本地运行yarn实现wordcount报错Exit code: 1 Exception message: /bin/bash: 第 0 行:fg: 无任务控制 Stack trace: ExitCo
eclipse控制台输出错误信息
Container id: container_1531823680410_0003_02_000001
Exit code: 1
Exception message: /bin/bash: 第 0 行:fg: 无任务控制
Stack trace: ExitCodeException exitCode=1: /bin/bash: 第 0 行:fg: 无任务控制
at org.apache.hadoop.util.Shell.runCommand(Shell.java:972)
at org.apache.hadoop.util.Shell.run(Shell.java:869)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:1170)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:236)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:305)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:84)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Container exited with a non-zero exit code 1
For more detailed output, check the application tracking page: http://master:8088/cluster/app/application_1531823680410_0003 Then click on links to logs of each attempt.
. Failing the application.
[INFO ] 2018-07-17 20:11:34,978 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1436)
Counters: 0
原因:因为在wondows系统中无法使用#!/bin/bash 平台兼容性的问题的
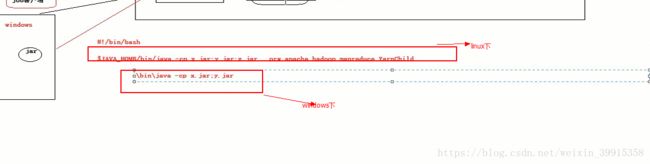
1:解决:打成jar包放在linux下运行。ok
2:跨平台提交的参数
//:如果要从windows系统中运行这个job提交客户端的程序,则需要加这个跨平台提交的参数
conf.set("mapreduce.app-submission.cross-platform","true");
如果打成jar包提交到linux中去,跨平台提交的参数可以去掉
解决:

这里把代码粘一下:
WordcountMapper.java
package cn.edu360.mr.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* KEYIN :是map task读取到的数据的key的类型,是一行的起始偏移量Long
* VALUEIN:是map task读取到的数据的value的类型,是一行的内容String
*
* KEYOUT:是用户的自定义map方法要返回的结果kv数据的key的类型,在wordcount逻辑中,我们需要返回的是单词String
* VALUEOUT:是用户的自定义map方法要返回的结果kv数据的value的类型,在wordcount逻辑中,我们需要返回的是整数Integer
*
*
* 但是,在mapreduce中,map产生的数据需要传输给reduce,需要进行序列化和反序列化,而jdk中的原生序列化机制产生的数据量比较冗余,就会导致数据在mapreduce运行过程中传输效率低下
* 所以,hadoop专门设计了自己的序列化机制,那么,mapreduce中传输的数据类型就必须实现hadoop自己的序列化接口
*
* hadoop为jdk中的常用基本类型Long String Integer Float等数据类型封住了自己的实现了hadoop序列化接口的类型:LongWritable,Text,IntWritable,FloatWritable
*
*
*
*
* @author ThinkPad
*
*/
public class WordcountMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//切单词
String line = value.toString();
String[] words = line.split(" ");
for(String word : words){
context.write(new Text(word),new IntWritable(1));
}
}
}
WordcountReduce.java
package cn.edu360.mr.wc;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
int count = 0;
Iterator iterator = values.iterator();
while(iterator.hasNext()){
IntWritable value = iterator.next();
count += value.get();
}
context.write(key,new IntWritable(count));
}
}
JobSubmitter.java
package cn.edu360.mr.wc;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 用来提交maprejduce job的客户端程序
* 主要的功能有两个:
* 1:封装本次job运行时所需要的必要的参数
* 2:跟yarn进行交互,将mapreduce的程序成功的启动,运行
* @author LENOVO
*
*/
public class JobSubmitter {
public static void main(String[] args) throws Exception {
//在代码中设置JVM系统的参数,用于给job对象来获取访问hdfs的用户身份
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
//1:设置job运行是要访问的默认文件系统
conf.set("fs.defaultFS","hdfs://master:9000");
//2:设置job提交到哪去运行
conf.set("mapreduce.framework.name", "yarn");//如果是"local"说明则是在本地的模拟器上运行
//告诉他resourcemanager在那个地方
conf.set("yarn.resourcemanager.hostname","master");
//在运行的时候的参数配置带jvm中 去: -DHADOOP_USER_NAME=root
//3:如果要从windows系统中运行这个job提交客户端的程序,则需要加这个跨平台提交的参数
conf.set("mapreduce.app-submission.cross-platform","true");
Job job = Job.getInstance(conf);
//1:封装参数:jar包所在的位置上
job.setJar("d:/wc.jar");
// job.setJarByClass(JobSubmitter.class);
//2:封装参数:本次job的所要调用的Mapper实现类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReduce.class);
//3:封装参数本次job的mapper实现类,和reduce的实现类 产生的结果数据的key value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path output = new Path("/wordcount/output");
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"),conf,"root");
if(fs.exists(output)){
fs.delete(output, true);
}
// 4、封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
