基于迁移学习的网络流量分类
写在前面:
本文翻译供个人研究学习之用,不保证严谨与准确
github链接:https://github.com/WithHades/network_traffic_classification_paper
本文原文:G. Sun, L. Liang, T. Chen, F. Xiao and F. Lang, “Network traffic classification based on transfer learning”, Comput. Elect. Eng., vol. 69, pp. 920-927, Jul. 2018
基于迁移学习的网络流量分类
- 基于迁移学习的网络流量分类
- 1. 介绍
- 2. 相关工作
- 3. 问题表述
- 4. 方法
- 5. 实验和分析
- 5.1 数据集
- 5.2 实验设置
- 5.3 实验结果
- 6. 结论和未来工作
基于迁移学习的网络流量分类
摘要
用于流量分类的机器学习模型假设训练数据和测试数据具有独立的相同分布。然而,在实际的流量分类中,由于流量特征的变化,这一假设可能并不成立。由现有数据训练的模型在对新的网络流进行分类时将是无效的。本文提出了一个不作上述假设的迁移学习模型。在迁移学习模型中,采用最大熵模型作为基本分类器。为了检验该方法的有效性,在训练和测试数据不完全相同的情况下,使用剑桥大学收集的流量数据集。实验结果表明,基于迁移学习模型的分类性能良好。
关键词: 卷积神经网络,深度学习,网络流量分类,循环神经网络
1. 介绍
随着网络面临的威胁越来越多,网络管理者必须对网络中运行的应用程序有更深入的了解。流量分类是网络管理的一个重要方面,它能够对所有的网络流量进行分类。
近年来,许多新的网络协议试图通过动态端口、封装和加密等伪装方法逃避监控。这使得基于端口和基于负载的方法变得不可靠。研究人员的动机是使用应用程序类型作为类别,使用网络通信生成的流量统计属性作为特征。机器学习模型广泛应用于基于机器学习的流量分类方法中,包括监督学习模型、无监督学习模型和半监督学习模型[2]。然而,流量分类仍然面临两大挑战。首先是新应用的快速增长。二是随着网络拓扑结构和时间的变化,需要不同的训练模型。在非监督学习模型中,很难建立一个既有聚类结果又不考虑实际流量类别指导的实用流量分类器[3]。对于半监督学习模型,它在训练过程中利用了一小组标记的流量流和一大组未标记的流量流。对于有监督学习模型,采用了更大的标记流量集。当训练数据集和测试数据集相同时,两者都取得了令人满意的结果。然而,时间、地点和流量类型的变化使得传统的机器学习模型的效率比预期的要低,因为过去收集的训练数据和新生成的测试数据是不一样的[4]。虽然由过时数据训练的模型不能很好地适应新的网络流量,但过时的数据不应该被放弃,因为很难获得具有描述整个网络流量能力的标准标记流量。因此,具有宝贵知识的过时数据应重新用于新的流量分类任务。迁移学习不需要具有独立的同一分布(iid)。即使对于不同的任务,迁移学习仍然有克服上述障碍的优势[5]。假设一个学习任务和相应的数据在源域中,而一个学习任务和相应的数据在目标域中,迁移学习的目标是通过从源域学习知识来提高目标预测函数的速度。与传统的机器学习模型相比,迁移学习不需要对两个领域之间的数据进行iid假设[6]。
考虑到数据分布会随着时间、地点和流量类型的变化而变化的情况,针对流量分类任务引入了TrAdaBoost模型[6],这是一种基于实例的有区别的归纳迁移学习模型。同时利用Maxent作为基本分类器。TrAdaBoost以将源域中有价值的知识传递给目标任务为目标,使用目标域中的少量标记数据来评估源域中数据的可用性。然后,从源数据中提取有价值的辅助数据,并与目标域中的上述标记数据相结合,训练分类器。TrAdaBoost通过将有用的知识从源域转移到目标域,帮助目标域中的学习任务。本研究的主要贡献如下:
