Raft相关问题思考
1.各个容错系统中有什么公用的模式?
都需要一个关键实体来主管全局,做出决策。
其中MapReduce需要一个master实体安排数据分批进入计算,GFS需要一个master实体安排数据存储,Raft也需要一个leader来进行日志复制。
2.什么是“裂脑”问题?
计算机无法分辨另一台计算机是网络连接出现错误还是宕机下线了,对它而言都是尝试网络连接失败。两个节点互相认为对方已挂掉,然后开始争抢共享资源,结果会导致系统混乱,数据损坏。这就是裂脑问题。
3.处理裂脑问题的方案?
使用大多数投票。大多数投票依赖于集群内节点数量是奇数,所有操作要来自大多数节点的共识。
大多数投票为什么起作用?假如产生裂脑后,只有一方拥有大多数,同时奇数节点也打破了平衡。(这里的大多数指的是所有节点的大多数,不是当前检测到活着的大多数。而且2f+1个节点可以容忍f个节点宕机,剩下f+1个节点仍然可以凑足大多数)
4.一个Raft集群处理客户端请求的流程是怎么样的?
(1)client向集群的leader发送一个PUT/GET命令
(2)leader添加命令到自己的日志
(3)leader发送AppendEntries RPCs到followers
(4)followers添加命令到自己的日志
(5)leader等待集群内大部分followers的回应(如果一条记录被大多数节点放在logs中就进入commit状态,commit意味着如果产生错误也不能被删除的日志)
(6)leader执行命令,回复客户端
(7)leader 在下一个AppendEntries RPCs中通知commit信息
(8)followers执行leader已经committed的日志
5.为什么需要日志,每个节点收到指令后直接在状态机上不行吗?
(1)日志可以将命令按顺序排好。帮助所有节点共同确定一个执行顺序,帮助leader确认每个followers有相同的日志。
(2)日志暂时存储了commit之前不确定的命令。
(3)日志存储命令后leader就不用每次发送重复的日志。
(4)日志持久化存储了命令可以再重启后恢复。
6.每个节点上的日志都相同吗?
不相同,日志在同步复制的时候可能会暂时存在差异。但最终会被同步成相同的,commit机制会保证最终执行的是稳定的命令序列。
7.Raft设计中的接口有哪些?
单纯Raft其实是集群内节点的底层实现协议,能够确保集群内节点以相同的顺序执行相同的指令。Raft包装好了接口以供上层调用。其中包括接口:
rf.Start(command) (index,term,isLeader):只有leader能调用Start()接口,用于接收KV层发来的Put()/Get()RPC后,在leader日志中添加了一条新的指令,然后同步到其他follower上去。KV层必须等到applyCh上的commit信息,因为在leader commit之前可能会因为丧失领导权导致同步失败,这时需要client重发请求。
8.Raft设计主要包括哪两部分?
(1)选举一个新leader
(2)在存在宕机节点的情况下保持同步复制的正确性
9.为什么需要一个leader?
确保所有节点以同样的顺序,执行同样的命令。(一些其他共识算法的设计没有leader,比如paxos)
10.Raft如何标识不同的leader?
每产生一个新的leader,就开始一个新的term,用term变量来标识每一次选举,一个term最多有一个leader,也有可能没有leader(在规定的时间内没有选出leader)。term这样的自增长数字有助于所有节点追随最新的leader,而不是过时的leader。
11.什么时候Raft的节点会进行一场leader选举?
当节点没有在election timeout这段时间内收到当前leader发送的信息,就决定开始一场选举。将自己的currentTerm增长1,转为Candidate开始拉票。这样的措施可能会降低性能,可是会提升安全性。此时老的leader可能仍然活着并认为自己是leader。
12.如何确保一个term内最多只有一个leader?
一个leader想要当选必须要得到集群内大多数节点的投票,一个节点在一个任期内最多投出一票(如果是Candidate节点,给自己投票,如果是follower,给第一个拉自己票的节点投票)。
在这样的机制下,一个term内最多有一个节点能够得到大多数的投票,即使此时集群内产生了隔离,即使集群内有些机器下线了。
13.集群内节点如何得知一个新当选的leader?
当一个新leader得到了集群内大多数节点的投票后,知道自己成为leader。
其他follower节点收到新leader的AppendEntries心跳信息(包含更大的term值)后,得知新的leader。
心跳信息会让尝试拉票的Candidate老老实实退回Follower状态。
14.一个选举会失败吗?
