Hi 欢迎来到Paper 研习社每日精选栏目,Paper 研习社(paper.yanxishe.com)每天都为你精选关于人工智能的前沿学术论文供你参考,以下是今日的精选内容——
目录
Deep Interest Evolution Network for Click-‐Through Rate Prediction
Scene Text Recognition from Two-‐Dimensional Perspective
ColosseumRL: A Framework for Multiagent Reinforcement Learning in N-Player Games
edBB: Biometrics and Behavior for Assessing Remote Education
3D Volumetric Modeling with Introspective Neural Networks
Trainable Undersampling for Class-‐Imbalance Learning
Deep Audio Prior
CNN-generated images are surprisingly easy to spot... for now
UWGAN: Underwater GAN for Real-world Underwater Color Restoration and Dehazing
Learning Singing From Speech
深度兴趣演化网络用于点击率预测
Deep Interest Evolution Network for Click-‐Through Rate Prediction
作者:Guorui Zhou / Na Mou / Ying Fan / Qi Pi / Weijie Bian / Chang Zhou / Xiaoqiang Zhu / Kun Gai
发表时间:2018/12/12
论文链接:https://paper.yanxishe.com/review/7813?from=jianshu1225
推荐理由:一.解决问题:旨在估计用户点击概率的点击率(CTR)预测已成为广告系统的核心任务之一。对于CTR预测模型,有必要捕获用户行为数据背后的潜在用户兴趣。此外,考虑到外部环境和内部认知的变化,用户兴趣会随着时间动态变化。有多种用于兴趣建模的CTR预测方法,其中大多数将行为的表示直接视为兴趣,而缺乏针对具体行为背后的潜在兴趣的专门建模。而且,很少有工作考虑利益的变化趋势。
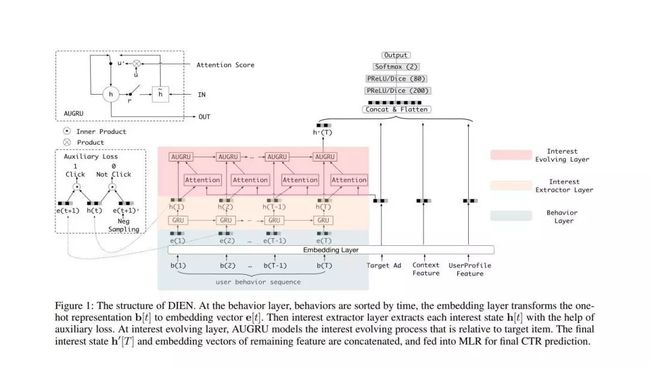