- 在新的流量分类任务中,TrAdaBoost提出利用从不同网络流量源中提取的标记流量数据。
- 在TrAdaBoost中,Maxent模型被用作基本分类器。该方法实现了流量知识从源域到目标域的迁移。
- 实验对TrAdaBoost的性能进行了评价。与传统的机器学习方法相比,该方法在目标域内没有足够的标记数据来有效地训练学习模型。
本研究的结构如下。第2节简要介绍了流量分类和迁移学习的相关工作。第3节总结了符号和任务定义。第4节详细介绍了算法。第5节给出了数据集和实验结果。第6部分是对本研究的总结和对未来工作的探讨。
2. 相关工作
近十年来,国内外学者对基于端口的流量分类方法、基于有效载荷的流量分类方法、基于行为的流量分类方法和基于机器学习的流量分类方法进行了大量的研究。大多数方法在几次调查中按时间顺序进行了总结[1,7]。在这些方法中,机器学习方法以其在流量分类任务中的良好性能受到越来越多的关注。Nguyen和Armitage详细回顾了2008年以前基于机器学习模型的相关研究[2]。因此,我们主要回顾了2008年以后基于机器学习方法的研究工作。
用于流量分类任务的机器学习方法分为有监督学习方法、半监督学习方法和无监督学习方法。在有监督的学习方法中,根据生成的应用程序类别人工标记流量,作为标准基准数据集。建立了基于标记流的有监督机器学习模型,其特征是从流中提取统计模式。在训练过程中,通过调整模型参数对新的流量流进行分类。这样,在流量分类中实现了许多模型。Moore和Zeuv[8]提出了贝叶斯方法来识别应用协议。他们进一步提高了精确性,细化了变量。比较了5种有监督模型的分类精度和计算性能,包括带离散化的朴素贝叶斯、带核密度估计的朴素贝叶斯、C4.5决策树、贝叶斯网络和朴素贝叶斯树[9]。Este等人[10]将支持向量机模型(SVMs)应用于三类已知数据集,在相同数据集上获得了平均95%以上的精度,比贝叶斯方法和其他方法的最佳性能高出2.3%。Finamore等人[11]进一步提出了有效载荷的统计特征作为特征,并利用支持向量机进行流量分类。Nguyen等人[12]用一组子流训练ML模型,研究子流选择的各种策略。当流量流与双向流量流混合时,模型的精度将得到保持。Li等人[13]提出了一种启发式规则与REPTree模型相结合的P2P流量分类方法。[14]利logistic回归模型对流进行非凸多任务特征选择分类。他们试过Capped学习作为正则化子的流的特征。Peng等人[15]基于11个著名的有监督学习模型,验证5-7个包是早期流量分类的最佳包数。
对于无监督方法,主要应用于基于聚类的方法。基于聚类的模型自动地将未标记的流量分组成一组簇。利用映射到不同应用程序的集群来训练新的流量模型。使用期望最大化模型对流量进行聚类,并手动将每个集群标记到应用程序中[16]。对k-means、DBSCAN和AutoClass模型进行了验证和总结,结果表明当聚类数量达到一定规模时,聚类方法得到了效果较好的聚类[17]。该方法自动从未识别的流量流中提取标志。但是,集群数量和应用程序数量之间的差异导致了硬映射。为了解决这个问题,Keralapura等人[18]介绍了一种用于P2P流量分类的两阶段自学习结构,该结构利用了流量的时间相关性,识别了P2P流量。Zhang等人[19]利用一个词包模型来表示具有统计特征的聚类内容。然后实现潜在语义分析,以有效负载内容为基础合并相似的集群。Wang等人[20]提出了一种考虑等价集约束和背景知识的约束聚类框架,并利用高斯混合密度对数据进行建模。