有可能失败,失败原因有以下两种:
(1)此时集群内大多数节点的状态是不可达的,也就是无法进行网络通讯。
(2)同时有其他Candidate瓜分了选票,使每个Candidate都无法成功当选。
15.一个选举失败后发生了什么?
等待下一次timeout之后,节点跳出来竞选。有更高term的Candidate在竞选中有更高优先级,term低的Candidate会自动退出。
16.Raft如何避免选票分割?
每个节点选择一个随机的election timeout。(这是为了防止多个Follower同时变成Candidate,分割选票之后,等待同样timeout后再次拉票,就永远不会有成功的选举,这种随机打破了对称性)。其他节点看到新Leader的AppendEntries 心跳信息后不会再成为candidates。
17.如何选择election timeout的长短?
(1)至少需要长于几个心跳定时发送的时间。因为有些心跳信息可能因为网络问题没有到达节点,至少要允许重发的心跳可以到达,这样避免了无意义的重新选举提高了效率。
(2)随机的election timeout时间区间的下限,要足够一个candidate成功竞选。
(3)随机的election timeout时间区间的上限,要短到能够及时发现错误,避免长时间停顿。
(4)要短到让测试的人方便,比如说测试的人希望在5秒内看到一个成功的选举。
18.如果一个老的leader没有意识到新的leader已经产生了会发生什么?
这可能是因为老的leader没有收到新的leader的信息,也有可能老的leader被隔离到了少数派分区中。
新leader的产生意味着集群中大多数节点已经更新到了新的term,所以老的leader没办法从大多数节点获得AppendEntries成功的回应,也无法commit或者执行一个新的指令。这也解决了裂脑问题。
但少数派还是有可能接收老leader新增的日志,所以集群内节点的日志这里会发生分歧。
实际上当老leader收到一个新term节点的AppendEntries回应后,就会知道自己需要退位,这是就转变状态称为Follower。
19.client与哪个节点交互?
当client发起请求的时候,只能和leader节点交互,如果不知道哪个是leader,就随便找一个节点,然后发出请求,如果不是leader节点就会返回leader节点的index。
20.什么是State Machine Safety ?
如果一个节点执行了日志中一连串指令,那么其他节点也保证以同样的顺序执行同样的指令。
为什么要用到State Machine Safety?因为我们希望client交互式,只觉得自己在和一台机器交互,leader在集群内部统领其他节点,这样一个节点的异常或者反对不会被client感知到,这个节点再后续会被更正,这就不是client需要关心的问题了
21.日志在错误状态下会产生怎样的差异?
eg1:leader在成功发送AppendEntries前崩溃:
S1: 3
S2: 3 3
S3: 3 3eg2:更糟糕的是,由于一系列leader崩溃,不同节点的日志可能在同一位置有不同的记录
10 11 12 13 <- log entry #
S1: 3
S2: 3 3 4
S3: 3 3 5Raft强迫各节点向新leader的日志同步:S3被选为term6的新leader;S3向其他节点发送包含了entry13 的AppendEntries,此时prevLogIndex=12,prevLogTerm=5;S2回复日志无法同步;S3将nextIndex[s2]的值降低为12;S3发送包含entries12+13的AppendEntries,此时prevLogIndex=11,prevLogTerm=3;S2删除自己日志的entry 12;S3对S1的操作也是如此,只不过要多退一步。
这种回滚的结果:每一个follower删除与leader不同的日志尾部,之后每一个可用的follower接收leader之后的日志,这样followers的日志会等同于leader的日志。
为什么S2删除 index=12 term=4的记录是ok的?只有没有commit的记录都是可以删除的。
新的leader能够回滚前一个任期已经committed的记录吗?或者说新leader的日志中是否可以遗漏已经committed的日志记录?这是万万不能的,会造成灾难性的后果,因为committed的记录已经向client回复YES了,如果遗漏会造成集群内节点执行状态不统一。所以,Raft需要保证选出的leader日志中包含有所有committed 的记录。
22.为什么不选择日志最长的节点作为leader?
example:
S1: 5 6 7
S2: 5 8
S3: 5 8首先,可能出现这样的状况吗?可能,S1在term6是leader ;崩溃又恢复;在term7再当选leader;崩溃并持久保持下线状态;在两次崩溃前都只在自己的日志中新增了记录;在S1下线后,S2/S3不会选择6做下一个任期,下一个任期会是8,因为S2/S3起码有一个在投票的时候知道当前已经到了term 7;S2在term 8成为leader,只有S2和S3处于活跃状态,之后崩溃。
当所有的节点重新上线后,谁有机会成为leader? 此时S1有最长的日志,但是entry 8 可能已经被committed了,所以新的leader只会在S2和S3中间选出。
选出leader的规则不能知识简单的谁有最长日志。
23.什么是"election restriction"?