二. 创新点在本文中,我们提出了一种新颖的模型,称为深度兴趣演化网络(DIEN),用于CTR预测。具体来说,我们设计兴趣提取器层以从历史行为序列中捕获时间兴趣。在这一层,我们引入了辅助损失,以监督每一步的利息提取。由于用户兴趣的多样性,尤其是在电子商务系统中,我们提出了兴趣演变层来捕获相对于目标商品的兴趣演变过程。在兴趣演化层,注意力机制被新颖地嵌入到顺序结构中,并且在兴趣演化过程中增强了相对兴趣的影响。在针对公共和工业数据集的实验中,DIEN的性能明显优于最新的解决方案。值得注意的是,DIEN已部署到淘宝的展示广告系统中,其点击率提高了20.7%。

二维视角的场景文本识别
Scene Text Recognition from Two-‐Dimensional Perspective
作者:Minghui Liao / Jian Zhang
发表时间:2018/12/20
论文链接:https://paper.yanxishe.com/review/7814?from=jianshu1225
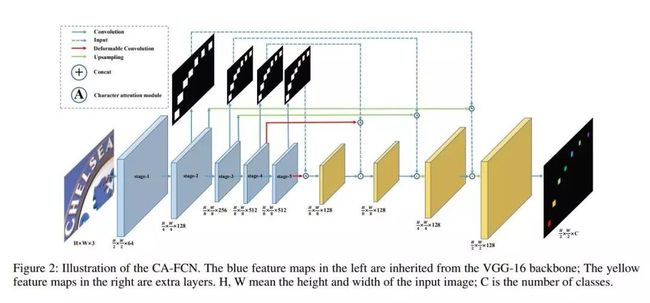
推荐理由:受语音识别的启发,最近的最新算法大多将场景文本识别视为序列预测问题。尽管获得了优异的性能,但是这些方法通常忽略了一个重要事实,即图像中的文本实际上分布在二维空间中。它与语音本质上是完全不同的,语音本质上是一维信号。原则上,直接将文本特征压缩为一维形式可能会丢失有用的信息并引入额外的噪音。在本文中,我们从二维角度处理场景文本识别。设计了一个简单但有效的模型,称为字符注意完全卷积网络(CA-FCN),用于识别任意形状的文本。场景文本识别是通过语义分割网络实现的,其中采用了字符的关注机制。结合词形成模块,CA-FCN可以同时识别脚本并预测每个字符的位置。实验表明,该算法在常规和非常规文本数据集上均优于先前的方法。此外,事实证明,在文本检测阶段中精确定位的不精确性更为强大,这在实践中非常普遍。

ColosseumRL:N个玩家游戏中多智能体强化学习的框架
ColosseumRL: A Framework for Multiagent Reinforcement Learning in N-Player Games
作者:Shmakov Alexander /Lanier John /McAleer Stephen /Achar Rohan /Lopes Cristina /Baldi Pierre
发表时间:2019/12/10
论文链接:https://paper.yanxishe.com/review/7827?from=jianshu1225