在半监督学习方法中,学习模型利用未标记流来增强初始监督学习模型。在半监督学习模型中,选择有标记流和无标记流以获得更好的学习精度。应用一组标记流将集群映射到实际应用程序[21]。基于子空间聚类、证据积累和层次聚类的结合,提出了集成聚类方法来改进半监督聚类方法[22]。为了使未知流检测性能更好,Zhang等人扩展了以往的半监督工作,分别利用了复合分类模型、基于最近邻(NN)的模型和流袋模型中的相关信息[23]。
不同类型的学习模式用不同的假设处理不同的问题。但上述方法都是基于iid假设的,在实际应用中往往不能满足。为了解决上述问题,提出了在训练数据和测试数据不完全相同的情况下进行迁移学习的方法。Dai和Yang[6]提出了迁移学习模型,并在UCI机器学习库的三个文本数据集和一个非文本数据集上验证了该模型的有效性。Pan和Yang[4]根据迁移学习的不同定义、源域与目标域、源任务与目标任务的不同条件,将迁移学习分为归纳迁移学习、导入迁移学习和无监督迁移学习三种类型。Lu等人[24]在调查报告中总结了几种迁移学习方法及其应用。近年来,迁移学习已成功地应用于计算机视觉、图像处理、生物学、自然语言处理和文本数据挖掘等领域。
3. 问题表述
流量分类的目的是将每个流映射到网络中的应用程序协议。传统的用于流量分类任务的机器学习方法实现了由从原始流量流中提取出来的训练集 ( X t r a i n , Y t r a i n ) = { ( x 1 , y 1 ) ( x 2 , y 2 ) . . . ( x n , y n ) } (X_train, Y_train) = \{(x_1, y_1)(x_2, y_2)...(x_n, y_n)\} (Xtrain,Ytrain)={(x1,y1)(x2,y2)...(xn,yn)}训练流量分类器。然后分类器识别测试数据集 X t e s t X_{test} Xtest的实例。有一个共同的假设, X t r a i n 和 X_{train}和 Xtrain和X_{test}是从相同的特征空间和相同的分布下提取的。为了识别来自不同领域的新的流量数据,必须使用来自同一领域的数据对原始流量分类器进行重新训练。

迁移学习不需要上述假设。迁移学习和传统的机器学习方法的比较如图1所示。
给定一个或多个源域 D s D_s Ds和任务 T s T_s Ts,对应于一个或多个流量和流量分类任务的原始标记数据集,一个目标域 D t D_t Dt和任务 T t T_t Tt,对应于来自不同网络环境的新流量分类任务,迁移学习的目的是利用 D s D_s Ds和 T s T_s Ts( D s ≠ D t o r T s ≠ T t D_s \neq D_t \quad or \quad T_s \neq T_t Ds=DtorTs=Tt )的知识,提高 D t D_t Dt中的目标预测函数 h t h_t ht的学习能力。如果标记训练数据 T b T_b Tb的个数不足以训练出满意的 D t D_t Dt学习模型,则引入标记 D s D_s Ds的训练数据 T a T_a Ta作为辅助数据训练 D t D_t Dt学习模型。虽然 T a T_a Ta已经过时,但它不应该被舍弃,因为标记流量数据很昂贵。在本研究中,我们以一个来源的 D s D_s Ds中的 T a T_a Ta和少量的 D t D_t Dt中的 T b T_b Tb作为训练数据T来训练一个学习模型,其中 D s D_s Ds中的知识被迁移。然后训练模型将新的流分类为测试数据。
4. 方法