就是在选举中的投票规则。followers如果对candidate投票,candidate必须是“最新的”状态,也就是说candidate的last entry term要比follower的last entry term大,candidate有相同的last term 并且日志长度要大于等于follower才会投票。
比如上面的例子中,S2和S3不会给S1投票,但是会给互相投票。之后S2或者S3成为leader,强迫S1丢弃掉6,7记录,因为6,7记录不是大多数节点的公式-->也就是没有提交-->也就造成client没有收到回复-->client之后会重新发起请求。
24.在论文figure 7中,第一个服务器挂掉,剩下哪个可以被选为leader?
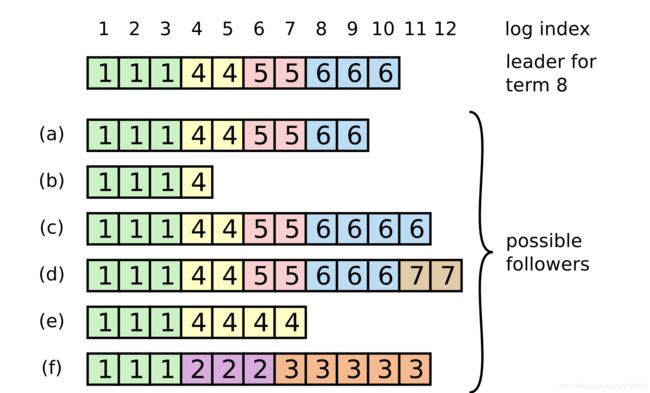
Figure 7中不同的节点被选为leader,不同的记录会被committed或者抛弃掉。
有些肯定会被committed:111445566,它们会被committed + executed + replied 到client
有些肯定会被抛弃:f的2和3
有些可能被抛弃可能被提交:e的最后4,4 ; c的6,6 ;d的7,7;
25.怎样加快回滚速度
Figure2 中设计的回滚策略是每个RPC回滚一个记录,非常慢,可以优化回滚策略
paper outlines a scheme towards end of Section 5.3
no details; here's my guess; better schemes are possible
Case 1 Case 2 Case 3
S1: 4 5 5 4 4 4 4
S2: 4 6 6 6 or 4 6 6 6 or 4 6 6 6
S2 is leader for term 6, S1 comes back to life, S2 sends AE for last 6
AE has prevLogTerm=6
rejection from S1 includes:
XTerm: term in the conflicting entry (if any)
XIndex: index of first entry with that term (if any)
XLen: log length
Case 1 (leader doesn't have XTerm):
nextIndex = XIndex
Case 2 (leader has XTerm):
nextIndex = leader's last entry for XTerm
Case 3 (follower's log is too short):
nextIndex = XLen简而言之就是,不再一个一个记录比较回滚,每次返回的时候携带上一个term的第一个记录,然后来来回回发RPC,按照一个term一个term的开始比较。
26.在节点崩溃后我们希望发生什么?
Raft在一个节点崩溃的情况下可以正常运行,但我们希望有问题的节点再上线后能很快恢复。可以用到两种策略:
(1)第一种:用一个新的(空的)节点代替,这种策略下需要支持把整个日志(或者snapshot)复制到新的节点上去,我们必须支持这种策略,防止有的机器永久下线。
(2)第二种:重启崩溃的节点,以完整的状态重新加入集群,这种策略需要将节点的状态持久化到本地,我们必须支持这种策略,防止有的机器突然断电。
27.如果一个节点崩溃又恢复,那它需要持久化什么?