FileOutputFormat.setOutputPath(job, output); // 注意:输出路径必须不存在
// 5、封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(2);
// 6、提交job给yarn
boolean res = job.waitForCompletion(true);
System.exit(res?0:-1);
}
}
控制台结果:
[WARN ] 2018-07-17 20:41:55,118 method:org.apache.hadoop.util.Shell.(Shell.java:673)
Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
[INFO ] 2018-07-17 20:41:56,623 method:org.apache.hadoop.yarn.client.RMProxy.createRMProxy(RMProxy.java:123)
Connecting to ResourceManager at master/192.168.51.247:8032
[WARN ] 2018-07-17 20:41:57,185 method:org.apache.hadoop.mapreduce.JobResourceUploader.uploadFiles(JobResourceUploader.java:64)
Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
[INFO ] 2018-07-17 20:41:57,500 method:org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:289)
Total input files to process : 3
[INFO ] 2018-07-17 20:41:57,654 method:org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:200)
number of splits:3
[INFO ] 2018-07-17 20:41:57,845 method:org.apache.hadoop.mapreduce.JobSubmitter.printTokens(JobSubmitter.java:289)
Submitting tokens for job: job_1531823680410_0008
[INFO ] 2018-07-17 20:41:58,050 method:org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.submitApplication(YarnClientImpl.java:296)
Submitted application application_1531823680410_0008
[INFO ] 2018-07-17 20:41:58,080 method:org.apache.hadoop.mapreduce.Job.submit(Job.java:1345)
The url to track the job: http://master:8088/proxy/application_1531823680410_0008/
[INFO ] 2018-07-17 20:41:58,080 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1390)
Running job: job_1531823680410_0008
[INFO ] 2018-07-17 20:42:05,247 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1411)
Job job_1531823680410_0008 running in uber mode : false
[INFO ] 2018-07-17 20:42:05,248 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1418)
map 0% reduce 0%
[INFO ] 2018-07-17 20:42:10,325 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1418)
map 100% reduce 0%
[INFO ] 2018-07-17 20:42:16,398 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1418)
map 100% reduce 100%
[INFO ] 2018-07-17 20:42:16,426 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1429)
Job job_1531823680410_0008 completed successfully
[INFO ] 2018-07-17 20:42:16,552 method:org.apache.hadoop.mapreduce.Job.monitorAndPrintJob(Job.java:1436)
Counters: 49
File System Counters
FILE: Number of bytes read=918
FILE: Number of bytes written=682817
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=753
HDFS: Number of bytes written=103
HDFS: Number of read operations=15
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Job Counters
Launched map tasks=3
Launched reduce tasks=2
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=9265
Total time spent by all reduces in occupied slots (ms)=6533
Total time spent by all map tasks (ms)=9265
Total time spent by all reduce tasks (ms)=6533
Total vcore-milliseconds taken by all map tasks=9265
Total vcore-milliseconds taken by all reduce tasks=6533
Total megabyte-milliseconds taken by all map tasks=9487360
Total megabyte-milliseconds taken by all reduce tasks=6689792
Map-Reduce Framework
Map input records=39
Map output records=78
Map output bytes=750
Map output materialized bytes=942
Input split bytes=315
Combine input records=0
Combine output records=0
Reduce input groups=14
Reduce shuffle bytes=942
Reduce input records=78
Reduce output records=14
Spilled Records=156
Shuffled Maps =6
Failed Shuffles=0
Merged Map outputs=6
GC time elapsed (ms)=434
CPU time spent (ms)=3950
Physical memory (bytes) snapshot=1207812096
Virtual memory (bytes) snapshot=10917920768
Total committed heap usage (bytes)=896008192
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=438
File Output Format Counters
Bytes Written=103