推荐理由:在多智能体强化学习中,最近的许多成功都发生在两人零和游戏中。在这些游戏中,虚拟自我玩法和最小极大树搜索等算法可以收敛到近似Nash平衡。虽然在两人零和游戏中玩纳什均衡策略是最佳的,但在n人一般和游戏中,它变成了信息量少得多的解决方案概念。尽管缺少令人满意的解决方案概念,但在现实世界中,n玩家游戏构成了绝大多数的多代理情况。在本文中,我们提出了一个用于研究n玩家游戏中强化学习的新框架。我们希望通过分析代理在这些环境中学到的行为,社区可以更好地理解这一重要的研究领域,并朝着有意义的解决方案概念和研究方向发展。有关此框架的实现和其他信息,请参见https://colosseumrl.igb.uci.edu/。




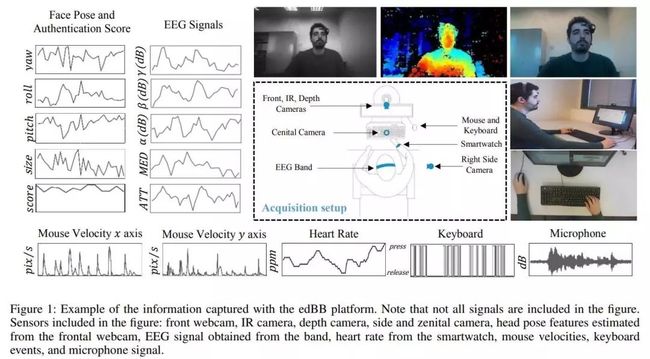
edBB:评估远程教育的生物识别和行为
edBB: Biometrics and Behavior for Assessing Remote Education
作者:Hernandez-Ortega Javier /Daza Roberto /Morales Aythami /Fierrez Julian /Ortega-Garcia Javier
发表时间:2019/12/10
论文链接:https://paper.yanxishe.com/review/7828?from=jianshu1225
推荐理由:我们提供了一个用于远程教育中学生监控的平台,该平台由捕获生物特征和行为数据的传感器和软件组成。我们定义了一组任务来获取行为数据,这些数据对于应对远程评估过程中自动学生监控中的现有挑战很有用。此外,我们发布了一个初始数据库,其中包含来自20个不同用户的数据,这些用户使用一组基本传感器来完成这些任务:摄像头,麦克风,鼠标和键盘;以及更先进的传感器:NIR相机,智能手表,其他RGB相机和EEG频段。来自计算机的信息(例如系统日志,MAC,IP或Web浏览历史记录)也将被存储。在每个获取会话期间,每个用户完成三种不同类型的任务,生成不同性质的数据:鼠标和击键动态,面部数据和音频数据等。设计任务时要牢记两个主要目标:i)分析此类生物统计和行为数据的能力以在远程评估期间检测异常,并且ii)研究这些数据的能力,例如脑电图,心电图或近红外视频估计有关用户的其他信息,例如他们的注意力水平,压力的存在或他们的脉搏率。

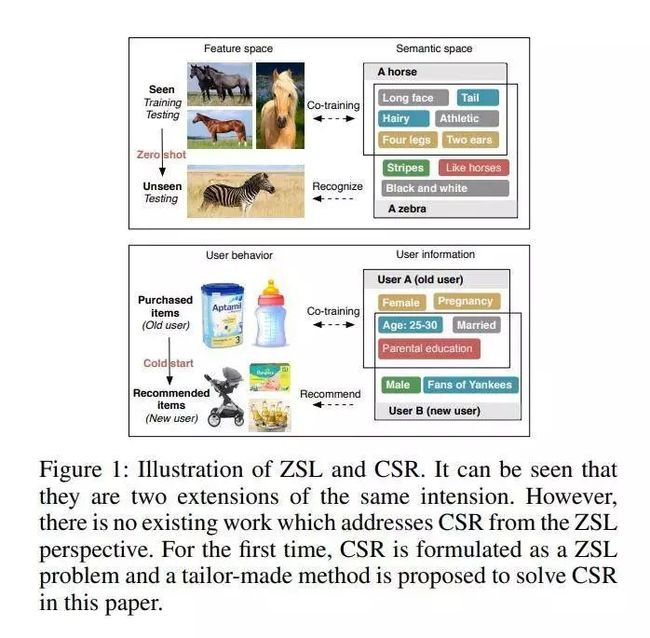
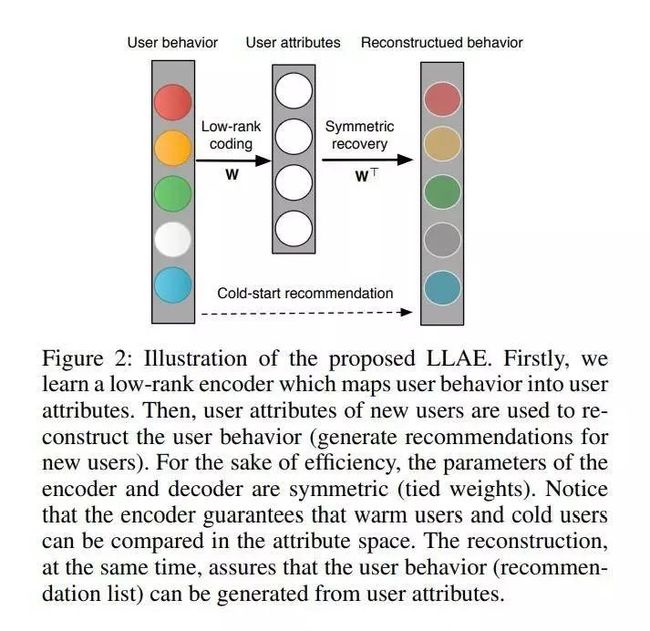
从零学习到冷启动推荐
3D Volumetric Modeling with Introspective Neural Networks
作者:Jingjing Li / Mengmeng Jing / Ke Lu / Lei Zhu / Yang Yang / Zi Huang
发表时间:2018/12/20
