上一篇的 「Java 集合框架」里,还剩下一个大问题没有说的,那就是 PriorityQueue,优先队列,也就是堆,Heap。
什么是堆?
堆其实就是一种特殊的队列——优先队列。
普通的队列游戏规则很简单:就是先进先出;但这种优先队列搞特殊,不是按照进队列的时间顺序,而是按照每个元素的优先级来比拼,优先级高的在堆顶。
这也很容易理解吧,比如各种软件都有会员制度,某软件用了会员就能加速下载的,不同等级的会员速度还不一样,那就是优先级不同呀。
还有其实每个人回复微信消息也是默默的把消息放进堆里排个序:先回男朋友女朋友的,然后再回其他人的。
这里要区别于操作系统里的那个“堆”,这两个虽然都叫堆,但是没有半毛钱关系,都是借用了 Heap 这个英文单词而已。

我们再来回顾一下「堆」在整个 Java 集合框架中的位置:
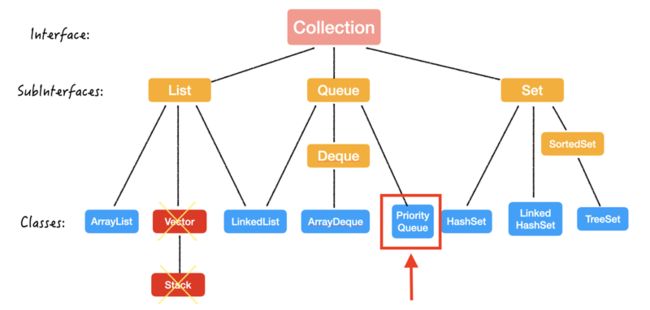
也就是说,
- PriorityQueue 是一个类 (class);
- PriorityQueue 继承自 Queue 这个接口 (Interface);
那 heap 在哪呢?
heap 其实是一个抽象的数据结构,或者说是逻辑上的数据结构,并不是一个物理上真实存在的数据结构。
heap 其实有很多种实现方式,比如 binomial heap, Fibonacci heap 等等。但是面试最常考的,也是最经典的,就是 binary heap 二叉堆,也就是用一棵完全二叉树来实现的。
那完全二叉树是怎么实现的?
其实是用数组来实现的!
所以 binary heap/PriorityQueue 实际上是用数组来实现的。
这个数组的排列方式有点特别,因为它总会维护你定义的(或者默认的)优先级最高的元素在数组的首位,所以不是随便一个数组都叫「堆」,实际上,它在你心里,应该是一棵「完全二叉树」。
这棵完全二叉树,只存在你心里和各大书本上;实际在在内存里,哪有什么树?就是数组罢了。
那为什么完全二叉树可以用数组来实现?是不是所有的树都能用数组来实现?
这个就涉及完全二叉树的性质了,我们下一篇会细讲,简单来说,因为完全二叉树的定义要求了它在层序遍历的时候没有气泡,也就是连续存储的,所以可以用数组来存放;第二个问题当然是否。
堆的特点
- 堆是一棵完全二叉树;
- 堆序性 (heap order): 任意节点都优于它的所有孩子。
a. 如果是任意节点都大于它的所有孩子,这样的堆叫大顶堆,Max Heap;
b. 如果是任意节点都小于它的所有孩子,这样的堆叫小顶堆,Min Heap;
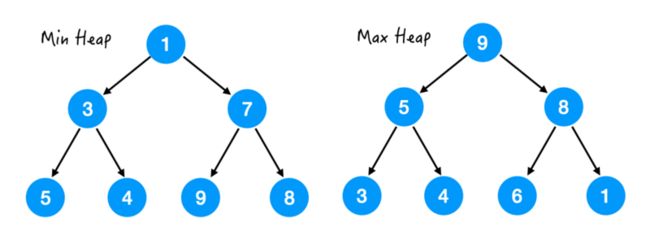
左图是小顶堆,可以看出对于每个节点来说,都是小于它的所有孩子的,注意是所有孩子,包括孙子,曾孙...