TrAdaBoost是2007年由Dai等人[6]提出的,它是基于迁移学习思想的AdaBoost方法的一个改进版本。他们的实验使用了 T a T_a Ta和 T b T_b Tb的一部分( T b ≤ T a T_b \leq T_a Tb≤Ta)作为训练数据,用 T b T_b Tb的另一部分作为测试数据。TradaPost通过更新样本权重来减少来自 T a T_a Ta的“坏”数据的权重,这对于 D t D_t Dt中的测试数据的识别是无用的。
在AdaBoost训练的迭代过程中,如果样本分类不正确,模型在下一次迭代中通过增加样本的权重来更加关注样本。如果样品分类正确,它的权重就会减少。相比之下,在传统的训练中,如果 D s D_s Ds样本分类错误,它将与 D t D_t Dt中的数据不同,其权重将降低。在下一次迭代中,将减少样本的影响。如果 D t D_t Dt中的样本分类错误,其权重将增加。模型在下一次迭代中将更加关注样本。TradaPost的训练过程如图2所示。

在本研究中,TrAdaBoost作为一个学习框架解决多类网络流量分类问题。许多机器学习模型适合作为基本分类器。本研究以Maxent为基础分类器。基于TradaBoost的流量分类描述如下(算法1)。

在步骤1中, T a T_a Ta和 T b T_b Tb合并为训练数据集T。初始化样本 W 1 W^1 W1的权重(n是 T a T_a Ta的样本数,m是 T b T_b Tb的样本数)。在第二步中, β t \beta_t βt是每次迭代的模型因子,根据n和N初始化。在步骤3中, P t P^t Pt是T的权重分布,由 W t W^t Wt决定。在每一次迭代中,首先以 P t P^t Pt的概率选取训练样本,因此 P t P^t Pt决定了当前迭代中样本权重对模型训练的影响。然后利用所选训练样本建立Maxent模型作为基本分类器。在分类假设 h t h_t ht:X->Y中,误差率 ε t \varepsilon_t εt是基于 T b T_b Tb及其权重 W i t W_i^t Wit计算的。 β t \beta_t βt和 W i t W_i^t Wit将根据新的错误率进行更新。之后,如果 T a T_a Ta中的样本分类错误,其权重将乘以 β ∣ h t ( x i ) − c ( x i ) ∣ ∈ [ 0 , 1 ] \beta^{\mid h_t(x_i)-c(x_i)\mid}\in [0, 1] β∣ht(xi)−c(xi)∣∈[0,1],以根据Hedge ( β ) (\beta) (β)理论减少样本权重[26,27]。如果 T b T_b Tb中的样本分类不正确,其权重将乘以 β − ∣ h t ( x i ) − c ( x i ) ∣ \beta^{-\mid h_t(x_i)-c(x_i)\mid} β−∣ht(xi)−c(xi)∣,以增加样本权重。在下一次迭代中,新的基本分类器将更加关注这个样本。每次迭代后,TrAdaBoost的超平面变得更接近目标域 D t D_t Dt。目标域中的样本将得到更好的识别。模型权重 l n ( 1 / β t ) ln(1/\beta_t) ln(1/βt)与每个基本分类器一起存储。最终的结果是基于每个分类器的权重之和。采用测试数据S评估TrAdaBoost的性能。
5. 实验和分析
5.1 数据集
本文利用剑桥大学Nprobe项目的流量数据对该方法进行了性能评价。该数据集在流量分类中得到了广泛的应用,如Moore和Zuev的基于贝叶斯方法的实验[8]。他们提出了业务流的各种特征,包括包长度、包间隔和从业务流中获得的信息。整个数据集包含11个子集,例如条目1-10和条目12,如表1所示。条目1–10是在一天中的不同时间收集到的。条目12和其他10个数据集不相同,因为条目12是在12个月后收集的,并且网络环境发生了变化。数据集包括12个应用类,包括WWW, MAIL, FTP-CONTROL, FTP-PASV, FTP-DATA, P2P, DATABASE, SERVICES, ATTACK, MULTIMEDIA, INTERACTIVE
