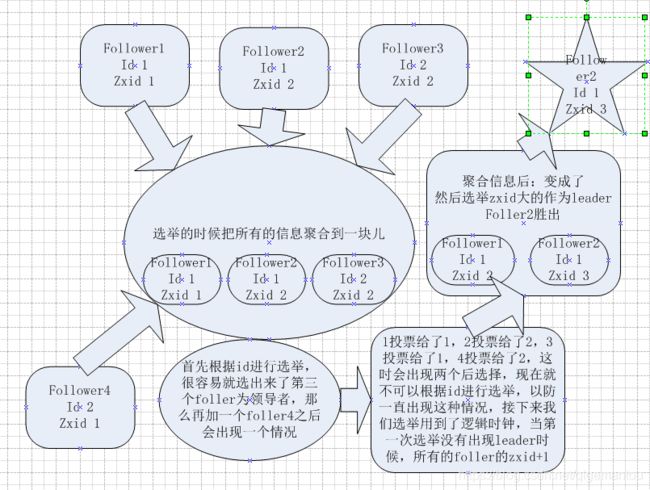
选举机制(过半原则)
当集群刚启动或者leader猝死的时候(猝死的时候触发了observer),需要进行选举来指定一个leader进行对外通信,
下面是理解图
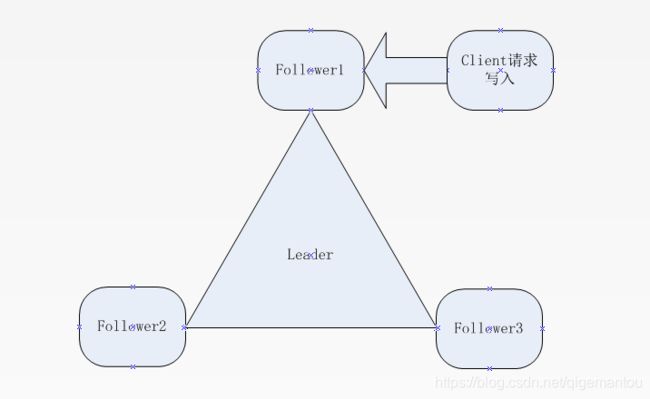
原子广播:
1.一个客户端写入请求,将请求传给follwer
2.folloer将请求传给leader
3.leader将请求下发给各个follower,进行投票
4.follower将自己的想法返回给leader
5.leader根据follower的想法判断是否操作以及分发任务
注意:少数服从多数,
原则:过半原则
zab协议
广播模式—已经选举出来的leader对外提供服务=------=原子广播
恢复模式-–还没有leader
详情参照选举机制
此时集群内节点的状态有:
looking ,following, leading, observing
详情参照各个角色
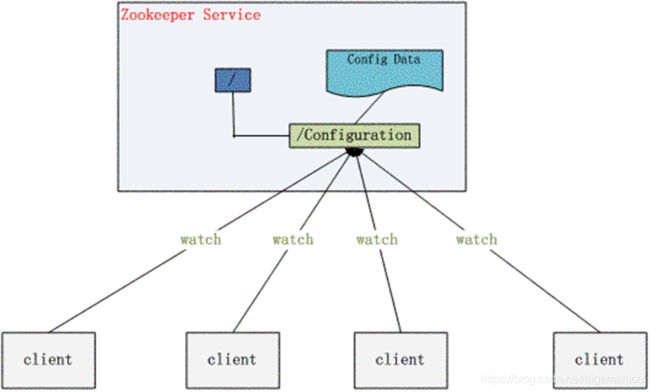
监听机制
watcher 是针对每个节点操作的监督者;
当监控的某个 znode 发生了变化,则触发 watcher 事件;
在 zk 中的 watcher 是一次性的,触发后,当前的 watcher 事件立即被销毁(注意 zk 客户端 zkclient 和 curator 解决了这个问题,watcher 是可以反复注册的);
三大高级特性
1.CreateMode
在create的时候可以设置znode的类型
主要有四种:
PERSISTENT (持续的,相对于EPHEMERAL,不会随着client的断开而消失)
PERSISTENT_SEQUENTIAL(持久的且带顺序的)
EPHEMERAL (短暂的,生命周期依赖于client session)
EPHEMERAL_SEQUENTIAL (短暂的,带顺序的)
2.Watcher
Watcher是一种反向推送机制,即zonde(包括他的child)有改变的时候会通知客户端。
可以自定义Watcher,注册给zonde。
watcher分为两大类:data watches和child watches。前者监听数据的变动,后者监听子node的变动。
Watcher是一次性的!一旦被调用,则需要重新注册。
3.ACL
acl即access control。zookeeper通过ACL机制来控制权限。创建znode的时候可以指定。一套zookeeper会被多个程序使用。就像linux支持多用户一样。所以需要有一套权限控制;
Zookeeper的权限级别:
READ: 允许获取该节点的值和列出子节点。
WRITE: 允许设置该节点的值。
CREATE: 允许创建子节点。
DELETE: 可以删除子节点。
ADMIN: 超级权限。相当于root
从上到下递次增强,后面的权限包含前面的权限。
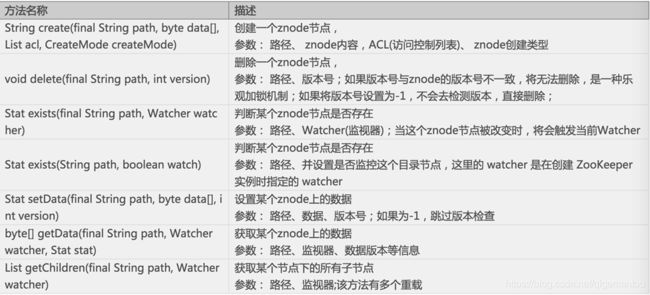
zookeeper客户端对象方法列举
创建客户端连接对象
创建监听类
public class Azooke implements Watcher{
@Override
public void process(WatchedEvent effe) {
System.out.println(effe.getPath());
System.out.println("asdfaf---------"+effe.getState());
}
}
创建连接类并实现方法
public static void main(String[] args) throws Exception {
//创建客户端连接
ZooKeeper zooKeeper = new ZooKeeper("192.168.205.142:2181", 1000, new Azooke());
//创建节点
zooKeeper.create("/zooker", "asdf".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
//如果该节点存在则删除
if (zooKeeper.exists("/zooker", new Azooke()) != null) {
zooKeeper.delete("/zooker", -1);
}
//设置节点属性
zooKeeper.setData("/zooker", "sdfsfsesfe".getBytes(), zooKeeper.exists("/zooker", new Azooke()).getVersion());
//获取子节点
zooKeeper.getChildren("/zooker", new Azooke());
}