- 既然堆是用数组来实现的,那么我们可以找到每个节点和它的父母/孩子之间的关系,从而可以直接访问到它们。
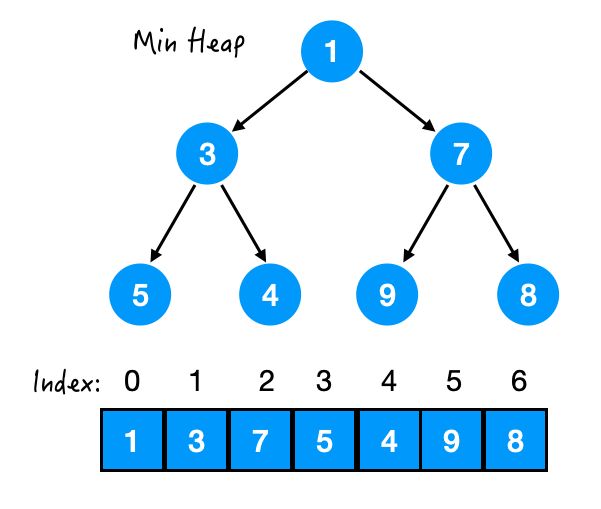
比如对于节点 3 来说,
- 它的 Index = 1,
- 它的 parent index = 0,
- 左孩子 left child index = 3,
- 右孩子 right child index = 4.
可以归纳出如下规律:
- 设当前节点的 index = x,
- 那么 parent index = (x-1)/2,
- 左孩子 left child index = 2*x + 1,
- 右孩子 right child index = 2*x + 2.
有些书上可能写法稍有不同,是因为它们的数组是从 1 开始的,而我这里数组的下标是从 0 开始的,都是可以的。
这样就可以从任意一个点,一步找到它的孙子、曾孙子,真的太方便了,在后文讲具体操作时大家可以更深刻的体会到。
基本操作
任何一个数据结构,无非就是增删改查四大类:
| 功能 | 方法 | 时间复杂度 |
|---|---|---|
| 增 | offer(E e) | O(logn) |
| 删 | poll() | O(logn) |
| 改 | 无直接的 API | 删 + 增 |
| 查 | peek() | O(1) |
这里 peek() 的时间复杂度很好理解,因为堆的用途就是能够快速的拿到一组数据里的最大/最小值,所以这一步的时间复杂度一定是 O(1) 的,这就是堆的意义所在。
那么我们具体来看 offer(E e) 和 poll() 的过程。
offer(E e)
比如我们新加一个 0 到刚才这个最小堆里面:
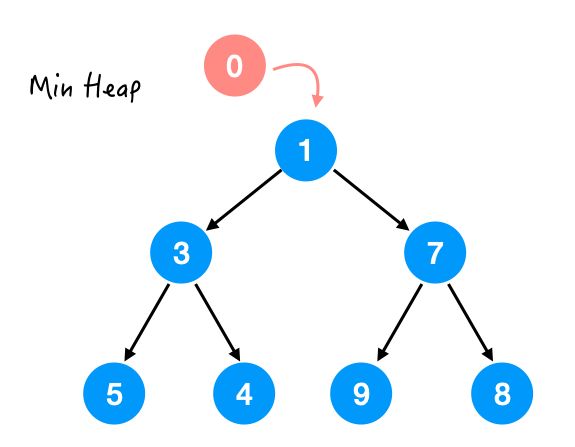
那很明显,0 是要放在最上面的,可是,直接放上去就不是一棵完全二叉树了啊。。
所以说,
- 我们先保证加了元素之后这棵树还是一棵完全二叉树,
- 然后再通过 swap 的方式进行微调,来满足堆序性。
这样就保证满足了堆的两个特点,也就是保证了加入新元素之后它还是个堆。
那具体怎么做呢:
Step 1.