论文链接:https://paper.yanxishe.com/review/7829?from=jianshu1225
推荐理由:零样本学习(ZSL)和冷启动推荐(CSR)分别是计算机视觉和推荐系统中的两个难题。通常,在不同社区中对它们进行独立调查。但是,本文揭示了ZSL和CSR是相同意图的两个扩展。例如,它们都试图预测看不见的类,并涉及两个空间,一个空间用于直接特征表示,另一个空间用于补充描述。但是,没有从ZSL角度解决CSR的现有方法。
这项工作首次将CSR公式化为ZSL问题,并提出了量身定制的ZSL方法来处理CSR。具体来说,我们提出了一种低阶线性自动编码器(LLAE),它在本文中挑战了三个关键点,即域移位,伪相关和计算效率。LLAE由两部分组成,低级编码器将用户行为映射为用户属性,对称解码器根据用户属性重建用户行为。在ZSL和CSR任务上进行的大量实验证明了该方法是双赢的,即,不仅ZSL模型可以处理CSR,而且与几种传统的最新方法相比,其性能也得到了显着改善。CSR的考虑也可以使ZSL受益。
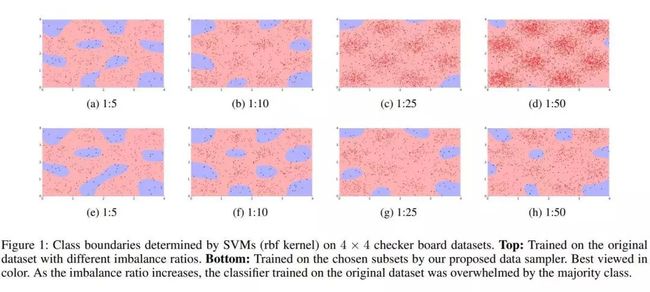
可训练的欠采样,用于类别不平衡学习
Trainable Undersampling for Class-‐Imbalance Learning
作者:Minlong Peng1 / Qi Zhang1 / Xiaoyu Xing1 / Tao Gui1 / Xuanjing Huang1 Yu-Gang Jiang1
发表时间:2018/12/20
论文链接:https://paper.yanxishe.com/review/7830?from=jianshu1225
推荐理由:
一 解决问题
欠采样已广泛应用于班级不平衡学习领域。大多数现有欠采样方法的主要缺陷是它们的数据采样策略是基于启发式的,并且与所使用的分类和评估指标无关。因此,他们可能会在数据采样过程中为分类器丢弃翔实的实例
二 创新点
在这项工作中,我们提出了一种基于欠采样的元学习方法来解决此问题。该方法的关键思想是对数据采样器进行参数设置,并对其进行训练,以优化评估指标上的分类性能。我们通过强化学习解决了用于训练数据采样器的不可微优化问题。通过将评估指标优化合并到数据采样过程中,所提出的方法可以了解对于给定的分类和评估指标应丢弃哪个实例。另外,作为数据级别的操作,此方法可以轻松地应用于任意评估指标和分类,包括非参数评估指标和分类(例如C4.5和KNN)。

深度音频优先
Deep Audio Prior
作者:Tian Yapeng /Xu Chenliang /Li Dingzeyu
发表时间:2019/12/21
论文链接:https://paper.yanxishe.com/review/7831?from=jianshu1225
