基于KMeans聚类算法的网络流量分类预测
温馨提示:文末有 CSDN 平台官方提供的学长 Wechat / QQ 名片 :)
1. 项目简介
网络流量分类或网络流量异常检测,采用基于聚类的机器学习算法,实现异常检测与分类,即划分为正常流量和异常流量。 数据集来源自 KDD CUP,该数据集是从一个模拟的美国空军局域网上采集来的 9 个星期的网络连接数据, 分成具有标识的训练数据和未加标识的测试数据。测试数据和训练数据有着不同的概率分布, 测试数据包含了一些未出现在训练数据中的攻击类型, 这使得入侵检测更具有现实性。本项目利用 pandas + Matplotlib + seaborn + sklearn 对网络流量数据进行统计分析,并构建聚类算法实现对流量的分类建模。
2. 功能组成
基于聚类方法的网络流量分类的主要功能包括:

3. 工具包导入和数据读取
import warnings
warnings.filterwarnings('ignore')
import os
import gc
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
from IPython.display import display
np.random.seed(7)
plt.style.use('seaborn')
from tqdm import tqdm
import requests
from bs4 import BeautifulSoup
import json
import time利用 pandas 完成数据集的读取,并将 attack_ type 进行类型转换:
data_df = pd.read_csv('data/kddcup.data_10_percent', sep=',', error_bad_lines=False, header=None)
def transform_target(attack_type):
attack_type = attack_type[:-1]
if attack_type == 'normal':
return attack_type
elif attack_type not in {'smurf', 'neptune'}:
return 'attack'
else:
return 'None'
data_df['attack_type'] = data_df['attack_type'].map(transform_target)
data_df = data_df[data_df['attack_type'] != 'None']| duration | protocol_type | service | flag | src_bytes | dst_bytes | land | wrong_fragment | urgent | hot | ... | dst_host_srv_count | dst_host_same_srv_rate | dst_host_diff_srv_rate | dst_host_same_src_port_rate | dst_host_srv_diff_host_rate | dst_host_serror_rate | dst_host_srv_serror_rate | dst_host_rerror_rate | dst_host_srv_rerror_rate | attack_type | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 34669 | 0 | tcp | http | SF | 276 | 2729 | 0 | 0 | 0 | 0 | ... | 255 | 1.00 | 0.00 | 0.25 | 0.01 | 0.0 | 0.0 | 0.0 | 0.0 | normal |
| 146619 | 2472 | udp | other | SF | 147 | 105 | 0 | 0 | 0 | 0 | ... | 1 | 0.00 | 0.87 | 0.98 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | normal |
| 29842 | 0 | tcp | http | SF | 219 | 1434 | 0 | 0 | 0 | 0 | ... | 255 | 1.00 | 0.00 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | normal |
| 136719 | 0 | tcp | http | SF | 327 | 274 | 0 | 0 | 0 | 0 | ... | 224 | 0.88 | 0.02 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | normal |
| 23970 | 0 | tcp | http | SF | 217 | 626 | 0 | 0 | 0 | 0 | ... | 255 | 1.00 | 0.00 | 0.00 | 0.00 | 0.0 | 0.0 | 0.0 | 0.0 | normal |
4. 数据探索式可视化分析