先把 0 放在最后接上,别一上来就想着上位;
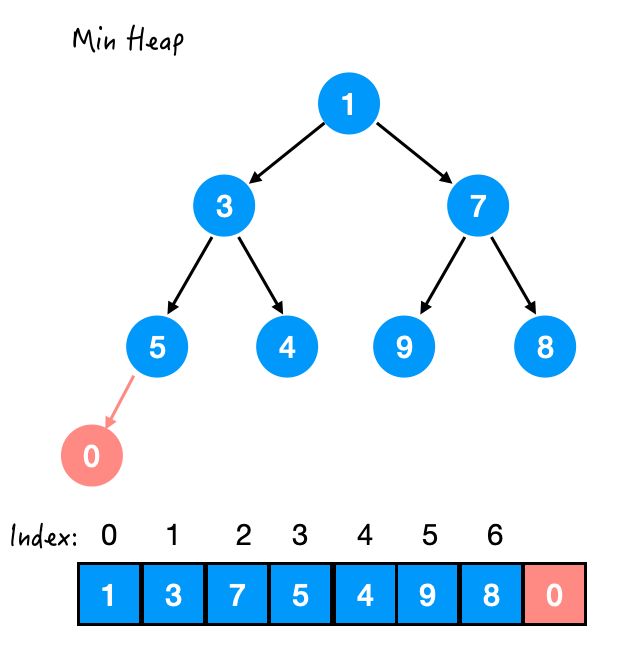
OK!总算先上岸了,然后我们再一步步往上走。
这里「能否往上走」的标准在于:
是否满足堆序性。
也就是说,现在 5 和 0 之间不满足堆序性,那么交换位置,换到直到满足堆序性为止。
这里对于最小堆来说的堆序性,就是小的数要在上面。
Step 2. 与 5 交换
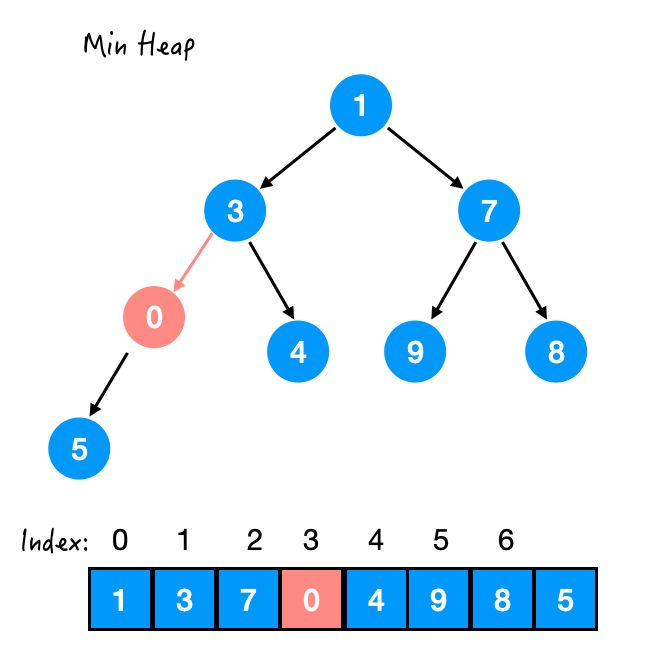
此时 0 和 3 不满足堆序性了,那么再交换。
Step 3. 与 3 交换
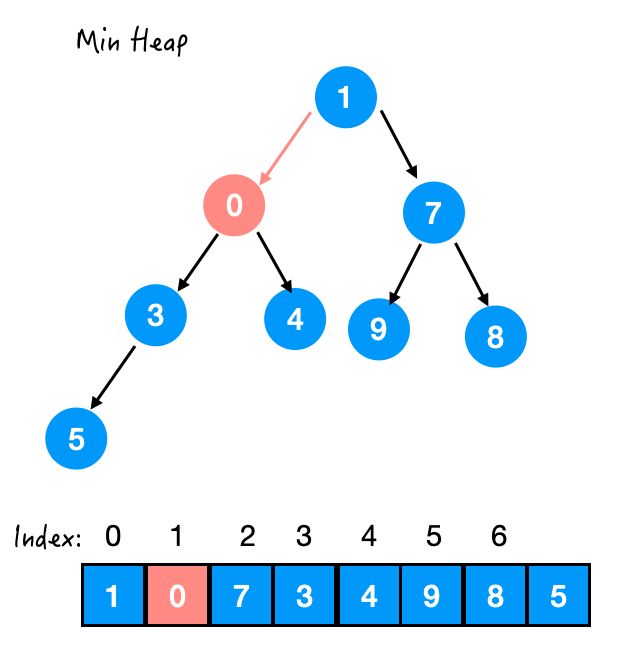
还不行,0 还比 1 小,所以继续换。
Step 4. 与 1 交换
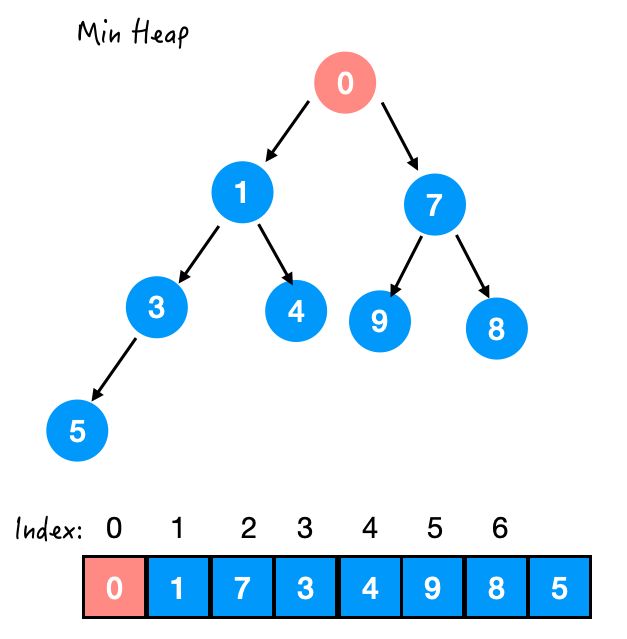
OK!这样就换好了,一个新的堆诞生了~
总结一下这个方法:
先把新元素加入数组的末尾,再通过不断比较与 parent 的值的大小,决定是否交换,直到满足堆序性为止。