推荐理由:众所周知,深度卷积神经网络擅长从大量数据中提取紧凑而强大的数据。我们有兴趣在没有训练数据集的情况下应用深度网络。
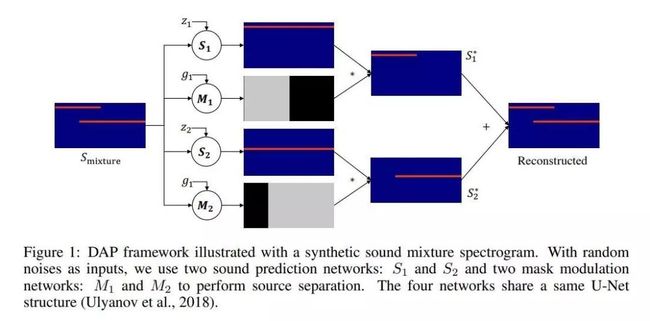
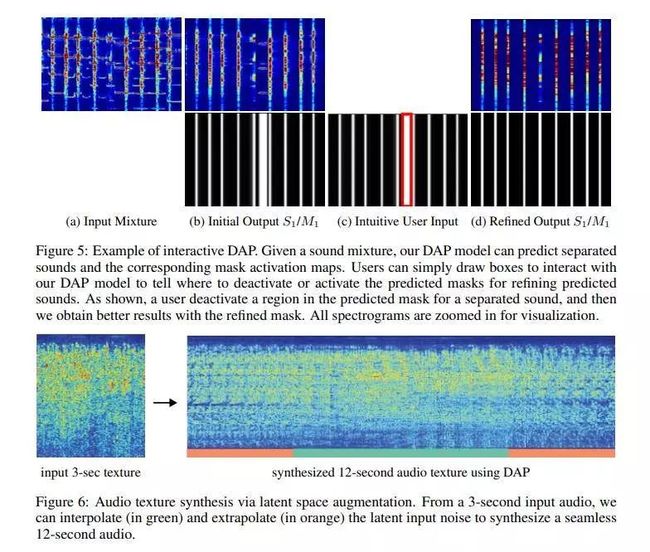
在本文中,作者介绍了深音频先验(DAP),它利用了网络的结构和单个音频文件中的时间信息。具体而言,作者证明了在解决具有挑战性的音频问题(例如通用盲源分离,交互式音频编辑,音频纹理合成和音频共分离)之前,可以将随机初始化的神经网络与经过精心设计的音频一起使用。为了了解先验音频的鲁棒性,作者构建了一个基准数据集\ emph {Universal-150},用于使用各种声源进行通用声源分离。在定性和定量评估方面,其显示出比以前的作品更好的音频结果。作者还将进行彻底的消融研究,以验证我们的设计选择。

CNN生成的图像现在非常容易发现...
CNN-generated images are surprisingly easy to spot... for now
作者:Wang Sheng-Yu /Wang Oliver /Zhang Richard /Owens Andrew /Efros Alexei A.
发表时间:2019/12/23
论文链接:https://paper.yanxishe.com/review/7834?from=jianshu1225
推荐理由:在这项工作中,作者询问是否有可能创建一个“通用”检测器,以区分CNN生成的真实图像,而与所使用的体系结构或数据集无关。
为了测试这一点,作者收集了一个由11种不同的基于CNN的图像生成器模型生成的伪图像组成的数据集,这些模型被选择来跨越当今常用架构的空间(ProGAN,StyleGAN,BigGAN,CycleGAN,StarGAN,GauGAN,DeepFakes,级联精炼)网络,隐式最大似然估计,二阶注意力超分辨率,黑暗中看到)。
作者证明,经过精心的预处理和后处理以及数据增强,仅在一个特定的CNN生成器(ProGAN)上进行训练的标准图像分类器就可以令人惊奇地将其很好地推广到看不见的架构,数据集和训练方法(包括刚刚发布的StyleGAN2)。我们的发现表明,当今的CNN生成的图像存在一些常见的系统缺陷,从而阻止了它们实现逼真的图像合成,这是一种令人着迷的可能性。


UWGAN:水下GAN,用于真实世界的水下颜色恢复和去雾
UWGAN: Underwater GAN for Real-world Underwater Color Restoration and Dehazing
作者:Wang Nan /Zhou Yabin /Han Fenglei /Zhu Haitao /Zheng Yaojing