由于数据集太大,我们根据数据类型将数据集分为三部分(object、integer、float)并进行分析。在41个固定的特征属性中,9个特征属性为离散型,其他均为连续型。通过对41个固定特征属性的分析,比较能体现出状态变化的是前31个特征属性,其中9个离散型,22个连续型。因此对连接记录的分析处理是针对该31个特征属性。接下来将这31个特征属性进行总结分析。
4.1 攻击类型 attack_type
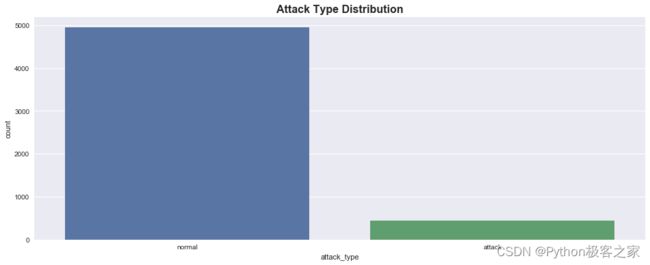
可以看出,有97277个正常样本,8752个攻击样本,占8.2%,标注样本极不平衡,攻击类型的样本太少,为验证聚类模型的效果,考虑将其合并为一种其他攻击类型。
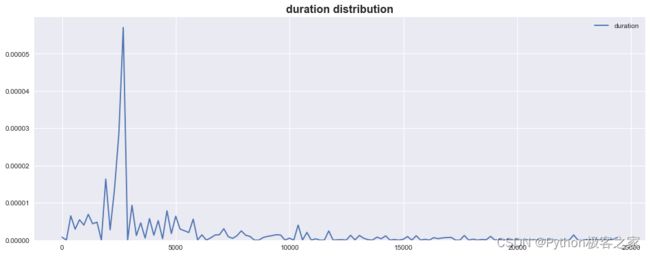
4.2 连续记录的时间长度 duration
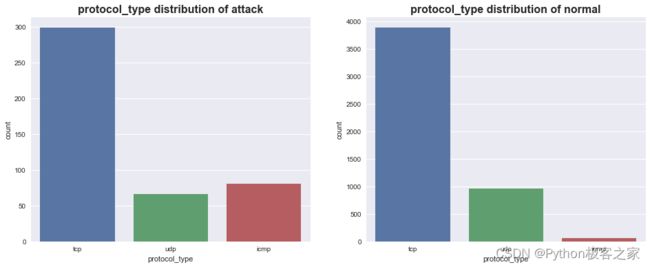
 4.3 协议类型 protocol_type
4.3 协议类型 protocol_type
4.4 目的端的服务类型 service
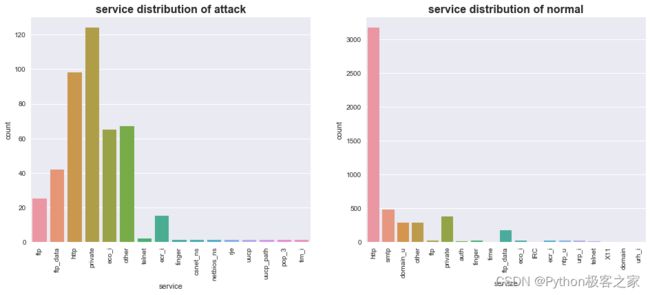 4.5 连接是错误或正常状态 flag
4.5 连接是错误或正常状态 flag
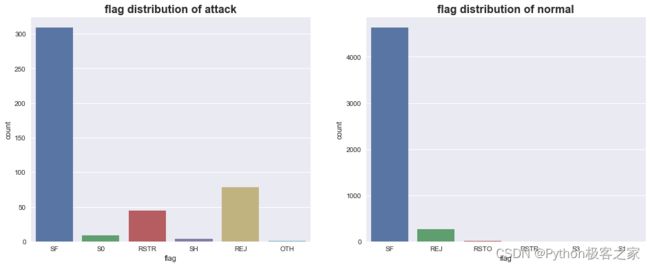
4.6 源端发送到目的端的字节数的字节数 src_bytes
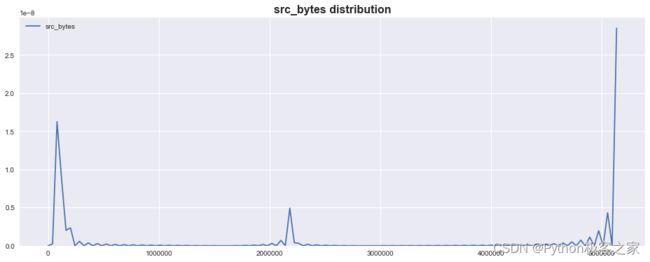 4.7 访问系统敏感文件和目录的次数 hot
4.7 访问系统敏感文件和目录的次数 hot

5. 特征工程
5.1 类别特征编码
特征工程之前,先查看各列或特征在数据集中的不同值的个数,以梳理哪些是数值类型哪些是类别类型的特征。
# 查看各列或特征在数据集中的不同值的个数
for column in data_df.columns:
print(len(set(data_df[column])), ':', column)聚类算法中要使用计算距离的方法对数据进行聚类, 而连接记录的固定特征属性中有两种类型的数值: 离散型和连续型。 对于连续型特征属性, 各属性的度量方法不一样。
针对类别型特征,进行 LabelEncoder 编码:
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
# 字符串类型的特征进行 LabelEncode 编码
data_df['protocol_type'] = le.fit_transform(data_df['protocol_type'])
data_df['service'] = le.fit_transform(data_df['service'])
data_df['flag'] = le.fit_transform(data_df['flag'])
data_df['attack_type'] = data_df['attack_type'].map(lambda x: int(x == 'attack'))
target = data_df['attack_type']
del data_df['attack_type']5.2 特征归一化处理
数据的量纲不同,数量级差别很大,经过标准化处理后,原始数据转化为无量纲化指标测评值,各指标值处于同一数量级别,可进行综合测评分析。
如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。
# 最大值-最小值归一化
scaler = preprocessing.MinMaxScaler()
data_df = scaler.fit_transform(data_df)5.3 TSNE 降维可视化
plt.figure(figsize=(20, 8))
plt.scatter(data[target == 1][:, 0], data[target == 1][:, 1], label='1: attack', color='red')
plt.scatter(data[target == 0][:, 0], data[target == 0][:, 1], label='0: normal')
plt.legend()
plt.show()
6. KMeans 无监督聚类模型实现异常检测
6.1 数据集拆分
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 划分测试集
train_x, test_x, train_y, test_y, tsne_train, tsne_test = train_test_split(data_df, target.values, data, test_size=0.1, random_state=42)
print('训练集:{}, 测试集: {}'.format(train_x.shape[0], test_x.shape[0]))训练集:4819, 测试集: 5366.2 KMeans 聚类模型
from sklearn.cluster import KMeans
# 创建 KMeans 模型
kmeans_model = KMeans(n_clusters=2, random_state=42)