这个过程就是 siftUp(),源码如下:

时间复杂度
这里不难发现,其实我们只交换了一条支路上的元素,
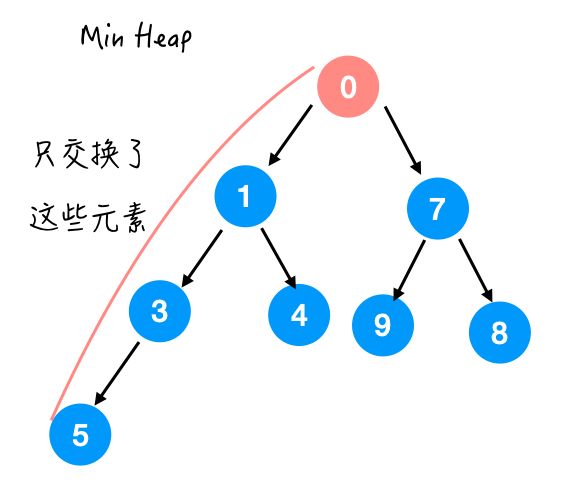
也就是最多交换 O(height) 次。
那么对于完全二叉树来说,除了最后一层都是满的,O(height) = O(logn)。
所以 offer(E e) 的时间复杂度就是 O(logn) 啦。
poll()
poll() 就是把最顶端的元素拿走。
对了,没有办法拿走中间的元素,毕竟要 VIP 先出去,小弟才能出去。
那么最顶端元素拿走后,这个位置就空了:
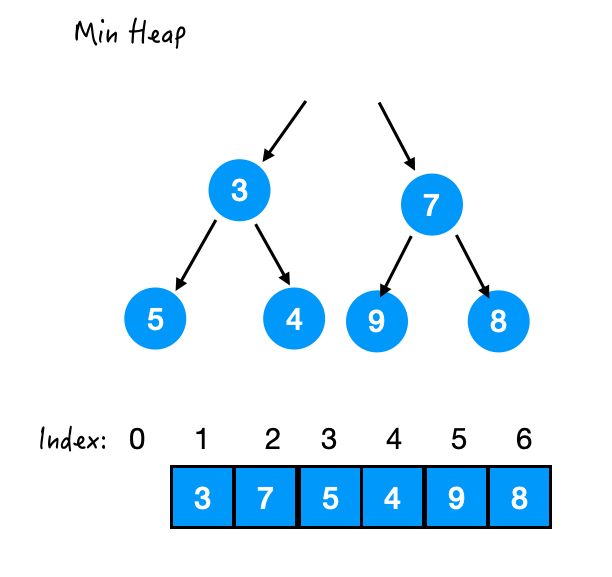
我们还是先来满足堆序性,因为比较容易满足嘛,直接从最后面拿一个来补上就好了,先放个傀儡上来。
Step1. 末尾元素上位
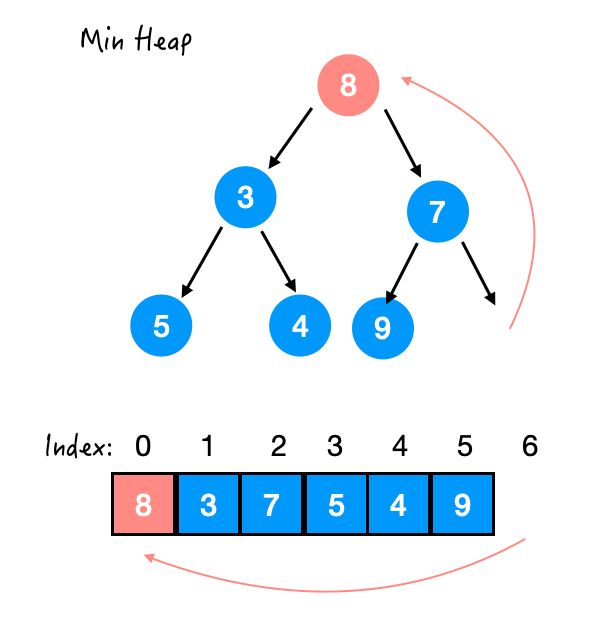
这样一来,堆序性又不满足了,开始交换元素。