Figure2 列出了需要持久化的数据:log[] ,currentTerm,votedFor。
一个Raft节点想要重启后重新加入必须保留完整状态,完整状态就是上面的数据保存到不易失的存储设备上,不易失的存储设备包括disk,SSD,battery-backed RAM。
为什么要保存log[] ? 如果一个节点commit了一条记录,再重启后也必须要记住,这是为了未来的leader能看到被提交的日志记录。
为什么需要votedFor?防止一个节点先投票给一个Candidate,之后重启,再在同一个(甚至更老的!!!)任期里再投票一次,这就打破了多数派的原则。
为什么需要currentTerm?需要确保terms只增长,这样每个term至多只有一个leader。还可以用来测试leader和candidate发来的RPC。
28.持久化经常是性能的瓶颈,怎样避免?
(1)每次往硬盘写入的时候写入一批(写一次硬盘10ms)。
(2)持久化到battery-backed RAM,而不是硬盘
29.k/v 节点怎样在 crash+reboot之后恢复KV数据(也就是Raft的状态机执行)?
简单的方式:从空状态开始,重新执行Raft持久化的日志,这就是Figure 2的做法,但是对于存在很长时间的节点,重新执行的时间太长。
更快的方式:用Raft snapshot , 这样只用重新执行整个日志尾端的部分。
30.什么记录是节点不能丢弃的?
还没执行的记录:还没有反映在节点执行状态上。
还没提交的记录:有可能被多数派认可的记录。
31.快照技术是怎么实现的?
Raft利用周期性的snapshot来缩短日志长度,加快节点的恢复速度。在K/V服务中,一次snapshot其实就是将一段日志的执行结果保存到硬盘中的过程,snapshot包括了lastInclude 索引前所有日志的执行结果,之后抛弃掉已经被snapshot过的日志。
设定一个阈值,当日志长度接近一个阈值的时候就做一次snapshot,做snapshot的操作也要当作一次记录,通过leader节点同步到其他所有节点上去。
有了snapshot机制以后,如果出现crash+restart的情况,KVservice从硬盘中读取snapshot,Raft从硬盘中读取持久化日志,service告诉Raft将lastApplied 设为 lastInclued,避免执行已经执行过的记录。
32.如果followers日志的结束比leader的日志开始还大怎么办?
这种情况出现的可能是,一个follower的很早下线,然后leader通过snapshot截掉了较早的部分日志,这样leader不能通过AppendEntries RPC的方式同步日志,需要通过InstallSnapshot来同步日志。
实际上如果raft存储的数据非常大,比如达到gigabytes级别的数据,写入硬盘的速度是非常慢的,这是service的data应该以B-Tree的方式存储在硬盘上,这样不用特意去snapshot,因为已经存储在硬盘上了。(B树的增加和删除节点对于整体的结构来说,改动非常的小,所以十分适合用来作为大数据存储的数据结构。那B+数有什么用呢B+树相对于B树来说,最大的改动就是把存储值的节点全部放在了叶子节点,这样有什么好处呢,我们可以看到,叶子节点最后形成了一个有序的链表。)
33.如果一个客户端PUT/GET RPC超时还没收到回复会怎么样?
Call()调用返回false;
如果服务器挂掉,或者请求丢失掉 ==> 重发
如果服务器执行,但是回复丢失 ==> 重发是危险的
存在的问题:后两种对于client来说看到的一样,都是没有回复,如果已经执行了,client也需要收到执行的结果。如果重发就存在多次执行的可能。
解决办法:做重复RPC的检测,我们让KV service有能力检测是否已经收到过此请求,对于每一个请求client会生成一个ID,在发起请求的时候会把ID包含在RPC中发送给leader,如果leader收到了相同ID的RPC请求就认为是重复的。
34.存储client ID 与结果的表应该怎么设计?
因为每一个节点都要维护一个重复表,所以要设计得尽可能小,减小开销。
为一个client在表中添加一项,而不是一个RPC记录一项。
一个client应该在同一时间内只有一个RPC请求。
每个client的RPC seq number是顺序增加的,当一个节点收到该client的新RPC后,它就替换表项,因为此client上一个RPC肯定已经执行并返回了结果,不会重发RPC请求。
实际实现的一些细节:
(1)每个client需要一个独特的clientID,可能是一个64位随机数字;
(2)client在每个RPC中发送client ID 和 seq number,重发的时候发送重复的seq;
(3)查重表可以设计成以clientID 为键的哈希表,包含seq,如果已经执行就包含返回结果
(4)RPC handler 首先查询查重表,如果seq > 表中标号,才调用start()
35.如果client重复的请求在原请求执行前到达会发生什么?