# 训练 kmeans 模型
kmeans_model.fit(train_x)
# 训练集预测
pred_trains = kmeans_model.predict(train_x)
# 测试集预测
pred_tests = kmeans_model.predict(test_x)
print('训练集正确率:{:f},精确率:{:f},召回率:{:f},F1-Score:{:f}'.format(
accuracy_score(pred_trains, train_y),
precision_score(pred_trains, train_y),
recall_score(pred_trains, train_y),
f1_score(pred_trains, train_y))
)
print('测试集正确率:{:f},精确率:{:f},召回率:{:f},F1-Score:{:f}'.format(
accuracy_score(pred_tests, test_y),
precision_score(pred_tests, test_y),
recall_score(pred_tests, test_y),
f1_score(pred_tests, test_y))
)训练集正确率:0.818220,精确率:0.539043,召回率:0.235943,F1-Score:0.328221
测试集正确率:0.847015,精确率:0.714286,召回率:0.339806,F1-Score:0.460526 测试集预测结果绘图: 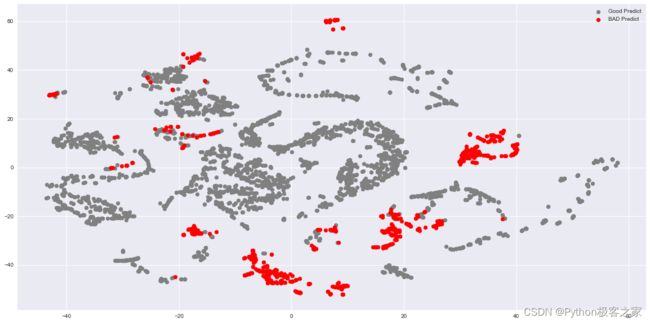
红色的为预测错误的样本,灰色的Wie预测正确的样本,可以看出,单纯的 KMeans 模型的测试集 F1-Score 只有 0.334297,模型存在提升空间!
6.3 模型优化
本项目基于随机森林算法进行特征选择:
......
train_probs = clf.predict_proba(train_x)
test_probs = clf.predict_proba(test_x)
train_probs = np.reshape(train_probs[:, 0], (train_probs.shape[0], 1))
test_probs = np.reshape(test_probs[:, 0], (test_probs.shape[0], 1))
feature_importances = pd.DataFrame({'features': feature_names, 'important': clf.feature_importances_})
feature_importances.sort_values(by='important', ascending=False)
# 去掉特征主要程度低的特征
good_features = feature_importances['features'].values[:10]特征筛选后,重新训练 kmeans 聚类算法:
print('训练集正确率:{:f},精确率:{:f},召回率:{:f},F1-Score:{:f}'.format(
accuracy_score(pred_trains, train_y),
precision_score(pred_trains, train_y),
recall_score(pred_trains, train_y),
f1_score(pred_trains, train_y))
)
print('测试集正确率:{:f},精确率:{:f},召回率:{:f},F1-Score:{:f}'.format(
accuracy_score(pred_tests, test_y),
precision_score(pred_tests, test_y),
recall_score(pred_tests, test_y),
f1_score(pred_tests, test_y))
)训练集正确率:0.925711,精确率:0.765743,召回率:0.534271,F1-Score:0.629400
测试集正确率:0.917910,精确率:0.591837,召回率:0.547170,F1-Score:0.568627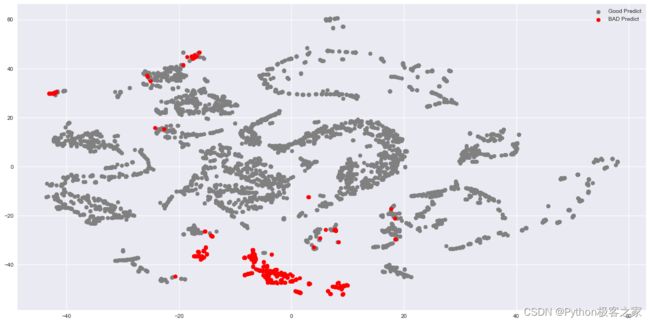
可以看出,经过特征选择后,测试集的预测 F1-Score 从 0.460526 提升到 0.568627,同时由于特征维度的降低,运行速度也加快!
7. 结论
网络流量分类或网络流量异常检测,采用基于聚类的机器学习算法,实现异常检测与分类,即划分为正常流量和异常流量。 本项目利用 pandas + Matplotlib + seaborn + sklearn 对网络流量数据进行统计分析,并构建聚类算法实现对流量的分类建模。
欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
技术交流认准下方 CSDN 官方提供的学长 Wechat / QQ 名片 :)
精彩专栏推荐订阅:
1. Python 毕设精品实战案例
2. 自然语言处理 NLP 精品实战案例
3. 计算机视觉 CV 精品实战案例