and GAMES。由于不是所有类别都有足够的流量样本,所以在实验中选择了六个类别,包括WWW、MAIL、DATABASE、FTP-DATA、P2P、SERVICES。
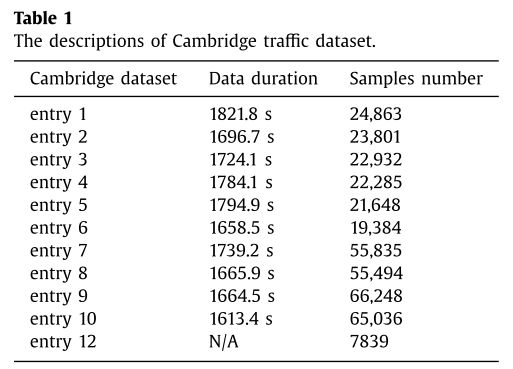
数据集中的每个样本包含248个特征和一个类标签。一些特征在提高分类精度方面起着最小甚至是负面的作用[8]。为了降低特征维数,采用一致性算法结合贪婪搜索策略进行特征选择。选择了9个特征,如表2所示。然后,将条目1-4的数据集合并为 T a T_a Ta,减少了WWW和EMAIL的数量,避免了不平衡数据的影响。条目12分为 T b T_b Tb和S。 T a T_a Ta与 T b T_b Tb之比大于35。数据集应用于实验,如表3所示。


5.2 实验设置
利用两种基于Maxent的传统机器学习方法作为流量分类的比较方法。一个叫NoTL( T a T_a Ta)。Maxent被实现用来训练 D s D_s Ds中 T a T_a Ta的分类器。另一种叫做NoTL( T a + T b T_a + T_b Ta+Tb)。Maxent也被用来训练带有 T a T_a Ta和 T b T_b Tb的分类器。
用于评估流量分类有效性的主要指标是准确性,即正确分类的流量流占总流量流的百分比[28]。需要得到整个测试数据集和每个类的准确度。
5.3 实验结果
在传统的分类算法中,基本分类器的数目对分类性能至关重要。尝试不同数量的基本分类器,如图3所示。
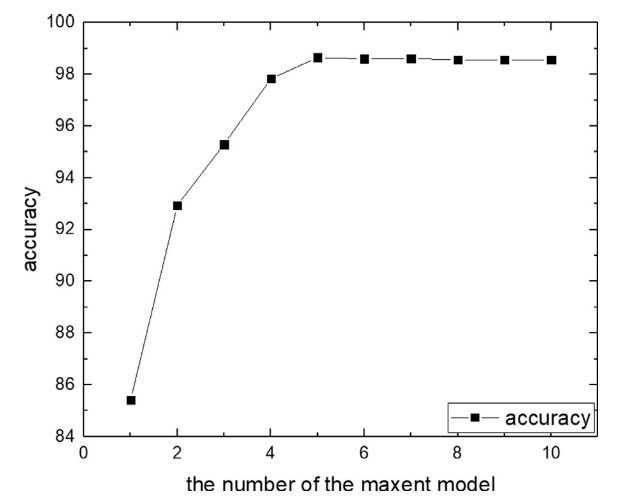
当Maxent数为5时,TrAdaBoost的性能最好。之后,模型有时侯会降低性能,因为正如一些研究所指出的那样,它并不总是降低泛化误差。
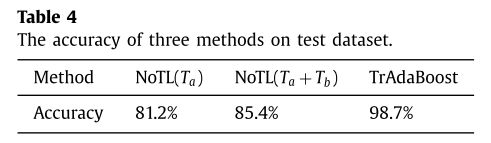
三种方法的结果如表4所示。TrAdaBoost在精度上优于比较方法。基于迁移学习模型,系统的整体性能大大提高。在表5中,分别显示了每个类的精度。在每一个类别中,迁移学习法也比比较学习法表现得更好。由于WWW和MAIL类有足够的数据训练分类器,NoTL( T a T_a Ta)方法在训练数据集和测试数据集不完全相同的情况下,分别达到了86.8%和86.2%的准确率。在训练数据集中加入 T b T_b Tb,NoTL( T a + T b T_a + T_b Ta+Tb)方法的准确率分别为93.7%和94.6%。原因是 T b T_b Tb和测试数据集是相同的。这更好地描述了测试数据集的特性。不过,TradaBoost的表现要好得多。其他4个类的准确性提高更为明显,因为样本较少的类容易受到训练样本分布的影响。TradaBoost保留的训练样本在很大程度上有助于新的分类任务,无论样本是属于 T a T_a Ta还是 T b T_b Tb。此外,当 T b T_b Tb太少而无法训练出满意的分类器时,它将有用的知识从源域 D s D_s Ds转移到目标域 D t D_t Dt。
6. 结论和未来工作
网络环境的变化导致基于传统机器学习模型的流量分类性能下降。在流量分类中,利用多类任务代价将源域的知识转移到目标域。采用Maxent模型作为基本分类器。在应用该方法的基础上,新的数据集达到了较高的分类精度。新数据集和大多数训练数据集不相同。
在未来的研究中,我们将更多地致力于将迁移学习模型应用到分类问题中,例如,当源域和目标域具有不同的类标签时,如何进行分类。