那 8 比 7 和 3 都大,应该和谁交换呢?
假设与 7 交换,那么 7 还是比 3 大,还得 7 和 3 换,麻烦。
所以是与左右孩子中较小的那个交换。
Step 2. 与 3 交换
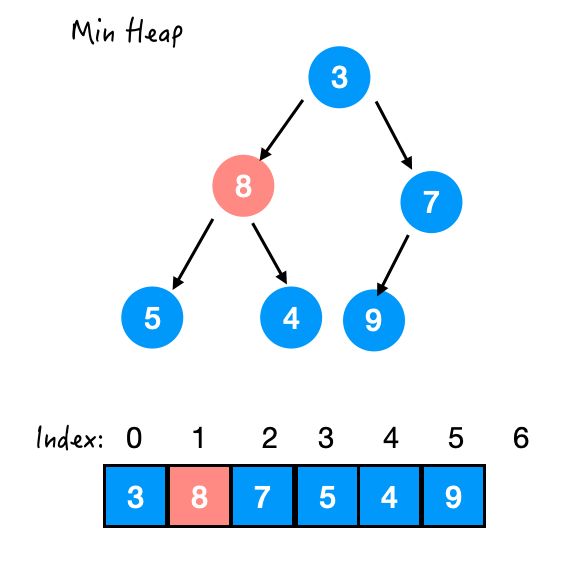
下去之后,还比 5 和 4 大,那再和 4 换一下。
Step 3. 与 4 交换
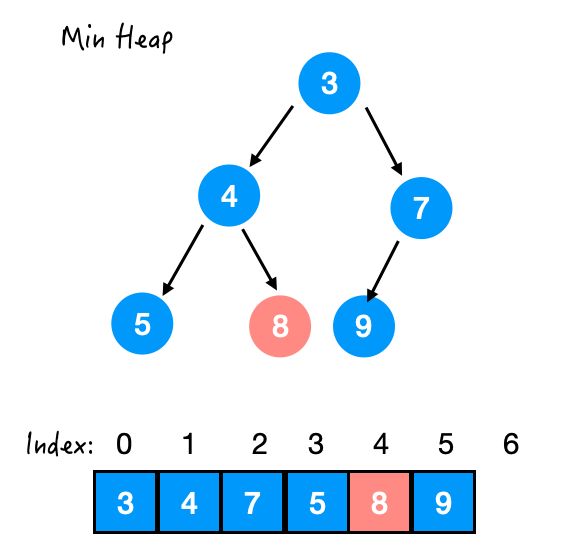
OK!这样这棵树总算是稳定了。
总结一下这个方法:
先把数组的末位元素加到顶端,再通过不断比较与左右孩子的值的大小,决定是否交换,直到满足堆序性为止。
这个过程就是 siftDown(),源码如下:

时间复杂度
同样道理,也只交换了一条支路上的元素,也就是最多交换 O(height) 次。
所以 offer(E e) 的时间复杂度就是 O(logn) 啦。
heapify()
还有一个大名鼎鼎的非常重要的操作,就是 heapify() 了,它是一个很神奇的操作,