会再次调用Start(),可能会以同样的clientID同样的seq好出现在日志中,当cmd出现在applyCh中,检查表中是否已经有了,如果有了就不要执行。
36.一个新当选的leader如何获得重复表?
所有的节点应该在执行的时候就更新他们的重复表,这样当一个节点成为leader的时候重复表中的信息是完全的。
37.如果一个节点崩溃了,应该怎么回复重复表?
如果没有snapshots,就重新执行每个日志同时恢复表。如果有snapshot,snapshot内应该保存表的信息。
38.如果表中保存的结果是过期的呢,这样是可以的吗?
example:
C1 C2
-- --
put(x,10)
first send of get(x), 10 reply dropped
put(x,20)
re-sends get(x), gets 10 from table, not 20
what does linearizabilty say?
C1: |-Wx10-| |-Wx20-|
C2: |-Rx10-------------|
order: Wx10 Rx10 Wx20
so: returning the remembered value 10 is correct
39.Raft leader需要在返回read-only操作前一定要将这个操作提交吗,比如Get(key)操作?
也就是说,Get()方法可以通过KV哈希表直接返回结果吗,还是也要写入日志等待同步?
不行,以Figure 2中使用的策略是不行的。加入S1认为自己是leader,并且受到一个Get(k)的请求,它有可能刚刚丧失领导权而不自知(由于网络分割),此时的新leaderS2可能正执行了一条Put语句,那个S1的kv表是过时的,这就是裂脑问题。
但是!!!有些程序访问数据的方式主要是读取,提交Get()s花费了大量的时间,这是不是就要做出一些权衡了?这就要在实际系统中根据需求考虑如何实现。
对于主要读取的程序有什么解决方法吗? leases 租约
修改Raft协议:
- 设置leases 周期,比如说5秒。
- 每次leader完成一次AppendEntries 多数共识以后,就有权利在leases周期内可以不将read-only加入log提交才返回结果,而是直接返回结果。
- 一个新的leader不能执行Put()s方法,知道上一个leases周期过期。
- 所以followers需要记住上一次回应AppendEntries的时间,并在RequestVote reply中告知新leader。
这样可以加速read-only操作的速度,同时维持串行化。
在实际实现中,人们往往愿意用偶尔的过时信息来换取高性能。
40.Figure2中实现的细节有哪些?
(1)对于AppendEntries RPC:
- Reply false if term < currentTerm;
- Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm;
- If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it;
- Append any new entries not already in the log;
- If leaderCommit > commitIndex, set commitIndex = min(leaderCommit, index of last new entry)
(2)对于RequestVote RPC:
- Reply false if term < currentTerm
- If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote
(3) Persistent state on all servers:
- currentTerm:latest term server has seen (initialized to 0 on first boot, increases monotonically)
- votedFor:candidateId that received vote in current term (or null if none)
- log[]:log entries; each entry contains command for state machine, and term when entry was received by leader (first index is 1)
(4)Rules for All Servers:
- If commitIndex > lastApplied: increment lastApplied, apply log[lastApplied] to state machine.
- If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower.
(5)Rules for Followers:
- Respond to RPCs from candidates and leaders.
- If election timeout elapses without receiving AppendEntries RPC from current leader or granting vote to candidate:convert to candidate.
(6)Rules for Candidates:
- On conversion to candidate, start election: Increment currentTerm ; Vote for self ; Reset election timer ; Send RequestVote RPCs to all other servers.
- If votes received from majority of servers: become leader.
- If AppendEntries RPC received from new leader: convert to follower.
- If election timeout elapses: start new election.
(7)Rules for Leaders:
- Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server; repeat during idle periods to prevent election timeouts.
- If command received from client: append entry to local log, respond after entry applied to state machine.
- If last log index ≥ nextIndex for a follower: send AppendEntries RPC with log entries starting at nextIndex. If successful: update nextIndex and matchIndex for follower;If AppendEntries fails because of log inconsistency: decrement nextIndex and retry.
- If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, and log[N].term == currentTerm:set commitIndex = N.
41.Figure 8 的问题如何解决?

Figure8 中的问题是,存储在大多数节点上的日志还是有可能被覆盖,也就是committed记录也有可能被丢掉。解决办法就是leader只commit自己这个term里的记录,不能commit之前term里的记录。