发表时间:2019/12/21
论文链接:https://paper.yanxishe.com/review/7835?from=jianshu1225
推荐理由:在现实世界的水下环境中,海底资源的勘探,水下考古学和水下捕鱼都依赖于各种传感器,视觉传感器由于其信息量高,非侵入性和被动性而成为最重要的传感器。但是,与波长有关的光衰减和反向散射会导致颜色失真和雾度效应,从而降低图像的可见性。
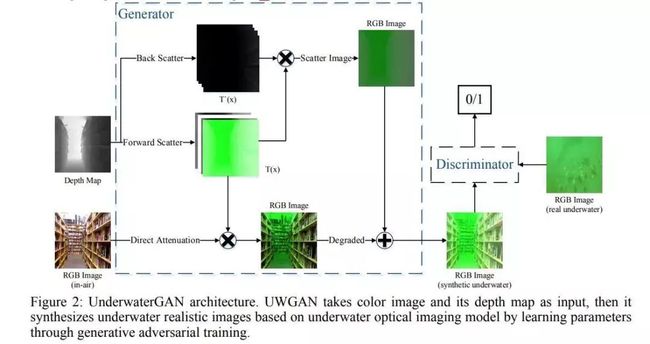
为了解决这个问题,首先,作者提出了一种无监督的生成对抗网络(GAN),用于基于改进的水下成像模型从空中图像和深度图对生成逼真的水下图像(颜色失真和雾度效果)。其次,采用合成水下数据集进行有效训练的U-Net,用于色彩还原和除雾。作者的模型使用端到端自动编码器网络直接重建水下清晰图像,同时保持场景内容结构的相似性。
通过作者的方法获得的结果定性和定量地与现有方法进行了比较。通过该模型获得的实验结果证明了在开放的现实世界水下数据集上的良好性能,并且在一个NVIDIA 1060 GPU上运行时,处理速度可以达到125FPS。源代码和示例数据集可通过此https URL公开获得。


通过语音学习唱歌
Learning Singing From Speech
作者:Zhang Liqiang /Yu Chengzhu /Lu Heng /Weng Chao /Wu Yusong /Xie Xiang /Li Zijin /Yu Dong
发表时间:2019/12/20
论文链接:https://paper.yanxishe.com/review/7836?from=jianshu1225
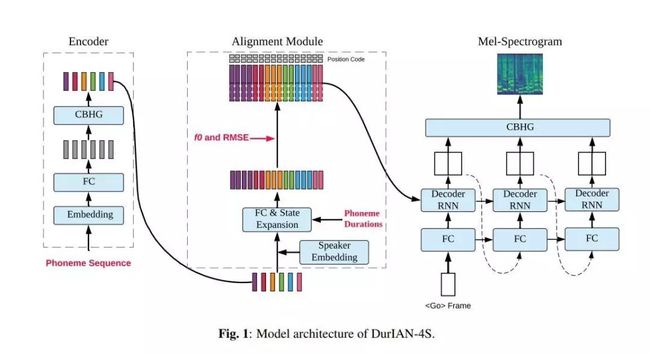
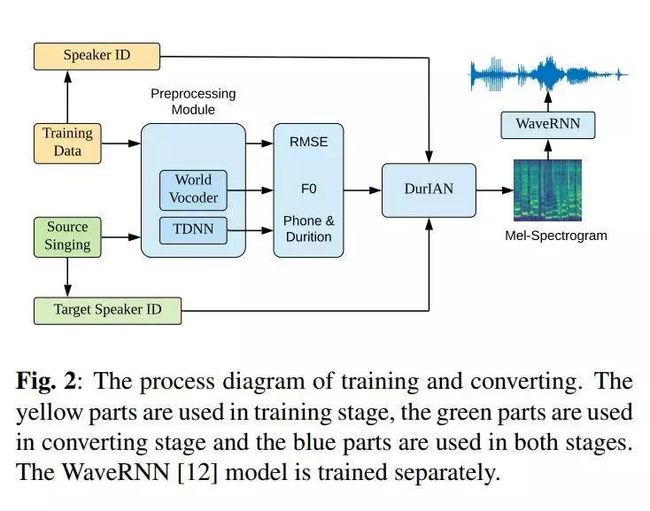
推荐理由:作者提出了一种算法,该算法能够在仅给出正常语音样本的情况下合成高质量目标说话者的歌声。提出的算法首先将语音和歌唱合成整合到一个统一的框架中,并学习语音和歌唱合成任务之间可共享的通用说话人嵌入。具体而言,在统一的训练框架中,将通过语音合成目标从正常语音中学到的说话者嵌入与通过语音合成目标从演唱样本中学习的说话者共享。这使得有经验的演讲者可以嵌入可口述的演讲和演唱形式。
作者评估了所提出算法在歌唱语音转换任务上的效果,该算法的原始歌唱内容被纯粹从正常说话样本中获悉的另一位演讲者的声音音色所覆盖。作者的实验表明,所提出的算法会产生高质量的歌声,听起来仅与目标说话者的语音(仅给出正常语音样本)高度相似。作者相信,提出的算法将为更广泛的用户和应用打开唱歌合成和转换的新机会。