可以用 O(n) 的时间把一个乱序的数组变成一个 heap。
但是呢,heapify() 并不是一个 public API,看:

所以我们没有办法直接使用。
唯一使用 heapify() 的方式呢,就是使用PriorityQueue(Collection c)
这个 constructor 的时候,人家会自动调用 heapify() 这个操作。
那具体是怎么做的呢?
哈哈源码已经暴露了:
从最后一个非叶子节点开始,从后往前做 siftDown().
因为叶子节点没必要操作嘛,已经到了最下面了,还能和谁 swap?
举个例子:
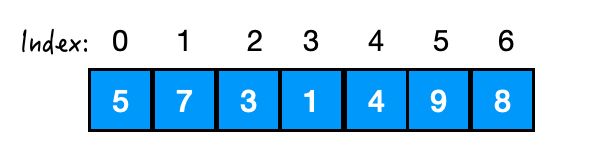
我们想把这个数组进行 heapify() 操作,想把它变成一个最小堆,拿到它的最小值。
那就要从 3 开始,对 3,7,5进行 siftDown().
Step 1.
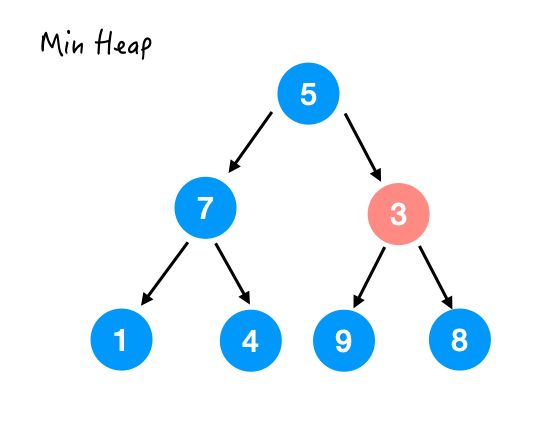
尴尬 ,3 并不用交换,因为以它为顶点的这棵小树已经满足了堆序性。
Step 2.
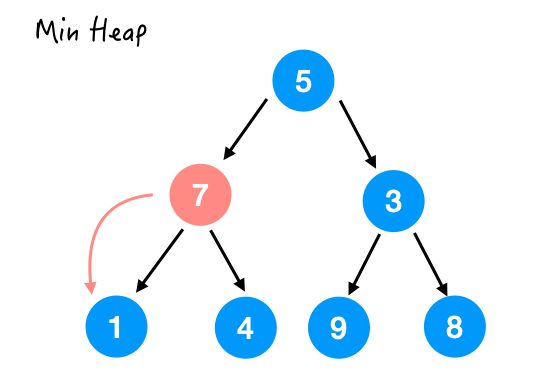
7 比它的两个孩子都要大,所以和较小的那个交换一下。
交换完成后;
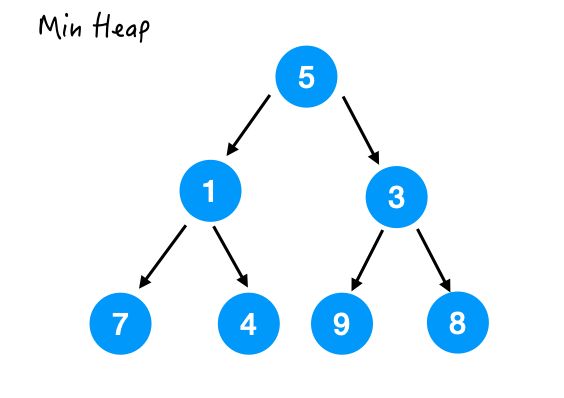
Step 3.
最后一个要处理的就是 5 了,那这里 5 比它的两个孩子都要大,所以也和较小的那个交换一下。
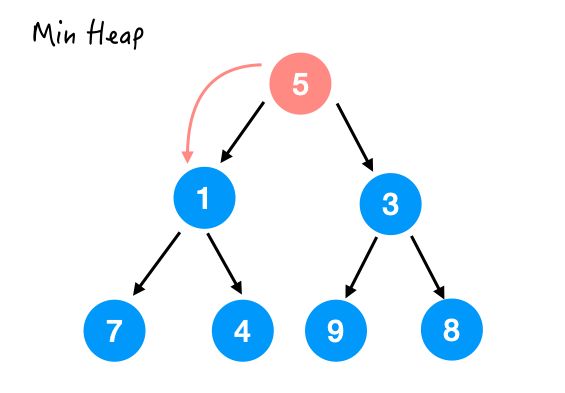
换完之后结果如下,注意并没有满足堆序性,因为 4 还比 5 小呢。
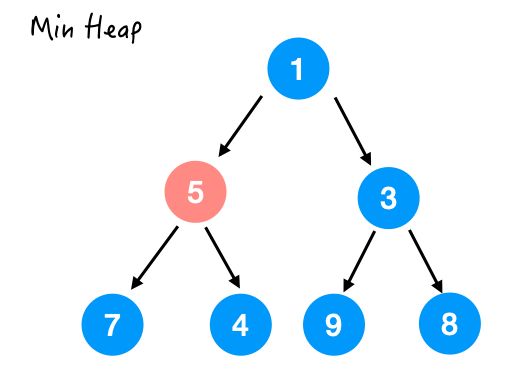
所以接着和 4 换,结果如下:
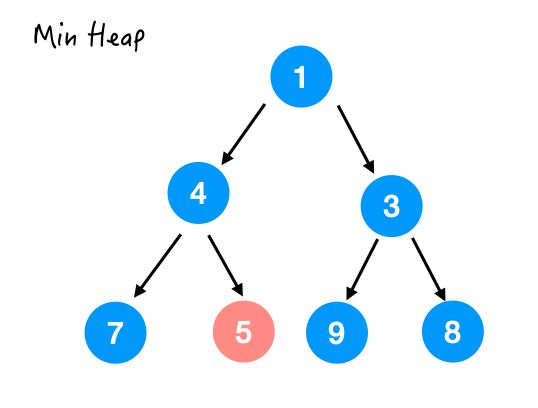
这样整个 heapify() 的过程就完成了。
好了难点来了,为什么时间复杂度是 O(n) 的呢?
怎么计算这个时间复杂度呢?
其实我们在这个过程里做的操作无非就是交换交换。
那到底交换了多少次呢?
没错,交换了多少次,时间复杂度就是多少。
那我们可以看出来,其实同一层的节点最多交换的次数都是相同的。
那么这个总的交换次数 = 每层的节点数 * 每个节点最多交换的次数
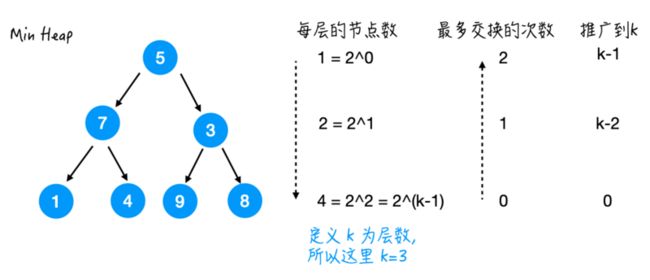
这里设 k 为层数,那么这个例子里 k=3.
每层的节点数是从上到下以指数增长:
$$\ce{1, 2, 4, ..., 2^{k-1}}$$
每个节点交换的次数,
从下往上就是:
$$ 0, 1, ..., k-2, k-1 $$
那么总的交换次数 S(k) 就是两者相乘再相加:
$$S(k) = \left(2^{0} *(k-1) + 2^{1} *(k-2) + ... + 2^{k-2} *1 \right)$$
这是一个等比等差数列,标准的求和方式就是错位相减法。
那么
$$2S(k) = \left(2^{1} *(k-1) + 2^{2} *(k-2) + ... + 2^{k-1} *1 \right)$$
两者相减得:
$$S(k) = \left(-2^{0} *(k-1) + 2^{1} + 2^{2} + ... + 2^{k-2} + 2^{k-1} \right)$$
化简一下:
(不好意思我实在受不了这个编辑器了。。。
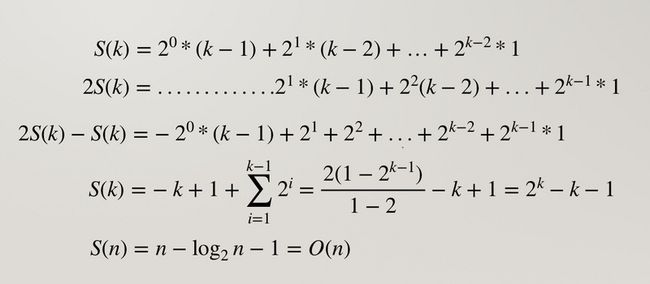
所以 heapify() 时间复杂度是 O(n).

以上就是堆的三大重要操作,最后一个 heapify() 虽然不能直接操作,但是堆排序中用到了这种思路,之前的「选择排序」那篇文章里也提到了一些,感兴趣的同学可以后台回复「选择排序」获得文章~至于堆排序的具体实现和应用,以及为什么实际生产中并不爱用它,我们之后再讲。
最后再说一点题外话,最近发现了几篇搬运我的文章到其他平台的现象。每篇文章都是我精心打造的,都是自己的心肝宝贝,看到别人直接搬运过去也没有标明作者和来源出处实在是太难受了。。为了最好的阅读体验,文中的图片我都没有加水印,但这也方便了他人搬运。今天考虑再三,还是不想违背自己的本意,毕竟我的读者更为重要。
所以如果之后有小伙伴看到了,恳请大家后台或者微信告诉我一下呀,非常感谢!
我在各大平台同名,请认准「码农田小齐」~
如果你喜欢我的文章或者有收获的话,麻烦给我点个「赞」或者「在看」给我个小鼓励呀,会让我开心好久~
想跟我一起玩转算法和面试的小伙伴,记得关注我,我是小齐,我们下期见。